Amazon DynamoDB 正迅速成为世界上发展势头最强劲的游戏数据库。《水果忍者》(由 Halfbrick 工作室开发)、《战斗营地》(由 PennyPop 开发)等游戏都充分利用 Amazon DynamoDB 的一键式扩展性功能,支撑游戏高速的发展,为全球数百万玩家提供服务。Amazon DynamoDB 还得到包括 Supervillain 工作室在内的众多开发人员的赞赏,该工作室的知名作品包括《塔炮战争》与《特隆:进化》。
在今天的文章中,大家将了解 Amazon DynamoDB 如何帮助大家为自己的移动游戏快速建立起可靠且极具可扩展性的数据库层。我们将分步剖析设计示例并了解如何以每天不足一杯咖啡钱的成本为游戏提供弹性资源支持。我们还将模拟一家快速发展的客户,观察 Amazon DynamoDB 如何在时间与成本效率的前提下将玩家支持规模扩展至数百万之巨。
数据库层的重要性
在为规模化应用程序设计架构时,一大关键性因素在于数据库层。这一点对于游戏尤为重要,毕竟属于写入密集型应用。游戏数据会随着玩家收集道具、击败敌人、获取金币、角色升级以及完成成就而不断更新。每一个事件都必须被写入到数据库层,从而保证内容不会丢失。可以想见,一旦进度损坏玩家将变得极为暴躁。
游戏与 Web 应用开发人员通常会使用 MySQL 等开源关系型数据库作为自己的数据库层,这是因为此类方案更为人们所熟悉。遗憾的是,以 MySQL 为代表的关系型技术方案在开发之初更多考虑到的是高强度读取工作负载,而这种机制并不太适合游戏、社交媒体应用以及图片分享站点。有鉴于此,NoSQL 解决方案应运而生,它利用强大的写入数据吞吐能力与横向扩展能力替代了传统关系型数据库在查询灵活性领域的优势。
Amazon DynamoDB 适合游戏开发人员需求的三个理由
Amazon 包揽运营任务。
开发游戏本身就很累人,对吧?Amazon DynamoDB 是一项托管服务,其中包含全方位运营支持以及多数据中心高可用性。大家用不着再为软件安装、硬件故障处理或者性能表现调整而烦心。只需调用单一 API,大家就能对 Amazon DynamoDB 进行动态缩放。
每一个 Amazon DynamoDB 数据库表都与数据吞吐能力密切相关。大家可以将每秒写入操作设定为 1000 次,而 Amazon DynamoDB 会处理全部后台数据库调整工作。根据用户需求的变化,大家可以更新该容量,Amazon DynamoDB 则会依要求完成资源重新分配。这种弹性能力对于游戏开发者帮助巨大:当游戏推出之后,大家可能需要在短时间内将玩家支持规模由数千位增加到数百万位。同样重要的是,大家可以快速调低资源规模——这种调整对于 MySQL 数据库来说颇具挑战。
无论游戏玩家规模如何变动,性能表现都将保持稳定。
Amazon DynamoDB 可在任意规模水平下保持可预测、低延迟性能表现。如果大家的游戏对于延迟较为敏感、并且需要面对数百万玩家,那么这种特性将变得至关重要。使用 Amazon DynamoDB,大家不必再为性能调整浪费任何精力。
在 Amazon DynamoDB 中保存游戏数据
我们不妨想象一下,大家希望创建一款角色扮演游戏。游戏设计遵循常见机制:与怪兽战斗、收集战利品并进行角色升级。在这种情况下,各位显然需要保存用户的当前进度,这时我们应该为每位玩家创建一个键 - 值对配置文件,其中包括现有道具、角色等级以及赚得金币的数量。大家的数据结构可能如下所示:
{
``player_id: ``3612458``,
``name: “Gunndor”,
``class``: “thief”,
``gold: ``47950``,
``level: ``24``,
``hp_max: ``320``,
``hp_current: ``292``,
``mp_max: ``180``,
``mp_current: ``180``,
``xp: ``582180``,
``num_plays: ``538``,
``last_play_date: ``"2014-06-30T16:27:39.921Z"
}
在这个示例中,player_id 应该是个独特的值。将其与 MySQL 等关系型数据库相映射非常简单:为每个键创建一个列。这种方式当然可行,但对结构中的每一列进行解析及检索将给数据库带来沉重负担,而且主键(即 player_id)几乎每时每刻都要接收查询请求。很明显,大家不太可能利用玩家的记录点位置或者经验值进行记录查询。
好的,下面来看将其映射至 Amazon DynamoDB 会发生什么。在 Amazon DynamoDB 当中,我们只需要定义需要进行检索的列即可。在这种情况下,我们将创建出单一散列键作为主键,并借由 player_id 的独特性利用它实现记录查询。我们会定义一套名为“player_profiles”的表,并为“player_id”设定散列键。下面来看 Python 语言编写的示例:
player_profiles ``=``Table.create(‘player_profiles', schema``=``[
``HashKey(``'player_id'``, data_type``=``STRING)
], throughput``=``{
``'read'``: ``5``,
``'write'``: ``5``,
},
我们已经创建了一套包含 5 个读取容量单位与 5 个写入容量单位的表,其被包含在 AWS Free Usage Tier 当中。大家也可以利用 AWS 管理控制台创建这套表。如果不知道该如何操作,请点击此处查看指导信息。
该表创建完成之后,我们的配置文件将如下所示:
player_profiles.put_item(data``=``{
``'player_id'``: ``'3612458'``,
``'name'``: ``'Gunndor'``,
``'class'``: 'thief’,
``...
})
profile ``=``player_profiles.get_item(player_id``=``'3612458'``)
这只是 Python 环境下的示例,大家也可以使用任何 AWS SDK 以 put/get Amazon DynamoDB 中的键。
主键值
关系型数据库使用自动递增的整数,其典型会被作为主键。在规模化场景下,自动递增的主键往往会成为性能瓶颈,因此 Amazon DynamoDB 等 NoSQL 并不会将其进行保存。那么我们该如何生成独特的 player_id 值呢?我们使用 UUID,由于 UUID 的内容彼此不同、因此不同客户端总会生成独立的相应数值。UUID 能够为我们生成相当长的字符串,例如 a8098c1a-f86e-11da-bd1a-00112444be1e。UUID 与 Amazon DynamoDB 匹配效果极好,这是因为它有助于确保主键的随机分布与访问、从而让 Amazon DynamoDB 始终拥有良好的性能表现。
生成 UUID 非常简单:
player_id ``=``uuid.uuid1()
player_profiles.put_item(data``=``{
``'player_id'``: player_id,
``'name'``: ``'Gunndor'``,
``'class'``: ``'thief'``,
``...
``})
原子递增
除了 put 与 get,Amazon DynamoDB 还支持原子递增。这种机制在值发生变化之后的更新流程中非常实用,因为来自应用程序的多项请求不会出现冲突——正是此类状况引发了在线游戏中的大部分进度丢失问题。如果玩家拾取到 100 金币,大家可以直接要求 Amazon DynamoDB 自动将 100 金币增量以原子化方式进行添加,而无需经历获取记录、添加金币再将其返回 Amazon DynamoDB 的过程。
选择合适的容量水平
Amazon DynamoDB 允许大家指定自己所需要的数据吞吐能力容量。但如果大家不清楚这一水平该怎么办?当大家开始游戏开发时,先创建自己的第一套表(例如 5 个写入容量单位与 10 个读取容量单位)。随着流量的增长,我们可以在 Amazon DynamoDB 控制台中利用 CloudWatch 图形监控使用情况并作出调整。
Dynamic DynamoDB 是另一款实用性工具,这是一套开源库、旨在帮助我们对表容量进行自动扩展。我们的客户之一 tadaa 公司利用 Dynamic DynamoDB 在流量水平下降时及时调整资源、从而控制成本支出。
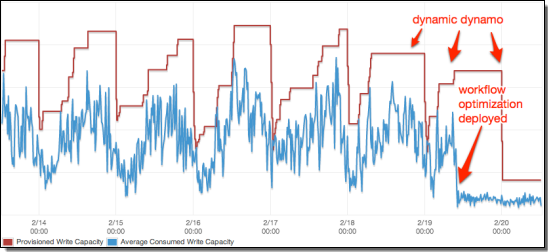
我们真能用每天一杯咖啡的成本为数千玩家提供支持吗?
是的!我们利用保存游戏这个例子来估算成本。假设游戏每个月平均玩家数量为 10 万名,其中大部分玩家并不会在同一时间登录游戏,因此我们粗略估算其中的十分之一将同时在线。另外,我们假设这 1 万名玩家每一分钟保存一次游戏,而每位玩家的进度数据记录不足 1KB。最后,我们假设每位玩家在游戏过程中每一分钟需要从数据库中读取一次游戏状态。由于一分钟里有 60 秒,相当于我们的 Amazon DynamoDB 表每秒必须能够支持 167 次写入与读取操作(10000 除以 60)。大多数企业都会保留一部分缓冲容量,因此我们将每秒写入与读取接纳能力提升到 200 次,而总存储空间则设定为 50GB。
根据目前 US-EAST-1 区域的资源计费标准,这样的资源每天只会带来 4.16 美元的开支!也就是说,每天一杯咖啡的价钱完全可以为 10 万名玩家提供支持(当然,这里指的是花式意大利浓缩那种相对较贵的咖啡类型)。作为起步,大家也可以先免费使用 AWS Free Usage Tier 与 Amazon DyamoDB 相配合。
客户示例:《战斗营地》
作为一款由 PennyPop 公司开发的高人气手机游戏,《战斗营地》利用 Amazon DynamoDB 作为其首选数据存储机制。《战斗营地》截至目前的下载总量已经超过 1000 万次,而且在超过四十个国家的应用程序商店中占据下载榜的前百名位置。在比较了其它几套 NoSQL 选项之后,PennyPop 公司的技术人员选择了 Amazon DynamoDB,因为他们希望能够将精力集中在应用程序编程、而非服务器维护与扩展方面。
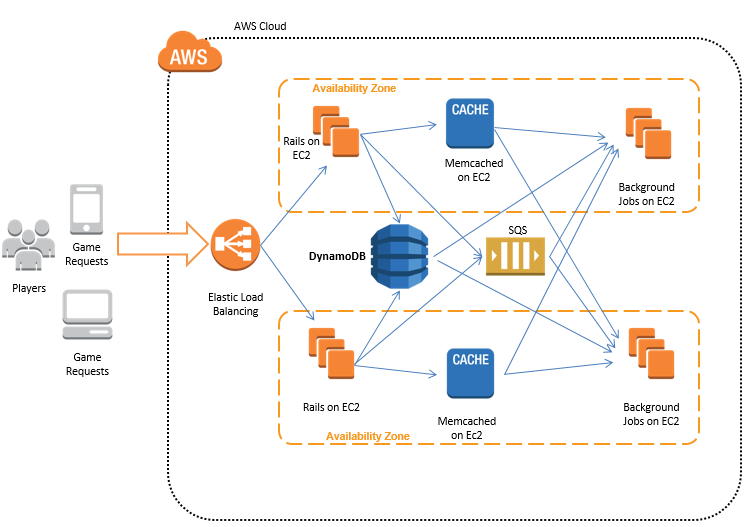
《战斗营地》的开发人员首先下载了 fake_dynamo ,一款开源客户端,来进行本地开发。(Amazon 还发布并支持一款本地 Dynamo 客户端。)他们构建起自己的对象关系映射 (ORM) 以使其能够与 Ruby on Rails 协作。这套 ORM 方案对 DynamoDB 的功能进行了大幅度简化,因为开发人员们只需要在应用程序层中用到键 - 值检索。该 ORM 将值作为 JSON 对象进行保存——所谓 JSON 对象,也就是经过压缩的 base64 字符串。这种机制允许他们将 JSON 对象压缩至原始体积的不足十分之一。大多数 Web 应用程序数据库查询操作可以通过获取与保存简化实现削减,而整个迁移工作也在数周后彻底完成了——在此期间他们还构建起自己的定制 ORM。
下图所示为《战斗营地》游戏如何将 Amazon DynamoDB 整合至自己的架构当中。
结果如何?极大节约了时间与成本。正如 PennyPop 公司联合创始人 Charles Ju 的解释:
Amazon DynamoDB 的成本节约效果一方面借由效率与易用性实现,同时也体现在了维护成本的显著缩减身上。构建、维护以及拆分以数据为中心的大型实时项目一直非常困难,项目的创建与维护也一直要求大量技术人员的参与。然而现在我们在为数百万玩家提供满意的游戏体验的同时,仍然只拥有两位服务器工程师。我们的规模比已知的任何一家 MMORPG 厂商都更具精简特性。
他们还发现,DynamoDB 在其它规模更大的场景中同样运作良好、甚至能够与 MapReduce 分析协议顺利对接,这要归功于其出色的扩展灵活性。他们完全可以构建内部 MapReduce 协议,进而以并行方式执行数据分析。
最后一项:分析
除了实时游戏服务之外,Amazon DynamoDB 还集成了一系列其它 AWS 服务,其中包括 Amazon Elastic MapReduce(简称 EMR)以及 Amazon Redshift。Amazon EMR 与 Amazon Redshift 都能够直接从 Amazon DynamoDB 当中加载分析数据,从而简化分析工作流的构建方式。如果大家想了解更多在 AWS 上对游戏内容加以分析的信息,请在评论栏中发表意见、我们将在未来的文章中专门探讨这个话题。
本文原载于 AWS博客。




