作为新兴媒体网站,Twitter 有着和传统媒体截然不同的使用方式,比如与传统媒体多重防止爬虫爬取网站内容相比,Twitter 对开发者开放了非常多的 API,以方便他们通过各种方式与 Twitter 后台交互。又比如 Twitter 对实时性的要求很高,比起纸媒、门户网站、博客、邮件来讲,快速响应的用户体验要求很高。在暴露大量接口和高实时性这两个产品设计的驱动下,Twitter 成为了人们非常青睐的社交网站。然而,接踵而来的就是那个永恒的话题:如何对抗垃圾信息。在这个问题上,Twitter 的两个设计上的优点反而成为了对抗中的挑战,垃圾信息可以从各种接口以各种形式接入,并且以近乎瞬间的速度直接推送到用户。以往成熟应用于电子邮件、博客等内容的垃圾信息对抗技术,在这两个挑战面前显得力不从心。这便是 BotMaker 诞生的契机。据博文提供的数据,在采用了 BotMaker 技术以后,该系统每天处理多达数十亿条推文,并成功的将垃圾信息的数目缩减了 40%。
Twitter 于 8 月 20 日在其官方博客发表了一篇博文(需科学上网),介绍了 BotMaker 的设计理念、挑战以及架构。
从设计目标来讲,Twitter 希望垃圾信息能够通过一种层层过滤的方式拦截:最理想的第一层,就是在垃圾信息制造者撰写垃圾推文的时候判断出结果,并阻止该垃圾推文的发布;没有被拦截住的垃圾推文,则采用第二层,即不断扫描现有的推文,从中尽快找出垃圾推文并清除,从而降低垃圾推文被用户阅读的可能性;最后一层则是对整个系统的更新速度进行了设想,因为垃圾推文品种千奇百怪,随时随地都在发生变化,系统需要在尽量少修改代码的情况下,尽可能快的更新,以应对层出不穷的垃圾推文。
在这种设计理念的驱动下,系统能够很好的过滤垃圾推文,但是随之而来的是三个挑战,BotMaker 对易用性、普适性以及实时性方面的要求很高。因此 Twitter 将其设计成了一种基于规则的系统,系统维护人员通过撰写简单的规则而不是修改代码来对抗垃圾推文,从而达到上述指标的要求。通俗来讲,BotMaker 的规则由两部分组成,一是触发条件;二是动作。如博文中所提到的简单例子:
Condition:
HasSpamUrl(GetUrls(tweetText))
Action:
Deny()
所表达的意思就是:如果当前推文中包含了垃圾网址,那么这条推文就会被拒绝发布。这种规则系统的设计,一般需要遵循维护人员看得懂,简单规则可拼接成复杂规则,新规则的添加不需要改动代码以及规则起作用的时间只需要几秒钟等等原则。
然而,看似简单的规则系统背后,需要大量的计算来给出类似是否包含垃圾网址这样的判断,这些支撑数据都是要通过不断对推文、转发、收藏、粉丝和私信等等数据计算出来,而且还要支持一定的机器学习相关规则如分类规则。在 Twitter Storm 分布式系统的支持下,博文给出了 BotMaker 系统的设计架构:
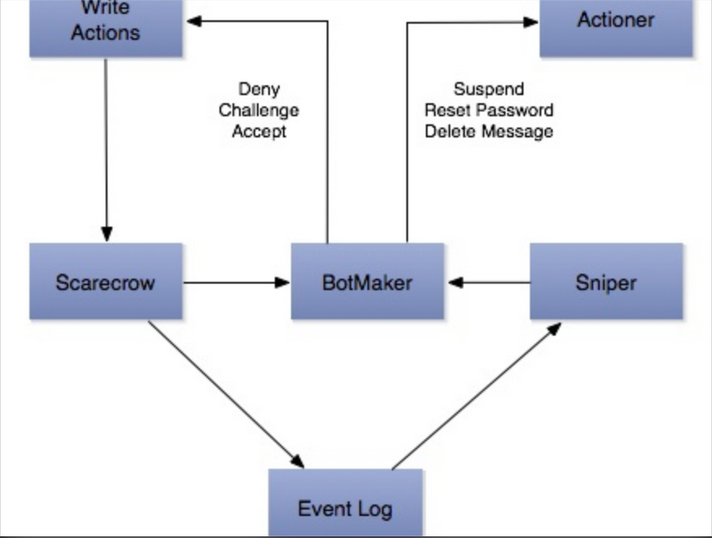
图中以用户发表推文整个流程来解释了 BotMaker 的组成。首先,在用户撰写推文的过程中,Scarecrow 模块就开始根据推文内容来判断其是否是垃圾推文了,这个阶段主要的技术指标是高实时性,规则相对简单,如关键字以及一些统计规律;其次,在推文发表之后,Sniper 会根据发表日志来扫描推文,通过机器学习中分类器等方法构成的规则,不那么实时的来异步判断是否是垃圾推文;再次,系统会对用户一个阶段的行为建模,来提取辨别垃圾推文的特征,这部分工作可以离线完成。
博文最后称,Botmaker 开辟了 Twitter 对抗垃圾博文的新技术,有了这个系统,Twitter 的工程师们以前数以天计的编写垃圾推文过滤代码的日子已经成为过去,开发效率得到了极大的提升,并且效果也非常的明显。在未来,工程师们还会根据易用性、普适性和实时性等原则来对 Twitter 其他的系统进行修改和完善。
感谢郭蕾对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ )或者腾讯微博( @InfoQ )关注我们,并与我们的编辑和其他读者朋友交流。




