2014 年 9 月 20 日,在由 @百度主办、 @InfoQ 负责策划组织和实施的第 54 期百度技术沙龙活动上,来自百度自然语言处理部的杨程和来自清华大学自动化系控制理论与技术研究所的赵明国,两位讲师分享了各自在人工智能及机器学习领域的相关经验。
本次分享的话题分别是“ 计算机围棋 - 蒙特卡洛搜索与统计学习”和“ RoboCup 人形组的技术与挑战”。本文将对这两个主题分享做下简单的回顾,同时提供相关资料的下载。
主题一:计算机围棋 - 蒙特卡洛搜索与统计学习(下载讲稿)
计算机博弈在人工智能这个领域是一个重要的研究方向,这与围棋的特性息息相关。杨程举例道:比如说19 路的围棋它有361 个交叉点,如果我们简单地估计它的组合数的话,应该是大概361 个节程,这可谓一个天文数字了。所以我们也常说它的空间复杂度是近似无穷大的概念。除了空间无穷大以外,它的状态也没有办法评估。任意地给一个棋盘的状态,有ABCD 可选的点,我们怎么样知道哪个点是最好的,或者说哪个点的价值高,好有多好,坏有多坏。围棋这块,到现在也没有办法做。这和人工智能的某些领域还比较类似,所以我们把这个领域作为试金石,如果这个领域研究好,相关的领域也会有所提升,蒙特卡洛搜索就是在这样的背景下应运而生。
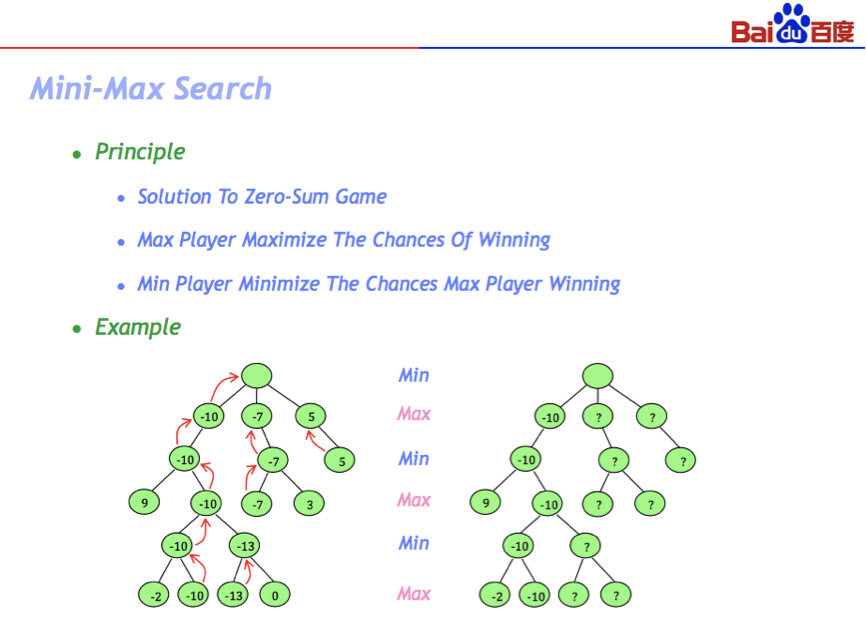
在介绍完蒙特卡洛搜索的背景后,杨老师便开始展开具体的技术知识分享。他首先给大家展示了一个树型结构图(Mini-Max 搜索),这是临河博弈的解决方案,据说还是五十年代提出来的。蒙特卡洛搜索实际上就是基于Mini-Max 来做的。九十年代初,有一个德国人就把它首先用在了围棋上,但是那时候效果很差,所以他在论文中也提到了,看上去很好笑的一个方程,他没有办法用计算语言告诉你,黑一定好,还是白一定好,至少他翻译不成计算语言。另外,棋盘上众多的闲点,每一个点价值最大,ABCD,哪些值值多少分,它是没办法告诉你的。所以早期的阿尔法贝塔搜索,在搜到E 节点的时候,会写一个屏盘数,让这个去决定哪个点好,哪个坏,返回回来。如果这个不准的话,搜索肯定是一塌糊涂。后来蒙特卡洛这个办法,既然到了一个点不知道哪个好,哪个坏,就干脆一直搜,搜到我们可以判别的状态,这样我们就很容易判断,这个围棋的胜负了。
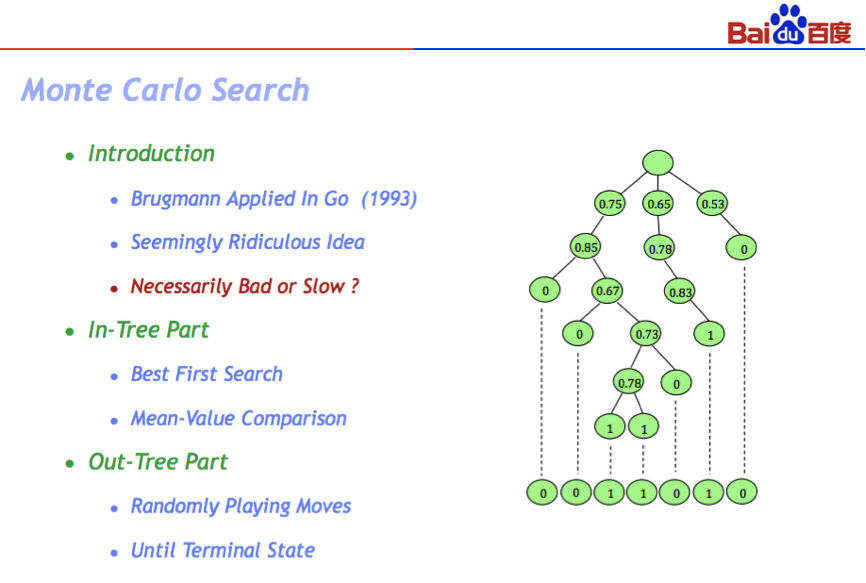
关于蒙特卡洛搜索其实包含两个部分,一个是In-Tree 部分和Out-Tree 部分。In-Tree 的时候究竟怎么搜索?Out-Tree,蒙特卡洛的思想就是一个随机下子,就是说既然过了树节点和叶子节点以后,双方可以随机在棋盘上扔,扔到一个状态后我们再数一下谁赢谁负了。但是一次搜索肯定不行的,我们经过大量仿真以后,发现0.75 是一个均值,就是说走这条路75% 赢了。我们大量做这样的仿真,然后每一个节点的时候我们选择均值最大的那个分值,蒙特卡洛搜索的基本思想就是这样。
当然蒙特卡洛搜索它还是不够准确,其实最关键的原因在于:我们在每一个树节点的时候,怎么判断应该往哪边走,这个很困难。这里面还是有些很深的东西在统计学上。我们可以探索它的均值是不是最好,多去利用它。首先要解决探索与利用的平衡。2002 年,一个奥地利人提出了UCB 的计算,这个算法要求刚开始的时候,赌徒每次都试一次,试完一次以后,就开始做选择了,我们看一下这个地方有这个公式,R,表示我现在第K 个手臂拿到了所有的金币数,TK(N)表示在N 次试验中,第K 个手臂总共实验的次数,也就是说R/T 是均值,后面是一个根号,这个叫做一个探讨项,就是我们刚才说的,前面的是均值最大,当然均值最大不是我们一定要的,所以我们需要有一个探索项,我们每一次做选择的时候,实际上是要求最大的整个公式,我们就选择这个。

UCB 和 UCB1 Tuned 产生了两个公式,在实验中公式 2 比公式 1 效果要好的多。我们看看 UCT 的算法,它其实是很巧妙地借助了 Banit 的算法,但是问题来了,刚开始的时候在内存里是没有树的,是空的,这个树怎么增长?因为这个树每个节点都会出很多统计值,所以你树的形状长的好不好看,如果你太平了,比如像完全二叉树那样,好的坏的没区别,这个树肯定是不行的,我们希望这个树好的方向伸展的很深,坏的很浅,所以这个树的增长在我们这个探索的过程也是很重要的。
最后,杨老师总结到:今天的分享内容理论有些复杂,系统也相对复杂,一个小时肯定是不够的,如果大家感兴趣,可以私下讨论,一起交流。
主题二:Robocup 人形组的技术与挑战(下载讲稿)
什么是Robocup?

来自清华大学的赵明国老师分享了提到:Robocup 就是机器人踢足球。这个相信大家已经有所了解了。就像今年刚刚在巴西举办的机器人足球锦标赛一样,它由一个Robocup 协会举办,形式和人的做法是一样的。主要研究两个问题,一个是多智能系统,另一个是分布式智能系统。因为机器人一定是多个机器人足球一个团队踢球,这样作为多智能体的一个平台是得到大家公认的。每个机器人踢球有独立思考,然后形成团队合作,所以我们叫分布式智能。把这两个结合起来当一个平台去做。
Robocup 的目的是什么?

1997 年,深蓝战胜了当时人类的第一把交椅,就是国际象棋上的卡斯爬罗副,这作为国际象棋上非常标志性的节点,这个就意味着人工智能再往下发展要有一个新目标。新目标选择什么好呢?经过几年的讨论,包括在阿尔斯国际会议上进行初步性探索比赛之后,正好在 1997 年的时候深蓝取得这个胜利,这个作为人类标志性任务结束了,一定要拿到下一个任务,这个任务在 ICI 上正式把这个题目确定下来,实际当时没有把中国围棋考虑进去,因为它和国际象棋的内容一样,虽然围棋会更难。机器人踢足球,大家想人踢足球的时候,不仅仅在动,对手也在动,时时刻刻是动态的环境,这是最主要的区别。另一个,就是状态的不同,下棋的时候你一步,我一步,轮流下,在踢足球的比赛里完全是一个实时性对抗,踢足球必须在最准确的时间做最准确的选择。第三,信息的获取。因为在围棋里面或者象棋里面,还有其他棋里,你所有的状态是准确的,所有的信息是完全准确的,就是计算机里取到的数据没有任何的区别,但是踢足球不一样了,这个我想大家踢过球都应该了解这个情况,你不可能对全局的状况有一个全面的了解,即使解说员在上面,你也可能只关注比赛的一部分,你如何通过一部分的信息能够判断整体的局面,那就出现了很多很多不一样的地方。无论分布还是集中,各有各的优点,各有各的弱项,所以在不同领域的应用也不一样,不见得分布一定好,或者集中好,这有很大的差别,看具体的应用。
Robocup 基本的构件
赵明国老师提到,大概分成这么几类:第一大类叫机器人足球这部分(下面有很多很多的,根据技术发展方向不同和阶段的不同分了几个组别);第二大类叫救援,这个是偏机器人的,因为救援本身是遥控的,它不太需要很多独立的,所以救援里分仿真和实体的。再往下发展,最近大概三到五年已经非常得到重点关注,因为这个应用比较近的,就是家庭组,因为机器人要走入家庭,不只是纯粹的和 IT 业结合的,而且跟家庭结合,跟工厂里的实物结合,这个特别有意义,而且现在美国、欧洲都在做。我们回顾来看,Robocup 仿真组,这个还属于纯粹的人工智能部分,即纯粹软的部分,是里面独立的程序在做。但是对于你编写的程序来讲,这个是你可以认为它是真的,但是它的真实后台不是这样的,所以我们叫仿真组,仿真组在一定程度上是可以的,这个组比较适合于中国开展,所以我们在这个领域取得的成绩,最早取得成绩的也是这个组,而且现在开展规模最大的是这个组,好像很多大学里有很多人在做这一类,实际上现在靠人海战术也做的不错,就是带引号的人工智能,做的也不错。
Robocup 的技术挑战
赵老师提到:早在 2000 年以前,就提出了这样的目标:在二十一世纪中叶(即 2050 年前后)的时候,希望机器人组成的足球队,按照人的所有的比赛规则进行踢,机器人要战胜人类,把这个作为最终的目标。从 1997 年到现在也十几年了,赵老师认为目前还是处于比较低层次阶段,但是就近几年机器人领域和智能领域的发展情况而言,在 2050 年,真可能实现这样的事情。大家尽量发挥想象力吧。
OpenSpace(开放式讨论环节)
为了促进参会者与我们每期的嘉宾以及讲师近距离交流,深入探讨在演讲过程中的疑问,本次活动依然设置了 Open Space(开放式讨论)环节。
在 Open Space 的总结环节,两位话题小组长分别对讨论的内容进行了总结。
杨程:我们探讨的问题条件限制多一些的,涉及的技术比较深,主要还是将机器学习方面,大家在做其他领域的,也可以去尝试。比如说强化学习、个性化推荐等方面,都有相关技术,建议大家试试,咱们也可以先下交流。
赵明国: 咱们探讨的问题是开放性的,比如说,全世界有一百个人做这个事情,但是一百个人的价值取向都是不一样的,我个人会从我自己的研究领域去给大家解答,如果在智能硬件等方面也很感兴趣的同学,也欢迎多多交流。
会后,一些参会者也通过微信分享了他们的参会感受:
@Qian Jun:统计学、人工智能、机器学习、很多学科知识、坚持学习。
@Delete:每次看到围棋人工智能的研究时,都会长舒一口气:人类还有希望。
@壹路高歌:完全模拟人的意义是什么呢?人得器官本身也有很多缺点,应用任何可用的高科技、高性能传感器难道不好吗?
@章恒:喜欢 Computer Go 的讲座,蒙特卡洛搜索其实很好理解,但具体实现还是有一定的难度。
有关百度技术沙龙的更多信息,可以通过新浪微博关注 @百度技术沙龙,或者关注 InfoQ 官方微信:infoqchina,InfoQ 上也总结了过往所有百度技术沙龙的演讲视频和资料等,感兴趣的读者可以直接浏览内容。




