2014 年 8 月 16 日,在由 @百度主办、 @InfoQ 负责策划组织和实施的第 53 期百度技术沙龙活动上,来自百度研究院大数据实验室数据科学家沈志勇,和中国科学院大学管理学院讲师刘颖,分享了他们在大数据领域的实战经验。
本次分享的话题分别是“ 大数据与预测”和“ 基于互联网数据的社会经济预测”。本文将对这两个主题分享做下简单的回顾,同时提供相关资料的下载。
主题一:大数据与预测(下载讲稿)
百度的沈志勇首先提到了自己对大数据时代的理解,他认为这其实是机遇与挑战并存的时代,大数据使整个社会都有了数据意识。大家都知道怎么样采集和记录,把数据都写下来或者是记通过各种各样的方式记下来,以前没有这个意识。这样其实对于机器学习来讲,才能有更加广阔的数据源,对于算法来讲也可以有更多的数据。数据多了以后,多元数据往往存在分布的问题,这样会带来很多问题,我们要解决这种问题往往需要采用一种复杂的模型,这样可以应对下面列出来的问题。这样形成一个时势造英雄的态势。
沈志勇提到:“我们是用机器学习的方法做预测,这里我大概讲一下人的预测和机器的预测大概是什么样的。首先我们看一个正常的人,它是根据自己的经验或者是精力出发归纳一下,这个事情怎么办,根据预测的归纳去推测将来,它是这样的。还有一个比较直接的方法,我直接看别人怎么做,我一个老农民可能知道天气怎么样,但是年轻人不知道,我去看天气预报。人的特点,就是大脑非常神奇,它有很强的识别和推理能力。比如说人工智能很多事情都在说能达到几岁小孩的智商,而且人是one Pass 你没法回去,人会受到主观的干扰。机器学习其实也有一些方法直接利用别的算法或者是结果,它往往是模型的融合或者是模型结果的融合。

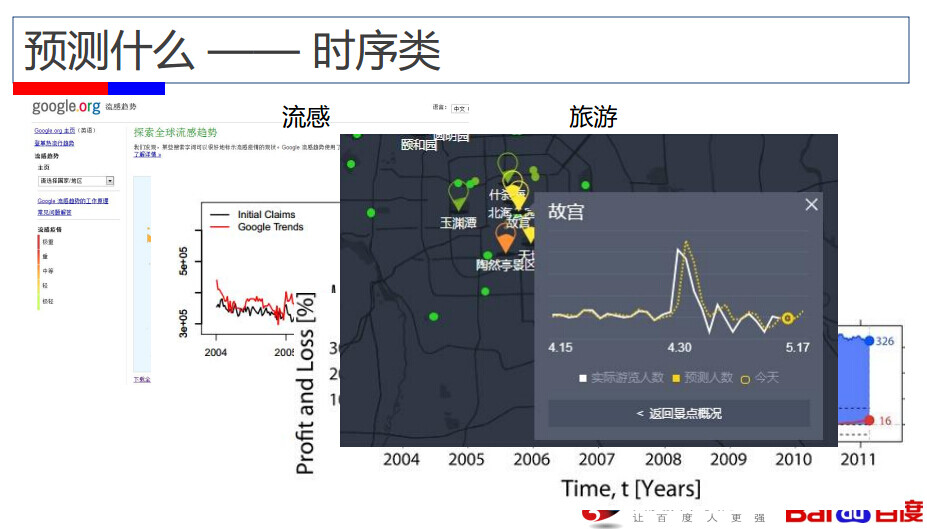
接下来沈志勇以百度预测里面的旅游为例,引入温总理参观百度的故事。介绍了时序类预测的方法。沈志勇提到:“时序性最重要的就是历史信息,以前这条线是怎么做的,对现在有没有参考。有时候你会发现特别没有规律,别的东西在影响它,会形成很多变量。在解释变量的时候会形成非常独特的预测。”“还有一种是事件类的预测”沈志勇用足球比赛作为例子,让大家更明确这种预测的方法。“你要预测它的胜负,最关心这个的人是博彩公司和赌球的人,所以这是一种做法。第二种做法是我们没有精力去做,我们做这件事情只是玩票,刚才说了在预测的时候还可以看别人的结果。其实这个市场是非常有意思的,它跟赌博很像,但是又不是赌博,第三钟做法是比较传统的问卷调查,这样同样能分析出预测的效果。”

最后总结一下,沈志勇谈到:“我们在做的过程中,会根据需求找信息,根据这个信息建模,这其实是见招拆招的过程。现在预测只是我们的入手点,我们整个做的是这样一个智能系统,可能包括了前面的监控、异常检测,诊断以后我们还要做自动调整,会用到各种场合,比如说运维和运营等等这样一些地方。”
主题二:基于互联网数据的社会经济预测(下载讲稿)
中科院的刘颖老师把大数据在企业中的应用(或者是在经济中的应用)分为三个层次,分别是宏观、微观和中观,从这三个方面做了一些研究实例,分享给大家。

1、微观层面
主要是在企业的层面做的比较多。企业应用最多的就是运营和营销,可以给企业的运营带来一些借鉴和促进作用。在营销方面有一些个性化、针对性的营销。亚马逊可能在国外做电商用户行为做的非常好的公司,亚马逊商品的定价采用的是及时的扫描所有竞争对手商品的定价,它采用的不是最低定价法,而是倒数第二的定价法。
2、中观层面
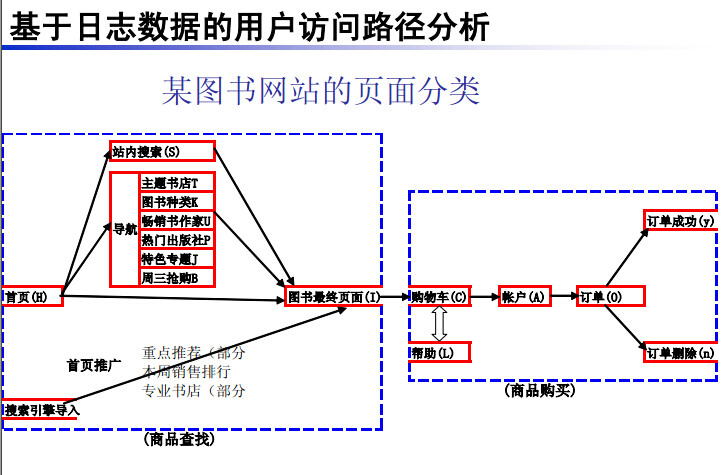
这个涉及到行业的预测,刘颖首先分享了一个案例:电商交易背后的用户行为规律。刘颖认为这实际上是对电子商务的日志分析的结果。“我们都听过啤酒和尿布的例子,我们也还想知道关联推荐交易结果背后,用户走过的哪些脚步,用户的过程有没有一些规律,这个可能对网站的运营人员也是特别重要的,这个结果我们也是从问题出发。如果从店铺的运营角度,我们希望知道用户走过的这些路径的规律,如果是从营销的角度,我们希望把用户进行分层和细分,每个层级的用户它的特点是什么,我们希望用什么方法给它做营销效果更好,这是两个思路。”

3、宏观层面
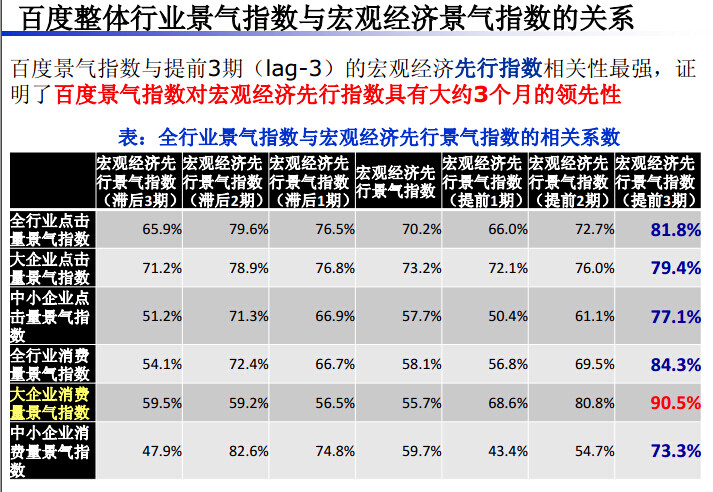
在宏观层面,我们国家现在比较关心的是经济增长、促消费,以及领导人经常提到的要知道中小企业的经营状况,我们做了中小企业的精气指数。先分析国家的宏观形势,再分析我们行业的形势,对公司的经营和各个方面的基本面的分析来决定这个公司的股票是不是值得购买。
最后刘颖老师总结到,“我们这些研究可能更多的是关心企业的实际问题,从问题出发来找数据,我们其实不是特别关心数据的量大还是量小,只要你用我们认为就是好数据,实际上真实到用的往往是小数据,对企业的决策直接产生价值。”
OpenSpace(开放式讨论环节)
为了促进参会者与我们每期的嘉宾以及讲师近距离交流,深入探讨在演讲过程中的疑问,本次活动依然设置了 Open Space(开放式讨论)环节。
在 Open Space 的总结环节,两位话题小组长分别对讨论的内容进行了总结。
沈志勇:我们在做的过程中发现:图模型有非常强的表达能力和信息压缩能力,你的数据量太大,耗费的时间也会太长,所以要在有限的时间内做大量的数据是比较累的。
刘颖:我们一定要以企业的实际问题出发,做数据分析不一定要盲目追求数据量大,不管是大数据、小数据,能够解决问题的数据就是好数据。
@滕毅 大数据是行业趋势,期待老师带来的酱菜讲解;
@winsh 有什么好的大数据分析模型么,比如豆瓣面向用户的图书电影推荐?
@ 夏粉 _ 百度:百度大数据实验室沈志勇老师为大家揭开世界杯神预测之谜!




