2014 年 7 月 26 日,在由 @百度主办、 @InfoQ 负责策划组织和实施的第 52 期百度技术沙龙活动上,来自百度语音技术部的李秀林,和中国科学院自动化研究所研究员陶建华,分享了各自在语音合成领域的经验。
本次分享的话题分别是“ 拼接语音合成——折衷的艺术”和“ 语音合成现状与未来”。本文将对这两个主题分享做下简单的回顾,同时提供相关资料的下载。
主题一:拼接语音合成——折衷的艺术(下载讲稿)
百度的李秀林首先给大家介绍了语音合成技术的发展,对于语音合成技术,有些朋友可能还不是特别了解,语音合成又叫文语转换,是将文本转换成语音的一种技术。实际上在日常生活中,可能我们已经用到很多语音合成产品,李秀林举例说到:比如我们开车的时候用的汽车导航,里面就是内嵌了语音合成系统。我们所用的语音助手可以跟手机对于对话查询信息,那里面有了语音识别,也有语音合成。其他的像读书里面都不离开语音合成,只是很多时候我们可能真的没有感受到它是一个机械合成出来的铃音。

随后,李秀林给大家介绍语音合成部分,可以划分成三个主要阶段,一个是机械式的语音合成,第二个阶段是电子式语音合成,第三个阶段是计算机语音合成。
机械式语音合成早在1846 年就有人把它研究出来,它是利用一些键,有14 个按键,每个按键对应一个因素,可以产生类似的声音。如果把这些组合起来可以表达一定的意思,有点像人说话,但是这种相似度还是比较差的。
在这之后大概过了将近一个世纪,电子技术迅速发展,自然而然就产生了电子式语音合成器,相对机械式语音合成器,它的结构主要是部件的不同,它的调整能力也要比机械的更灵活。
八十年代之后,计算机的技术发展存储空间和运算速度都不再是瓶颈,语音技术的发展也日新月异。现在是语音技术都算是第三代,但是它的表现有多种多样,所以说有些不同的分类方法。

了解到语音合成的技术发展后,如何判断一个语音合成效果呢?李秀林介绍到:一般采用主观评测的方法,主观评测方法又有两种,一种是MOS 评测,一种是ABX 评测。一般来说如果达到3 分左右,那么大体上是可以在一些特定的情况下应用,如果达到4 分,就认为这个是可以比较好的推广。目前来看,我们语音合成技术基本上可以达到4 分或者是4 分多一点。
对于ABX 评测,把两个不同的系统分别合成出两批样本,样本两两对比,好的得2 分,较差的得0 分,这样的话如果两个相当各得1 分,最后把分值累积以后,得分比较高我们认为这个系统胜出。有了评测的方法,我们可以反过头来用评测的方法来看技术的进步。
最后,对于语音合成技术的展望,李秀林认为有三个方面是重点,一个是机器学习,它对识别和合成可能有一定的推广作用。另外是个性化,现在说个性化还比较远,比如说你听惯了这个厂商的声音和那个厂商的声音,你都不想听了,你想不想听你孩子、爱人和朋友的声音,我觉得这将来是一个广阔的空间。但是目前的技术还有一定需要突破的地方。还有一个表现力情感方面,让他不再平淡,这个也是需要重点突破的方向。
主题二:语音合成现状与未来(下载讲稿)
中国科学院自动化研究所研究员陶建华从事语音合成这个领域已经有20 多年了,从1993 年一直研究到现在,基本上经历了从语音合成发展整个的历程。
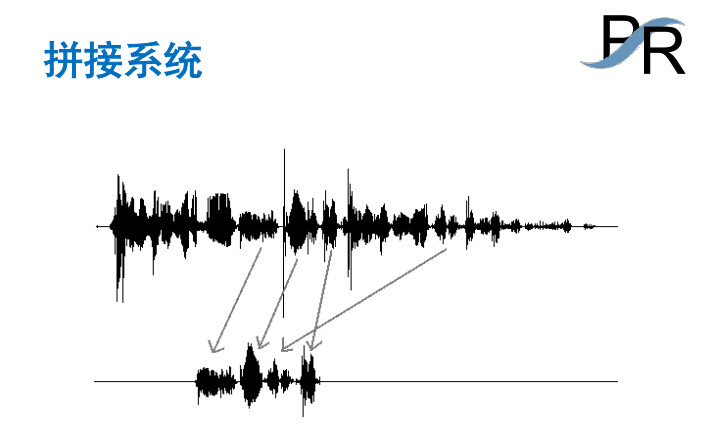
首先,陶建华介绍了典型的拼接系统的构成,实际上它就是从原来录的音当中找到合适的声音然后放出来,从原来的语音当中找到一个个小的片断,然后拼接起来。如果你仅仅只是简单的把这样的声音截取出来,它的声音是不连续的。于是在拼接语音合成里面要做大量的算法,我们来看一个连续语句如果有7 个音节,可以理解为汉字,它每一个汉字都会有N 个侯选,这来自于你录的声音当中。我们希望在这N 个侯选里面,比如说这里面我找最优的路径,把侯选的东西拼起来,然后品成完整的,最后会成为一个连续的语音,语音合成系统它实际上是这么一个概念,它并不是简单的拼接。

陶建华提到拼接系统它有很多的优点,它也有缺点。比如说拼接系统它的音质非常高,很接近人原始的声音,因为它的音质是没有损伤的,所以它的声音音质很高,听起来更接近于原声,他需要大量的数据,同时他的声音在拼接的时候多少会出现一些不连贯的地方。
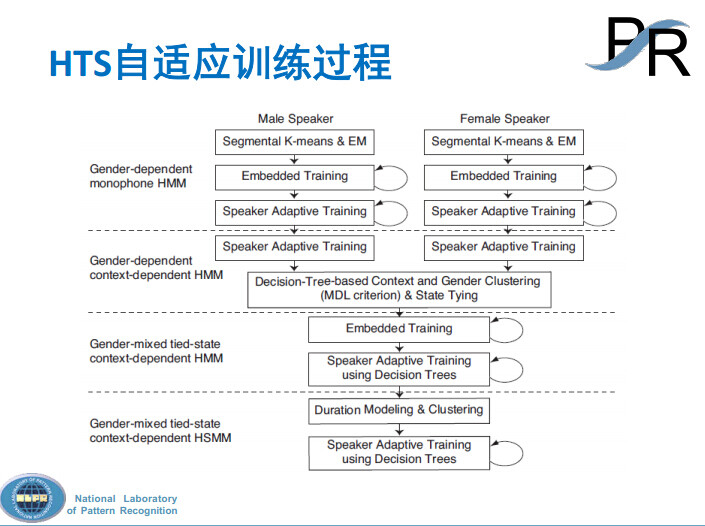
随后,陶建华提到了语音合成的个性化问题,从目前来看,其实主要是两种方法能够实现。一种方法就是重新录一批数据,重新训练,这个方法无论是拼接系统,还是参数合成系统,同样适用,只要是一个新的数据,张三是张三的数据,李四是李四的数据。还有一种就是我的数据量并不够,自适应目前为止比较成熟的系统,只能基于参数获得系统,用深度神经网络和其他的方法同样可以使用。
当然还有自适应的方法,本质上来说,我们先训一个平均的基于参数统计的合成系统,针对不同的说话人之间做自适应,比如说在语音识别里面常用的最大似然的方法。当然也有人说我用深度神经网络可不可以做,当然可以做,深度神经网络同样也可以用来训练不同人的声音。
最后,陶建华总结到:其实语音合成从参数合成系统到拼接系统,再从拼接系统回大参数系统,从参数系统大家又开始重视拼接系统。我们看到技术发展的趋势,它并不是简单的回溯,大家每一次有不同重视点的时候,它会带上新的研究进展。在未来几年当中,大家随着这个技术的不断往后延伸,会把现在技术最新的结果结合我们所谓个性化、口语化,以及结合一些以不同的领域当中要求,把它进一步的深化来推动语音合成进一步的往下走。
OpenSpace(开放式讨论环节)
为了促进参会者与我们每期的嘉宾以及讲师近距离交流,深入探讨在演讲过程中的疑问,本次活动依然设置了 Open Space(开放式讨论)环节。
在 Open Space 的总结环节,两位话题小组长分别对讨论的内容进行了总结。
李秀林:刚刚很多朋友在问:如果我把我的声音上传会怎么样?简单总结一下:只要通过通电话的声音或者跟别人聊天的声音,只要将来语音合成技术做得比较成熟,我们会开放接口,允许大家上传,定制自己的声音。这也是我们的技术愿景。
陶建华:从刚来的提问中,可以发现大家对个性化、口语化的声音处理方面比较感兴趣。个性化的声音在现在的应用角度来说,还需要一些专业人士来做,从算法级别上来说,虽然在少量数据里,不能完全模拟比较逼真的声音,但是这个技术的发展速度比以前要快很多,我相信,我们在不远的将来就能真的把这样的技术应用得更好!
会后,一些参会者也通过微信分享了他们的参会感受:
@李习华:语音识别,理解,合成总体来说是语音智能,需要和其它的应用需求结合起来。个人认为语音智能技术已经很成熟了,需要的是应用场景。
@丛鹏宇:用过几个安卓的读书软件,基本都是用的盛大的听听中心,合成质量还不错,百度的还没见到,很是期待。
@草之木:语音转换需不需要以文字作为中介,例如刚才的女转男?
@灵丫头:有个技术以外的问题:文字、图片、语音这三个信息载体都可以编辑和模拟个性化,那当技术水平足够高的时候,人工智能的时代是否到来?而模拟绝对逼真的时候,你的那个她还是那个她吗?
有关百度技术沙龙的更多信息,可以通过新浪微博关注 @百度技术沙龙,或者关注 InfoQ 官方微信:infoqchina,InfoQ 上也总结了过往所有百度技术沙龙的演讲视频和资料等,感兴趣的读者可以直接浏览内容。
特别提示:第53 期百度技术沙龙将在8 月16 日在车库咖啡举行,主题为跨界的“基于大数据的预测实践” ,欢迎关注 @InfoQ 、 @百度技术沙龙获取后续的活动信息。
给 InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ )或者腾讯微博( @InfoQ )关注我们,并与我们的编辑和其他读者朋友交流。




