最近 C3 沙龙在雅虎北京全球研发中心举行,雅虎中国首席架构师曾宏威分享了雅虎个性化推荐引擎的工程实践,具体包括整个推荐引擎的系统是如何搭建起来的,搭建过程中遇到了什么问题,是怎么解决的。下面是分享内容的总结:
雅虎个性化推荐引擎运用案例
个性化推荐引擎已经在雅虎的首页、新闻、体育、财经等很多频道,以及雅虎的 Email、用户订阅的邮件内容等方面使用。个性化推荐引擎推荐的内容有雅虎编辑原创的内容,也有雅虎购买版权的内容,还有从 Web 上抓取的内容,包括新闻、图片、博客、轻博客等形式。现在已经在欧洲等地方做全球化的推广,并且统计发现个性化推荐引擎对于用户粘性的提升已经超过了 100%。
推荐引擎的系统架构
雅虎个性化推荐引擎的系统架构如图 1 所示。整个系统的工作原理:系统通过对内容进行分析,提取内容的关键特征,并形成文档索引。值得注意的是,当用户授权使用社交网络的账号登陆雅虎平台时,还可以对用户的社交网络行为进行分析,通过会对用户的兴趣进行标记,并形成用户画像。文档索引建立起来了之后,当用户访问雅虎时,就会知道用户的兴趣,并在文档索引中根据用户兴趣找到相关的内容,并根据个性化引擎的排名进行展示。
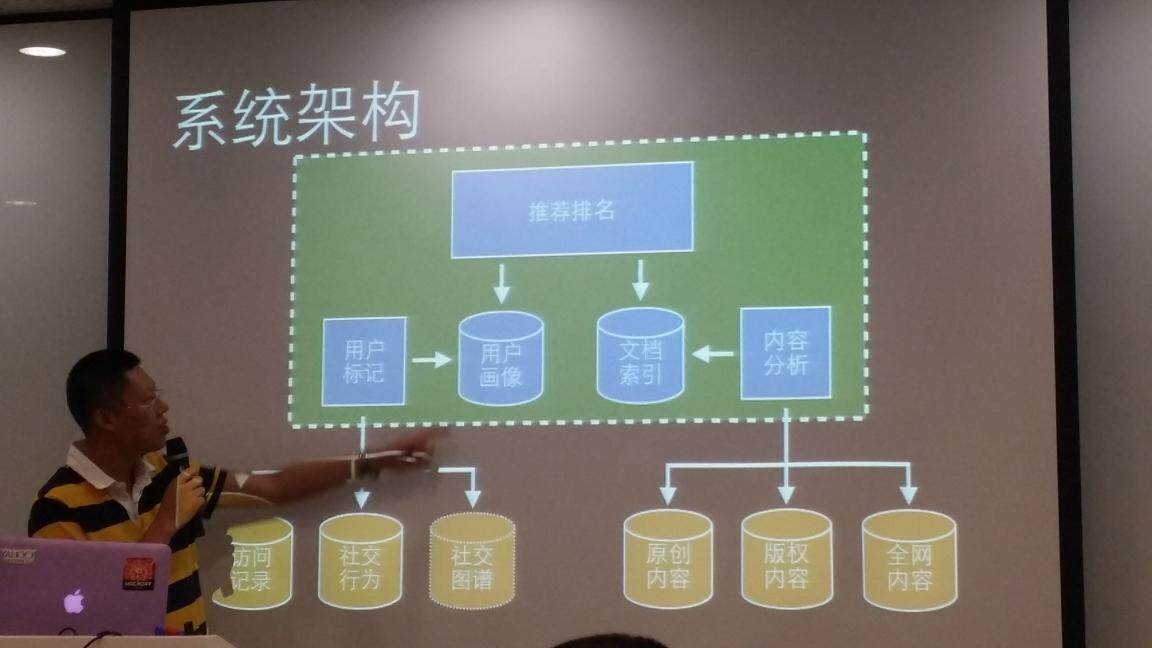
【图 1】雅虎个性化推荐引擎的系统架构
数据收集:数据采集以前都是从 Server 端去做,现在越来越多地从前端去采集,越来越多的网页都是动态网页,很多用户行为都是在前端发生的,如果从后端去采集的话只能记录到用户的点击,但是如果使用 JAVA Script 在客户端进行记录的话,可以采集到更多的用户数据,比如用户停留鼠标停留了多长时间,就可以有更多的数据,数据可以更丰富。Beacon 的服务器是所有的雅虎服务器公用的,需要使用时,需要把它放到自己的 Hadoop 和 Storm 上。雅虎的 Data Highway,主要是完成从 data Server 上采集数据,并进行分发,存在于多个数据中心,还有一些数据从 Twitter、Facebook 上获取。
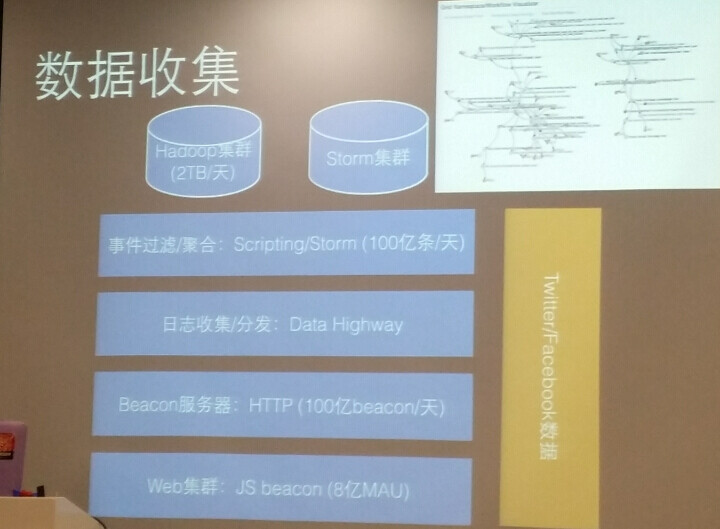
【图 2】雅虎个性化推荐引擎的数据收集
新模型 /算法的评估上线:当有了一个新的算法,需要使用一个新的模型时,雅虎会先对模型进行训练,训练好了之后再进行一些线下的评估,最后如果线下效果不错就会逐步做正式的线上测试。
首先,需要新的训练模型的新的样本,雅虎会把小于 5% 的流量用于模型训练,取 2500 万左右的用户,72 小时内,在 Hadoop 上进行训练,为了模型训练时判断模型对用户粘性的影响,有一些常规的指标进行判断。
模型训练好了之后,就需要进行一些线下的评估。具体有一些评估的指标,包括准确率、精确率、ROC 等。线下评估的好处是不需要在线上进行测试,可以节省很多成本。
如果线下效果不错,就要正式做线上的测试。在 100% 的流量中,会分配 20% 的流量来做各种各样的测试,因此,访问雅虎的 80% 的用户看到的是正式的结果,20% 的用户看到的其实是测试的结果。全球基本上会有超过 200 项的实验在进行,每周会发布 10-30 个线上测试,并在 1-2 周内观测模型的效果,有时候需要测不同的参数,每个实验会有 4-5 个测试,用来评价的指标大概有 3-4 个(点击率、评估时间等),都是跟用户粘性相关的。内部会有一个 DashBoard 展示相应的评价指标。如果线上测试通过了,就会放到正式的环境中,这时大概会有 80% 的用户看到的是新的模型 / 算法产生的内容。
为了实现模型的快速优化更新,还需要有一个高度集成的流程,包括很多自动化测试、回归测试等等,有一些测试完全自动化的难度也会非常大的,有些性能测试还需要手工去跑。
对于一些重大的算法的调整,会有一个灰度阶段发布,从 5% 的流量,到 20% 的流量,再到 50% 的流量(可选),在比较自信的情况下,也可以直接到 100%。这样可以在出现问题时,快速回滚到上一个版本。
关于用户粘性的判断:判断用户粘性有 6-7 个相关的指标,比如点击量、停留时间等等,这些指标还分为短期指标和长期指标。短期指标可以在算法上线后十几分钟就可以看到效果,但是短期指标不能替代长期指标,比如我一个算法推荐出来的都是美女图,短期指标可能会比较高,但是不一定是长期的用户粘性指标就会高。需要通过长短指标结合的方式来保障每一个实验的效果。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ )或者腾讯微博( @InfoQ )关注我们,并与我们的编辑和其他读者朋友交流。




