来自于 Aerospike 的技术人员 Rajkumar Iyer 最近在 highscalability 上发表了一篇博文,介绍了 Aerospike 在探索数据库扩展、实现 1M TPS 挑战的过程中所遵循的 3 个设计点和 5 个要避免的常见瓶颈。如果想要查看英文原文,可以点击这里: The Quest For Database Scale 。
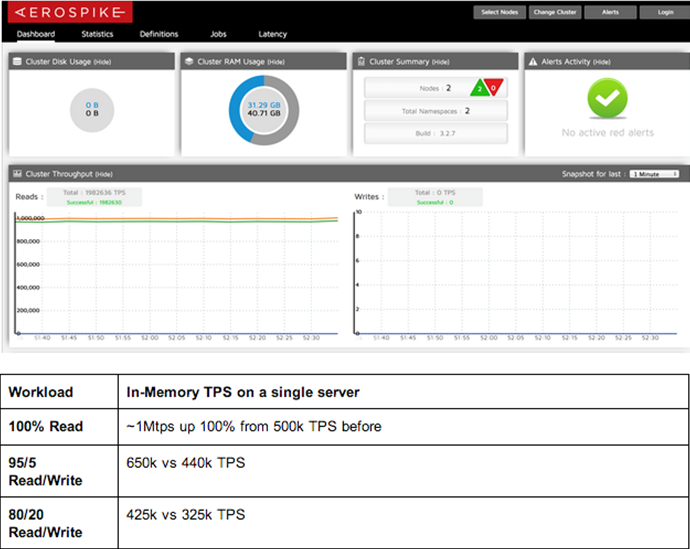
Rajkumar Iyer 介绍说他们大约在 1 年之前就已经开始探索提高内存数据库性能的方法——在一台廉价的商用服务器上实现 1MTPS。那个时候他们实现了支持约 200K TPS 的 Aerospike,通过提升无缓存架构的延迟和吞吐量他们将性能提升到了 500K TPS,并且发布了 Aerospike 2.0 社区版。在那之后他们通过内核调节技术发布了在 5k$ 的硬件上实现 1M TPS 的方法。
进入2014 年之后Aerospike 依然在探索,他们的目标是在一台服务器上实现每秒钟1 百万数据库事务,比之前的性能快2 倍多。与Cassandra 夸耀的在Google 计算引擎中通过300 多台服务器实现1 百万TPS 相比,Aerospike 并没有对内核进行调整就实现了该目标。
三个设计点
运营这种强度的任何分布式数据库系统都必须在架构中牢记三个设计点:
1) 稳定性——通过简短、可理解的代码路径实现。保持所有的函数简洁优雅是确保整个系统平稳运行的重要途径,哪怕是在将多个这样的层堆叠在一起的时候。任何复杂难懂的逻辑都会让系统变得难以维护,应该或者最好尽可能地少用这种逻辑,不得不用的时候需要将其隔离。
2) 可预见性 ——通过使用 C 语言编写数据库并仅用少数外部类库来实现。预测代码的行为意味着你能够对系统正在做的事情进行精确、全面的控制,并且尽力确保所有的资源都得到了有效地利用。Aerospike 并没有使用“libeio”、“libev”或者任何其他的类库处理网络。此外,Aerospike 也没有使用内存映射——相反地,它调用读、写操作本身。因此虽然 Java 和 Erlang 这样的语言可能会缩短整体的开发时间,但是 C 依然是最佳选择。
3) 可扩展性——通过向上和向外扩展实现。按照旧的 RDBMS 的方式进行垂直扩展并不能满足所有的用例场景,也无法平滑地使用资源没有被充分利用的大规模向外扩展的集群。成本的增加和管理是一个挑战——即使是在最好的情况下一个分布式系统也永远不可能正确或者可预测,因为它会增长,错误率也会上升。平衡的方法是最好的。从一开始 Aerospike 就被设计为可以向上和向外扩展的,它能够最大化服务器利用率让每台服务器实现 10 倍于其他 NoSQL 数据库的事务处理速度,同时还允许热增加或者删除服务器。
另外,数据库不要孤立存在,它们必须作为整个堆栈的一部分。一个向外扩展的数据库必须考虑所有的集群功能,不要把负载推给应用,例如分片或者负载均衡。任何将复杂性转移给应用的数据库都不能算做是真正高可扩展运营系统的一部分。
5**** 个常见的瓶颈
为了成功地在一台服务器上实现超过百万的 TPS,任何数据库系统都必须有效地避免 5 个常见的瓶颈。
1)网络开销
对任何客户端—服务器架构而言,第一个瓶颈就是在网络上移动数据包,从网卡移动到内核再移动到用户空间的开销。Aerospike 之前的努力需要将 irq 绑定到 NIC 中的多个队列上进行负载均衡。在那之后,这个 irqbalance 变得更加智能,减少了 Aerospike 的工作。
英特尔数据面开发工具套件(DPDK)这样的选项完全消除了 TCP 栈的开销,让用户空间函数处理网络数据包。但是 DPDK 并不会处理 TCP/IP,也不会处理大的请求,因此数据库系统必须实现自己的流控制。除非 DPDK 被支持并且被广泛地接受,否则优化通用数据库从而使用 DPDK 依然是将来的事情。
2) NUMA**** 开销
第二个瓶颈是在 NUMA 区域之间移动数据的开销。理想情况下,数据库服务器应该是一个单线程的事件循环,不需要上下文切换——但是这种方式有两个重大的弊端。首先数据库系统必须管理大量不同的任务——长时间运行的工作,短时间运行的工作、磁盘 I/O、网络通信以及处理偶然峰值的缓冲请求。构建这样一个单事件循环的系统会让事情变得非常复杂。其次,从单核到多核并行运行这样的系统需要将大量的逻辑转移到客户端。
无论如何,让多线程进程运行在多核多 socket 机器上都有需要在多个 NUMA 区域之间移动共享数据的问题。为了避免单核实现和 NUMA 开销,平衡的方法是构建一个系统,通过每个 CPU socket 分组多线程而不是像单线程系统那样按照每个核。这样就能够确保共享数据不会被多个 NUMA 区域访问,同时也允许系统使用更简单的逻辑线程。
3) 上下文切换的开销
在一个多线程系统中,我们很容易就会创建大量的线程,所以如果不谨慎处理那么上下文切换就会成为系统瓶颈。应该尽可能地编写单线程操作,不要在线程间传递请求。
4) 内存总线延迟
下一个大的瓶颈在 CPU 上——由于需要等待数据或者因为分支预测错误而导致的 CPU 空闲。对这类问题的处理方式是:
- 精心设计数据结构从而确保频繁或者经常访问的数据在一个单独的缓存线上有空间。
- 最小化分支指令的数量。这是反向谓词推动的,所有的分支都在前面完成,主逻辑仅包含最少数量的分支指令。
对一个线程而言辅助性的数据始终应该是本地的,同时应该在查询的时候合并从而避免不必要的数据移动。
5)跨集群的动作
向上向外扩展的基本原则是,系统之间几乎没有共享——最小化跨集群的同步动作。在 Aerospike 中,数据使用了一个简单的算法分割,同时访问路径按级组织,因此每个线程都能独立运行而没有竞争。高竞争的第一个迹象就是低 CPU 利用率——类似于 MongoDB 在多核机器上处理写负载时的运行情况。
结果
在使用 2 个节点、5000 万条记录同时每一条拥有 128 个字节的数据都复制 2 份的情况下运行同样的测试,结果显示:与之前的结果相比,新的方法(在 CentOS 6.3 上运行 Aerospike 社区版 3.2.8)性能提升显著。