搜索是很多用户在天猫购物时的第一入口,搜索结果会根据销量、库存、人气对商品进行排序,而商品的显示顺序往往会决定用户的选择,所以保证搜索结果的实时性和准确性非常重要。在电商系统中,特别是在“双十一”这样的高并发场景下,如何准确展示搜索结果显得尤为重要。在今年的“双十一”活动中,InfoQ 有幸采访到了阿里巴巴集团搜索引擎的三位负责人仁基、桂南和悾傅,与他们共同探讨了搜索引擎背后的细节。以下内容根据本次采访整理而成。
阿里巴巴的搜索引擎承担着全集团的搜索业务,包括淘宝、天猫、1688 等系统,对比传统的搜索引擎,阿里集团的搜索引擎有一些比较大的突破性、创造性的工作。传统的搜索引擎,只可以做到离线全量、增量构建索引,而阿里的搜索引擎已经是演变成为一个能够做到离线、增量、实时三个等级的搜索引擎。电商平台最大的一个特点就是短时高并发,像双十一这样的活动中,搜索引擎需要考虑如何让流量发挥更大的价值。传统的搜索引擎解决短时高并发的思路是添加缓存层以减少搜索引擎的访问量,而这样的解决方案,天猫之前也有使用,但是缓存会有延迟,实时搜索的需求根本无法满足。所以为了解决实时的问题,阿里的搜索引擎去掉了应用层和业务层的缓存,重点优化和提升引擎层的服务能力。为了兼顾实时性和吞吐量,搜索引擎实现了全量、增量、实时三种更新通路。通过三种方式的灵活组合,在保证了海量数据定期全量更新的同时提供了秒级实时更新能力,避免了数据延迟,提升了用户体验。
系统架构
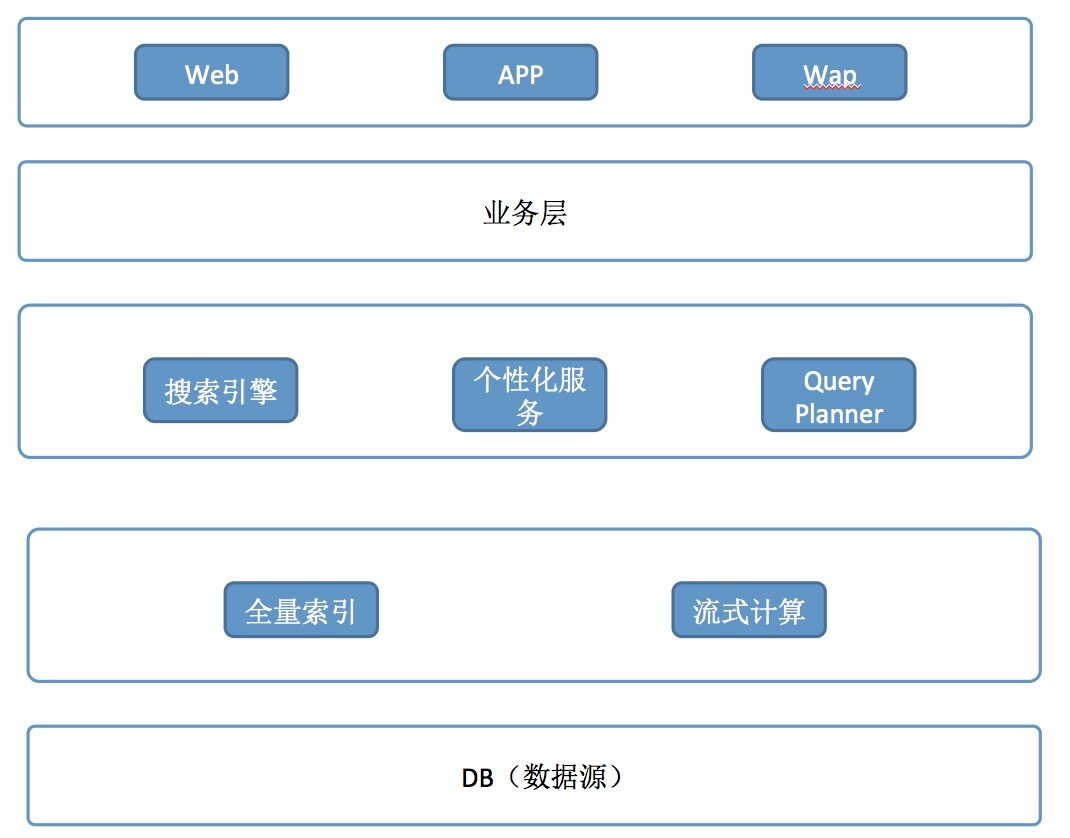
从整体上来看,阿里搜索引擎的架构图如下。从上到下,分别是应用层、业务层、搜索引擎层、离线处理层和 DB 层,应用层其实就是调用方,大的来看可以分为 Web、App、Wap。业务层会针对相应的业务对搜索结果进行整理,如 Android 和 iOS 的搜索结果显示是不一样的。搜索引擎层有点类似传统系统的搜索引擎,阿里巴巴的搜索引擎会在搜索的基础上根据用户习惯提供个性化的搜索结果。索引层主要包括全量索引和流式计算,全量索引其实就是一个基于 Hadoop/HBase 的离线集群,而流式计算是阿里自己研发的一套系统。之所以没有选用 Storm,是因为在这一层中,光有计算是不够的,还需要有数据的存储(开源解决方案 HBase)。如果使用 Storm,接下来会面临一个问题,Storm 是一个集群,HBase 又会是一个集群,这样,Storm 的 Disk 以及 HBase 的 CPU 其实都没有充分利用到,所以阿里的方案是 Hadoop Yarn 与 HBase 混合部署,把两个集群合并在一起,既可以做大规模的数据处理,也可以做流式计算,通过这样的方式,可以将离线和实时计算更好地融合。最底层的数据源层会把用户、商品、交易信息同步到上层的 HBase 集群中。
流式计算
Storm 是一个无状态的流式计算框架,而无状态的流式计算体系,更适合做简单的统计分析,比如针对成交维度或者点击维度做计数。而阿里自研的流式计算框架 iStream,已经不再是简单的、无状态的流式计算概念。iStream 借助 HBase 集群存储用户状态,以完成一些相对复杂的模型的计算。同时模型的计算结果可以通过相应的接口直接推送到上层的搜索引擎中,以服务每一条流量的排序变化。
排序链
在搜索引擎层,不仅包括商品的搜索引擎,还会包括其它层面的服务(如架构图所示)。商品搜索引擎中包含商品、店铺、活动等维度的信息,而图中的个性化服务旨在为用户提供个性化的搜索体验,个性化服务会根据用户的实时行为反馈搜索结果。而 QP(Query Planner)会对用户的搜索请求进行分析(搜索词、搜索场景、页面)进一步个性化搜索服务。在搜索引擎层,通过这三个系统的互相配合为上层的业务层提供个性化的搜索数据。
不同的业务对应的搜索排序结果不同,阿里搜索引擎中排序部分是通过类似链式处理的方式实现的,内部称为排序链。排序链是由不同的用户特征对应的算法插件组合而成,算法插件是单独存在的,可以根据具体情况组合到不同业务的排序链中。目前在线上运行的排序链有几十条,系统会根据不同的业务、用户、场景、Query 选择不同的排序逻辑
双十一优化
而在双十一这样的高并发活动中,搜索引擎需要保证流量的合理分配,比如搜索结果中不能显示售罄的商品。但是对于一些热门商品,从库存充足到售罄可能是几分钟的时间。为了保证搜索结果的实时性,阿里搜索引擎架构针对这样的场景做了优化,去掉了不能感知业务变化的缓存(业务层),重点优化搜索引擎层的缓存。以商品售罄的场景为例,当商品售罄时,业务系统会发送异步消息通知离线集群,离线集群通过流式计算将更新同步到引擎,而当引擎返回搜索结果时,会在缓存的基础上对结果进行二次过滤,从而保证搜索结果的实时性和准确性。
另外,在今年双十一中,天猫搜索底层第一次使用精确到更新粒度的 SKU(Stock Keeping Unit)引擎代替之前的宝贝引擎,底层引擎索引量较之前翻了几番。天猫从召回逻辑、前端的属性展示、筛选以及搜索结果页到详情页的联动,向用户提供了精确度更高、更细致的搜索购物体验。对于标类产品,基于 SKU 引擎的搜索导购缩短了用户的搜索购物路径,比如搜索 iPhone 5s 后,SKU 引擎会显示对应的销售属性,方便用户选择。此外在 SKU 引擎的基础上,天猫还实现了用户的尺码个性化,在包含确定尺码信息的类目中,如鞋、文胸,天猫可以匹配用户的尺码个性化信息,将适合的商品优先展示给用户。InfoQ 会在后续文章中与相关技术专家剖析 sku 引擎的设计思路与实现,敬请期待。




