使用 EDMX 模型为 Entity Framework 生成类的时候,大小非常重要。默认情况下,模型中的实体越多,生成操作执行的越慢。下面是引自 David Obando 提供的 bug 报告中的一段内容。本文中提到的表格来自于 AdventureWorks 的示例数据库。
如果 EDMX 模型中仅有一个实体类型(SalesOrderHeader),那么具体化需要 840 毫秒(中间值,运行 10 次);但是当 EDMX 模型包含更多模型的时候,例如一个有 67 个实体类型和 92 个关联的模型,同样的测试会消耗 7246 毫秒(中间值,运行 10 次)。
该性能问题在 Entity Framework 6 中存在,同时也能够在 Entity Framework 5 中重现。
根据一个 Reddit 用户对 NinetiesGuy 的处理,你能使用 AsNoTracking 选项作为一种变通。但是这样做能够引发其他的问题。Frans Bouma 响应说“AsNoTracking 意味着实体对象不可以也不能够被用于变化追踪场景,所以实际上是一个只读对象”。
LLBL Gen Pro ORM 的开发者 Frans Bouma 在他的文章《各种.NET ORM/ 数据访问框架的性能》中进一步讨论了这个问题。在该文章中,他阐述了如果打开变化追踪选项,那么 Entity Framework 和 NHibernate 实例化实体所消耗的时间比其他的 ORM 或者手工编码的对象要高出一个数量级。
对于该测试,“每一个操作都包含了一个从数据库中获取 31465 个实体的查询,然后在单独的对象中实例化它们并将其存储到一个集合中。给出的平均时间是在每一个框架上执行 10 次操作的平均时间(忽略这里面最慢的和最快的操作)。
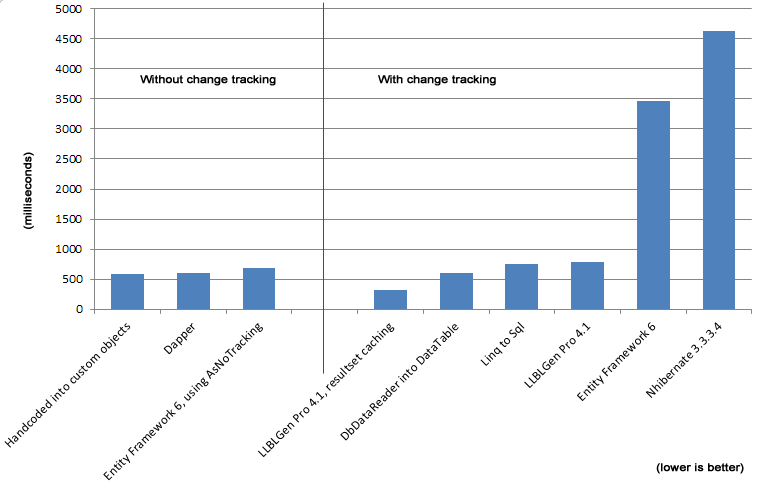
谈到 NHibernate 的结果,他写道:
我提供了在 NHibernate 代码上执行测试时的一个配置文件的屏幕截图,目的是为了查看为什么它会这么慢。当包含一个没有关系的实体的时候,NHibernate 代码耗时停留在 1500ms 左右,Entity Framework 大约是 1100ms。缓慢来自于模型中更多的关系,这正是问题的关键:没有必要让它影响单一类型集合的获取,其他的关系并没有什么作用,ORM 清楚这些内容。
缓慢并不受集合大小的影响,影响速度的是模型大小:关系越多,获取速度越慢。你或许会觉得集合大小也会影响速度,但是你指的是那些愚蠢的 ORM,它们将越来越多的实体存储到一个集合中,这确实会变得越来越慢,因为为了避免集合中的实体重复在向该集合中添加一个实体之前首先会执行 list.Contains(toAdd) 方法,因而存储的实体越多,速度就越慢。但是这与我们所讲的内容并没有什么关联,在我说的场景里面模型中的关系越多,速度就越慢。这就是我选择这个实体和这个数据库的原因:如果一个 ORM 中包含草率的代码,那么它就不能处理正常大小的模型,正如它所展示的。
查看英文原文: Large Model Problems Continue to Plague Entity Framework, NHibernate




