Neo4j 是一款非常流行的开源图型 NoSQL 数据库。它完全支持 ACID 数据库事务属性,由于其良好的图数据模型设计,Neo4j 的速度非常快。对于连接的数据操作,Neo4j 的速度要比传统的关系型数据库快 1000 倍。 Spring Data 是 Spring 的一个核心项目,其下涵盖了如 Spring Data JPA 、 Spring Data MongoDB 、 Spring Data Redis 、 Spring for Hadoop 等子项目,而 Spring Data Neo4j 也是 Spring Data 下的一个重要子项目,它提供了高级的特性以将注解的实体类映射到 Neo4j 图型数据库上。其模板编程模型类似于我们熟知的 Spring 模板,为与图的交互提供了基础,此外也用于高级的仓库支持。该项目旨在为 NoSQL 数据库操作提供便捷的支持。
为了能让读者快速上手 Spring Data Neo4j, Daniel Bartl 开发了一个初学者入门示例,通过该示例,新手可以迅速掌握 Spring Data Neo4j 的核心概念与操作,也能进一步理解图型数据库的设计理念。
该示例是个购物系统,因此要能计算出其他用户的浏览结果供当前用户参考,现在很多电商都提供了这个特性。由于用户与商品之间的联系是很容易使用图来表达的,因此该示例将使用 Neo4j 来表示结点以及结点之间的关系。
Spring Data Neo4j 简介
首先来介绍一下 Spring Data。这是 SpringSource 的一个项目,旨在为 NoSQL 数据库提供 Spring 的编程模型以及便捷性。Spring Data 支持各种 NoSQL 数据库,如 Redis、Riak 以及 MongoDB 等等。它还为 Hadoop 等 MapReduce 实现提供了一个抽象层。
Spring Data Neo4j 起步于 2010 年,你可以在 Neo4j 网站上找到很多有价值的资源。目前最棒的指南就是由该项目的主开发者 Michael Hunger 所编写的“ Good Relationships ”,这本指南提供了免费的下载,也有相应的 HTML 版本。其中有些 Spring Data Neo4j 代码示例位于 Spring Data Neo4j Git 仓库上。此外,O’Reilly 也有一本关于 Spring Data Neo4j 的图书。
为何不使用核心 Neo4j?
当然了,你也可以只使用核心 Neo4j 或是构建自己的集成方案。但如果你过去曾有过其他的 Spring 项目开发经验,那么你就会发现 Spring 的好处了。作为一名软件工程师,你不想关注于实体映射或是事务管理等细节信息。你只要了解这些概念就行了,剩下的事情 Spring 会帮你处理,这相当于 Spring 中的 Hibernate 支持一样:
- 通用的 Spring 与 Spring Data 基础设施。你可以轻松将 Neo4j 嵌入到 Spring 框架所管理的现有应用当中。
- 通过注解来声明结点以及结点之间的关系。
- 代码很容易理解。
- 实体状态由图型数据库所维护。
- 支持 Neo4j 服务器。
如何使用 Spring Data Neo4j?
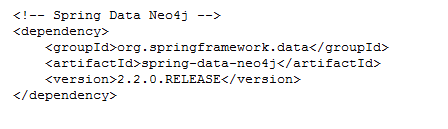
如果使用 Maven,那么你可以通过将如下配置添加到 pom.xml 中将 Spring Data Neo4j 引入到项目中来(除了 Spring 与 Neo4j 的依赖外):
通过如下 Spring 上下文来设置 Neo4j:
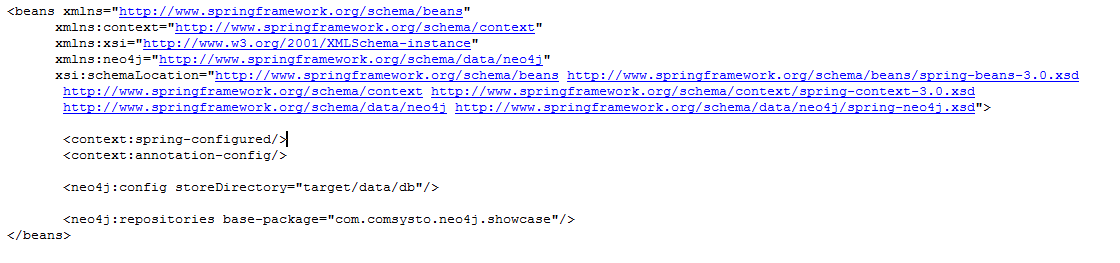
Neo4j 配置的“storeDirectory”属性可以是任意的目录,Neo4j 数据库将会存储在那里。接下来开始实现代表图模型的结点与关系实体。
如何声明结点实体?
创建如下的类来表示结点实体:
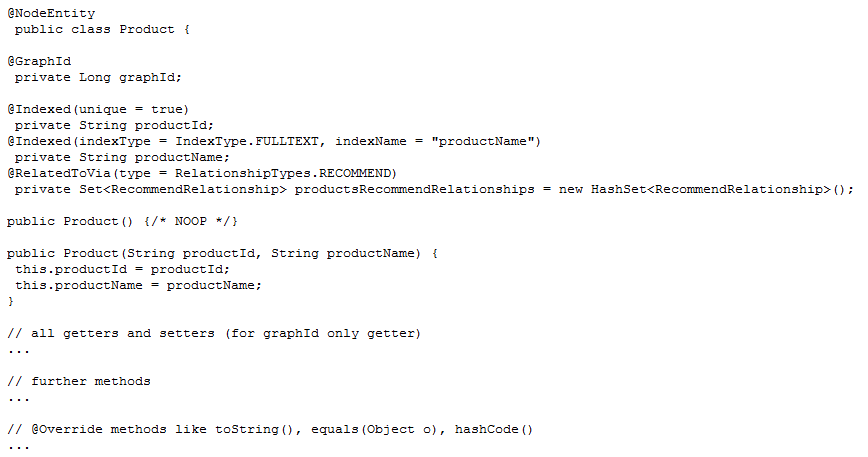
在 Spring 框架中 getters 与 setters 对于属性访问是必须的。你还可以实现自己的额外的方法。一个典型的 Neo4j 实体一般是个经典的 JavaBean,包含了属性以及访问器。此外,我们还建议实现 equals 与 hashCode 方法,因为有时 Spring Data Neo4j 会比较对象来判断结点与关系映射。
如何创建结点实体间的关系?
Spring Data 可以通过 3 种不同的方式来处理结点间的关系,到底选择哪一种取决于两个方面:需要建模的关系类型(1 对 1 还是 1 对多)以及是简单关系还是复杂关系。复杂关系拥有额外的属性。
1 对 1 关系非常简单:父结点通过属性来引用子节点(需要实现访问器),无需注解。Spring Data 会处理所有其他事情。
在简单的 1 对多关系中,你需要在父结点中添加一个包含子结点的集合(参见上述代码示例)。除此之外,你还需要通过 @RelatedTo(type = “relationshipType”) 对集合添加注解,如下所示:

复杂关系能够展示出 Spring Data 强大的图建模能力。你可以通过额外的属性对真实世界的关系建模,为了做到这一点,你需要创建用于存储关系属性的关系实体。此外,还需要通过注解(@StartNode 与 @EndNode)来指定父结点和子结点。参加如下代码示例:

要注意 @Fetch 属性。在很多情况下,在加载完特定的实体后,并不是所有相关的 1 对多对象都需要加载出来。当加载了一个结点实体后,Spring Data 的默认行为只是取得标识相关对象的 ID 列表。这种方式类似于 Hibernate 等框架的延迟加载机制。如果不希望这样,那可以在相应的结点实体上添加 @Fetch 注解。
一般来说,将关系类型作为常量定义在单独的类中是个好做法,因为这些字符串会用在不同类中的不同结点上。我们的图模型在结点间存在两种关系类型,因此这个类如下代码所示:

如何加载实体及实体间的关系?
要想访问实体与关系,我们需要创建自己的接口并继承 Spring 的 GraphRepository 接口,如下代码所示:

如你所见,这个图仓库是个接口,只定义了函数名、返回值与 Cypher 查询(如果需要的话)。这非常方便,因为框架并不需要相应的实现。根据上面声明的参数以及父接口“GraphRepository”,Spring Data 可以创建出与 Neo4j 核心 API 交互的代理对象。要想了解更多细节信息,请参阅关于仓库的文档。如果不熟悉Cypher,那么请看看这个 Cypher 指南。然而,有时自己实现 GraphRepository 也是必要的,在这种情况下,你可以编写一个类并继承该接口。
Spring Data Neo4j 有哪些限制?
Spring Data Neo4j 有如下一些限制:
- 现在,它无法运行同时包含 DISTINCT 与 ORDER BY 的 Cypher 查询。
- 如果遇到问题,日志消息不太直观。
关于示例
该示例展示了一个购物系统的图仓库部分,重点是获得其他用户也查看过的商品。比如说,如果浏览过“奶酪比萨”页面的用户也看过“培根披萨”页面,那么这对于寻找“奶酪比萨”的用户也会很有用。
你可以在 SpringDataNeo4jProductUserTest 类中找到一些测试用例。
如何运行示例?
要想运行示例,你需要先安装好 Maven。如果不熟悉 Maven,那么可以阅读这篇文章来了解Maven 的使用。
示例代码位于github 上,地址是 https://github.com/comsysto/spring-data-neo4j-showcase 。
遇到问题怎么办?
在准备这个示例时,我们遇到了一些挑战,相信你可能也会遇到:
- 小心索引。如果使用 id,那么应该在代码中将其声明为唯一的。
- 如果使用的关系有属性,那么应该使用 @RelatedToVia。
- 初始化所有集合,比如说上述示例中使用的 HashSet。
- 不要将 graphId 作为 id。被删除结点的 graphId 会被 Neo4j 重用,并且在删除前一个后会用来表示另一个对象。
- 对于关系的开始与结束结点使用 @Fetch,否则在加载结点时是不会获取他们的。
- 不要修改 getters 与 setters,因为他们会被框架用来保存值。
- 使用简单的语句来开始 Cypher 查询,然后不断扩展直到达到自己的目标。
- 小心 Cypher 查询中的字符串 转义。Neo4j 核心 API 中的字符串转义与 Spring Data 的不同。
如何扩展示例?
你可以根据自己的需要扩展示例。比如说,可以向结点实体添加更多的属性等。
关于 Neo4j 的学习资源
上文已经提到过,该项目的主开发者 Michael Hunger 所编写的“Good Relationships”一书是最佳的学习资源,该书已经由 InfoQ 发布,感兴趣的读者可以免费下载学习。另外,该书的中文版也将于不久之后发布,欢迎广大读者届时关注。




