在 SQL Server 2012 中,开发者有创建 columnstore 索引的选项。这些索引拥有提供 10x 性能提升和超过传统表 7x 压缩的潜力,但是随之也带来了大量的限制。这其中最重要的是他们将基本表送入只读模式的事实。
SQL Server 2014 中的这个新存储引擎克服了这些限制。该引擎被称为聚合columnstore 索引,它允许高度有效的列有序的数据,同时还允许表在执行DML 操作(例如INSERT、UPDATE 和DELETE)的时候正常运作。
就像正常的聚合索引一样,聚合columnstore 索引定义了数据在磁盘上是如何物理存储的。columnstore 支持的表首先会被组织成称为行组(rowgroup)的片段。每一个行组保存102400 到1048578 行数据。在行组被识别出来之后,它就会被打碎成列片段(column segments),然后对这些列片段进行压缩,并将结果插入到实际的columnstore 中。
在处理少量数据(这里的少量指小于10 万行数据)的时候,这些数据会被组织到一个称为deltastore 的部分。一旦这些数据达到了deltastore 能够将其排出的最小大小,那么它们就会被处理为一个新的行组。你可以从下面的MSDN 图表中查看这个过程:
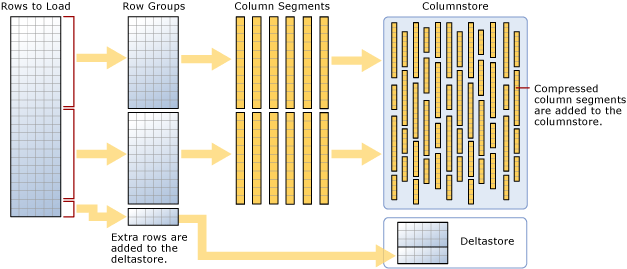
在deltastore 进行转换的时候它会被关闭。但是无论如何这并不是一个全表阻塞操作。在当前的deltastore 因为锁的原因不能访问的时候,会为给定的表创建一个额外的deltastore。如果表是分区的,那么每一个区都会有它自己的deltastore 集。
术语上的注意:Microsoft 现在使用“rowstore”表示按照行和列安排的传统表。deltastore 实际上是一种类型的rowstore。
和之前版本的columnstore 索引不同的是,聚合版本必须包含表中的所有列。这是因为对于剩下的行而言没有其他的堆或者聚合索引去依赖。事实上,聚合columnstore 索引根本不能和其他类型的索引结合。
查看英文原文: Introducing SQL Server 2014’s New Clustered Columnstore Indexes




