Udacity 是一个以提供个性化计算机教育免费在线课程为主的网站,虽然该网站上目前只有 18 种课程,但是它的流量却相当可观,目前在 Alexa 的排名是 11926。
Chris Chew 是该网站的资深软件工程师。日前,他在 Google App Engine 的官方博客上分享了如何使用 App Engine 来构建 Udacity。
Chris 指出:使用 App Engine 的决策,是由 Udacity 的 CTO 和联合创始人 Mike Sokolsky 做出的。连续多周,Mike 必须不断加入新的服务器、管理 MySQL 复制数据库,以满足他们复杂的扩展模式。经过这段时间后,Mike 认为 App Engine 的运维简单方便,很有说服力。
到现在,Udacity 使用 App Engine 已经将近一年了,他们目前的架构如下:
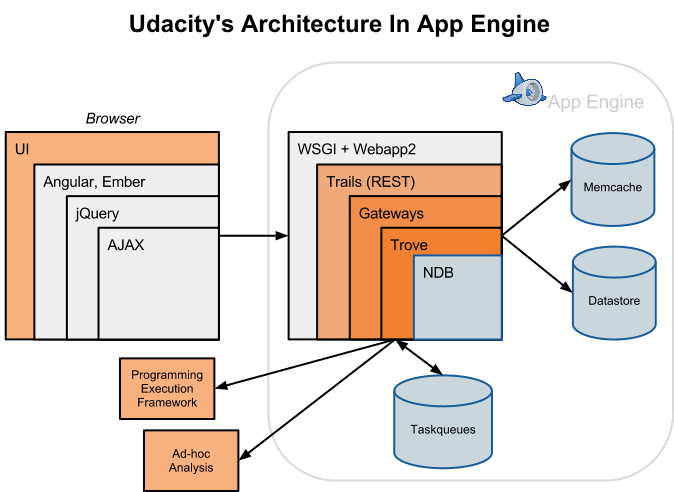
其中:
- 使用 NDB 完成海量数据集的复制。NDB 提供在无 Schema 的对象数据库中的持久化存储,支持自动化缓存、复杂查询和原子事务。
- Memcache
- Python Task Queues API 完成延迟执行、MapReduce、批处理工作。
- App Engine Search API ,索引课程内容和学生的简历。
- Blobstore API ,存储课程视频、简历,导出数据。
- Image API ,生成缩略图。
- MapReduce API ,数据每日使用分析、数据迁移、数据维护。
- Trails 和 Trove,是由 Piotr Kaminski 主要开发的两个程序库。Trails 提供清晰的语法,可在 webapp2.RequestHandler 上创建 RESTful ,同时提供自动化分发。Trove 包装了 NDB,加入常用的属性类型,包括另一层的缓存,存储实体和之间的关系(包括处理中的和 memcache),还有事件“监控”框架,当数据变化时,可完成可靠的带外处理触发。
Chris 指出:图中没有标示出他们为 NDB 打的补丁,这些补丁能创建更好的 hook,类似于现有的 pre/post/put/delete 等 hook。这些自定义的 hook 为“监控”提供了抽象,让代码能对数据层中的变更反应。每个监控的执行都被延迟,并在请求之外完成,以避免增加响应时间。
Chirs 提到:在使用 App Engine 完成扩展的头一年中,他们发现,性能是一件很复杂的事情。响应时间是多种因素的函数,既在他们控制之内,又在他们控制之外。App Engine 确实有“水平扩展”的能力,但是他们发现对于某个给定请求的响应时间常常出现变化,即使是在系统负载很低的时候。因此,他们做了如下事情,以降低延迟变化的影响:
- 使用新的 NDB API ,而不是老的。
- 尽可能使用 NDB.tasklet 协同程序(coroutines),在 RPC 操作阻塞时允许并行处理。
- 不索引默认字段,仅在需要查询的时候才加入索引
- 小心地避免索引热点,只在需要的时候才索引可以预测值的字段(比如当前日期和时间的 DateTime 类型字段,或是枚举类型的字符串字段)。
- 大量使用实体化视图(Materialized view),这样可以限制每个请求尽可能少地查询数据集。
他们在最后一点上做的非常极端,把他们的数据集以去正规化的方式,专门生成为读操作优化的记录。比如,为读操作优化的用户档案记录包括:标准的档案信息、隐私配置、课程注册信息、课程进度和权限。这些数据都放在实体化视图中,只需要一个查询就可以完成。
对于 App Engine,Chris 给出的结论是:
App Engine 是非常完善、可靠的平台,符合为数众多的用户案例和场景。很明显,对于知道如何扩展 web 应用的人来说,它的服务和 API 是专门为他们设计的。……想要完成任何概念验证,都是轻而易举的事情,而且后续的应用扩展工作要比你自己搞一套基础设施要轻松得多。
跟其他平台一样,你也要做出一些让步。使用 App Engine 要做出的让步是:你要不留余地地降低延迟,这才能享用令人赞叹的、支持扩展的服务。这对于我们来说很容易,因为在多次令人兴奋的海量访问时,App Engine 已经有很好的表现。为了完成自己的使命,相对于自己搭建基础设施,我们现在的进度要快得多了。




