InfoQ 中文站曾经报道过 Facebook 的工具文化,Claspin 就是该文化的产物,形象来说,Claspin 就是 Cache 的健康热图。该工具的创始人 Sean Lynch 在一篇博客中分析了它的由来。
Sean Lynch 在 Facebook 担任应用运维工程师,他加入的是产品工程部门新成立的缓存性能团队。Sean 在一篇博客中提到该团队的目标:
处理多种缓存系统的健康问题,同时加快问题处理和解决过程,该过程要先回答这个问题:“这个问题是缓存引起的么?”
最后,Sean 所在的团队开发了一个监控工具 Claspin,使用易于解读的热度图展示缓存系统情况。接下来,Sean 先深入介绍了 Facebook 的缓存工作机制。
Facebook 有两个主要的缓存系统:Memcache,该系统相对简单,复杂度都在客户端;TAO,缓存图数据库,自己完成对 MySQL 的查询。在这两个系统之间,我们有几千个图标,有些将数据收集到 Dashboard 中,展示客户端和服务器收集到的不同的延迟、请求率、错误率统计数据。这些图表和 Dashboard 的大多数都由 Facebook 的“Operations Data Store”支撑,简称为 ODS。一开始,这种机制没有问题,但随着 Facebook 在规模和复杂度方面的不断增加,想知道哪里出了问题变得越来越困难。因此,我开始想:如何把这些已经积累下来的数据、经验和知识用起来,辅助解决问题,让人们只要卡看一眼,就知道缓存现在的状态。
Sean 想到的方法,是把问题可视化。他一开始本打算用类似于交通信号灯的方法,但没多久他就意识到:这种简单的双向工具不能完全确定某些东西是否出了问题。
因此,我开始想如何同时把所有相关数据放在一个图表里面,同时我们还要根据经验知道:当前这些指标的值是否需要我们担心。首先,尝试着写一个命令行工具,列出所有的主机和关键指标数据,以“糟糕程度”排序。我对于“糟糕程度”的定义是:根据每个指标各自的值给主机排定顺序,然后,根据元组(by tuple)排定次序和主机。比如,某台主机在超时和 TCP 重新传输方面排第一,但在请求率方面拍第十,它的排序主键就是(1,1,10)。同时也要展示主机所在的机架,这样当某个机架中的一些主机出问题时,很快就能发现问题。这么做的输出是很多文本,而且需要了解内情的人解读。虽然这让我的工作变得更容易,但这并不是我想要的。
最终,Sean 打算使用热图(Heatmap),不过他一开始并不清楚:以这样二维的方式展示数据对于用户是否有意义。
很明显,我们希望热图中每个像素代表一台主机,机架们能组合在一起。然而,我们的机架中的主机数目并不一样,当每台主机中的指标有十来个时,也不清楚如何为各个主机标示颜色。当时,我们内部已经使用了热图,展示一组主机中的单个统计数据,这些主机组织成集群和机架,不过布局很松散,而且那么多服务器也无法放到同一个页面中。由于已有的热图是通用工具,而且颜色基于现有的统计数据,无法区别何为“好坏”。最后,我认识到:我们真正关心的,是某台主机是否出现问题。所以我决定,用一台主机“最热”的统计数据来标示它的颜色,热度来自于对预先定义的阈值的计算。做法很简单,但是让我们能把以前的经验和知识中关于什么是不好的数值编码到这个视图中。缺少某个统计数据的主机被标示为黑色,说明主机可能宕掉了。尝试过多种安排、聆听多人反馈后,我决定为每个集群绘制一张独立的热图,用机架数字排序,每个机架用类似“贪吃蛇”的样子绘制成垂直的方式,这样机架的展示就是连续的,即使他们可能在上面或者下面弯转。机架的名字按照数据中心、集群、行这样的方式自然排序,哪个层次上出了问题,就很明显了。
在一个朋友的建议下,Sean 使用“Claspin”作为这个工具的名字,Claspin 是一种蛋白质,监控细胞中的 DNA 损伤。
我们用 Claspin 可以立即把海量信息可视化,让我们更容易发现问题和模式。在一个 30 寸的屏幕上,我们可以同时放下 1 万台主机的信息,它们的颜色由 30 多个状态数据决定,并在秒级或分钟级实时更新。这个数据量很大,Claspin 使用了标准的 Facebook 组件来处理,收集所有服务器端状态,并把它们发送到浏览器,颜色的判定通过 JavaScript 完成,热图的绘制用 SVG。即使出现一个问题,也很容易发现,因为特定的问题会在屏幕上有特定模式。
Sean 接下来在博客中展示了一些图片:
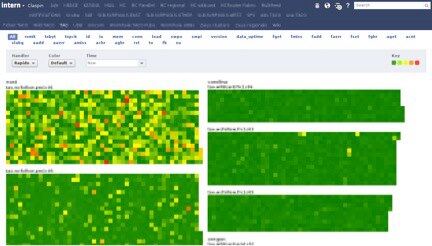
上面的标签页包括不同视图,大多数是 Claspin 监控的不同服务。下面的蓝色按钮让用户可以用单一状态来给主机上色。
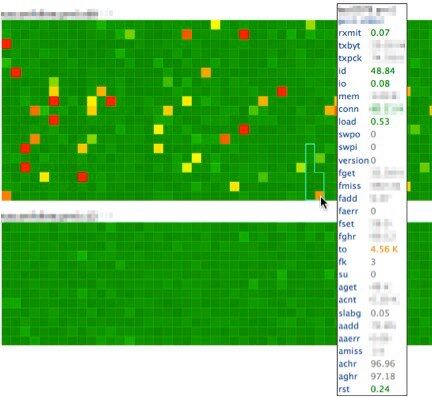
鼠标箭头放在某个主机上,就会展示出该主机所属机架,并弹出关于主机名、机架号码、以及所有 Claspin 对该主机监控的数据,同时数值文本的颜色也会根据 Claspin 对该状态的阈值设置有所不同。上图中,你可以看到下面被包起来的一个机架,展示出不同的方向。没有阈值定义的状态是灰色,但是是放在一起的,这样就可以知道为什么某个主机有很高的超时等等。
此后,Sean 其他成员改进了 Claspin,加入了对更多后端和自定义调色板的支持。这对于无法区分红绿颜色的人很有帮助,对无所谓好坏的值也是有帮助的。

他们还把配置文件放到版本控制文本文件中,而且可以同时传播更新。配置变得更为用户友好后,使用 Claspin 监控服务的团队数目翻了一番还要多。
最后,Sean 提到了 Claspin 带来的好处:
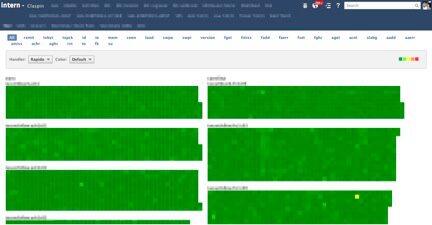
当我刚刚部署 Claspin 时,上面的图中有很多红色。Claspin 帮助很多人更易于发现问题,从而让我们发现“黄色”预警,并阻止更多“红色”出现。在我看来,验证统计数据和阈值选择是否正确的最好方法,就是当红色出现之后,通过改善服务,全部变成绿色。
微博上,有人分享了 Pinterest 创始人本·西尔伯曼在光速创投夏令营分享的创业经验:
雇请优秀的人,即便还没有明确定义好的工作(Hire Great People, regardless of if you have a defined role for them):他对优秀的人的定义是,可以在不同角色上有附加价值、能在你现在和今后遇到问题时提供解决方案。
毫无疑问,Sean Lynch 就是一位优秀的人。




