
基于 X-Ray 的安检方案能够有效的解决物体之间相互遮挡等问题。与传统的人工开箱检查的方式相比,X-Ray 安检仪的效率更好,检测精度更高。
背景介绍
X-Ray 检验系统已经成为机场、火车站、汽车站等交通枢纽中必不可少的重要安全设备。目前,我们能够使用 X-Ray 安检设备能够对旅客的行李进行快速扫描,然后根据被扫描物品的材质,重构出相应的图像;因此,基于 X-Ray 的安检方案能够有效的解决物体之间相互遮挡等问题。与传统的人工开箱检查的方式相比,X-Ray 安检仪的效率更好,检测精度更高。
通过 X-Ray 安检设备可以有效的检测出乘客的行李中是否包含有枪支、刀具以及放射性等对其他乘客可能造成伤害的物品。通常条件下,X-Ray 安检可以满足交通枢纽中的安全检测需求,安检人员通过观察 X-Ray 设备所返回的画面,能够清楚的判断出乘客的包裹中是否含违禁品、违禁品的位置和种类。
由此可见,所有的判断和决策工作都需要有人来完成,因此也就会带来一些不稳定的因素产生。如安检人员的从业经验、专业水平以及精神状态等,这些因素都会影响违禁品的检测速度和准确率。随着城市的日益扩大,交通和物流也都呈现出爆发式增长的态势,X-Ray 安检仪与安检员的方式已经逐渐无法因对日益增长的客流。长时间高强度的工作,必然会导致安检员疲惫,造成一些漏检或误检,从而产生一定的安全隐患。常用的 X-Ray 安检设备如图 1 所示。

图 1 机场 X-Ray 安检设备
为了进一步缓解目前 X-Ray 安检方案对人工的依赖,科研人员从多软件、硬件等多个不同的角度对现有的方案进行了优化。例如,Oertel 等人使用新的 ALISA 组件模块实现了对 X 光安检违禁品图像中的感兴趣区域进行自动检测和定位。Abidi 等人设计了一系列线性和非线性伪彩色图并应用于单能 X 光安检机。最近,Akcay 等人通过迁移学习将深度卷积神经网络应用于 X 光图像的分类和检测中,实现了对 6 种违禁品 88.85%的平均检测精度。
同时,国内许多安检公司和研究机构都展开了对基于 X 光图像的违禁品自动识别和检测的研究工作。2018 年,科大讯飞研制出的全球首例 X 光安检机图像人工智能识别系统,获得了 2018 全球人工智能产品应用博览会金奖,其基于深度学习算法,通过训练可自动对 X 光安检图像中的违禁品进行识别、报警和统计分析。2018 年 9 月,上海复旦微电子集团推出了一款智能识别 X 光机系统,利用深度神经网络模型实现对 X 光图像中的各类物体进行检测,并通过软件和硬件一体化的加速平台实现每张 X 光图像 60 毫秒的处理速度。2019 年 2 月,海康威视发布了智能安检系统,将安检联网,智能识别,信息融合等概念引入到智能化安检的发展方向中,为 X 光安检图像的自动识别和检测从研究到实际应用提供了一个生态的解决方案。
随着深度学习、图像处理等技术的不断发展,基于卷积神经网络的图像视觉算法逐渐在智能安防、无人驾驶、视频分析等任务中广泛使用。基于深度神经网络的在违禁品检测任务中也取得了较好的效果。然而,现有的检测算法大部分是基于 CNNs 模型进行构建的,因此只能对局部信息进行建模。
但是,在违禁品检测任务中,我们需要让模型获取到更多的全局信息,来辅助模型最后的判断和分析。目前,Vision Transformer (VIT)开始在视觉任务中应用,并且取得了较好的效果。与基于卷积神经网络的深度学习模型不用,VIT 模型借助 Self-Attention 机制能够从图片的整体区域,提取出更加鲁棒视觉特征。此外,VIT 能够更好的建模图像的浅层和中层特征,进而从整体上提升模型的性能。
针对违禁品检测任务自身的特点,如:目标尺寸差异较大、部分目标长宽比例异常、目标重叠、背景信息复杂等问题,我们设计了一种基于 Vision Transformer 的高精度目标检测算法。为了验证系统的有效性,我们设计了多种实验,并从 mAP、precision、recall 等指标对模型进行分析和比较。
方法设计
在违禁品检测任务中,我们需要从 X-Ray 扫描的结果中对违禁品进行检测,一般情况下违禁品与其他物品具有较大的视觉差异,因此安监人员可以快速准确的判定行李中是否含有违禁品,以及违禁品的种类。
根据这一先验知识,如果我们可以在现有的目标检测算法中引入注意力机制(Self-Attention Mechanism),就可以较少 Anchor 生成的数量,从而降低计算量、提高运行效率,并优化检测结果。因此在本章中,我们借鉴机器翻译领域中的 Transformer 结构,将带有注意力机制的 Transformer 整合到目标检测算法中,设计了一套基于 End-to-End 的违禁品检测算法。
从本质上来说 Transformer 其实是一种自注意力机制 (Self-Attention)的特殊化表示,该结构最早由 Google 研究院的机器翻译组提出,并在自然语言处理领域被大量使用。使用 Transformer 模型来替代原有的 RNN 和 LSTM,从而解决这了循环神经网络结构由于梯度爆炸而无法构建较长的历史关系的问题。
Transformer 的目的是从全局信息中选择出对与当前任务更加具有关联性的特征,因此该结构无论是在自然语言处理还是计算机视觉领域中都可以更好的利用全局信息;此外,该结构在构建特征之间的相互关系时,能够仅使用自身数据之间的结构性关系,而无需使用更多的额外信息。因此 Transformer 更加擅长处理文本与图像信息中的长距以及多层次之间相互依存关系。Transformer 的结构如图 2 所示。
从结构中可以看出,Transformer 中主要包含三个部分,分别是:Encoder、Decoder 和 Positional Encoding。我们所提出的算法首先需要使用卷积神经网络从图片中提取特征,然后使用 Postional Encoding 结构对特征进行编码,从而获得位置编码信息,然后将特征和特征的位置编码信息一同送入 Transformer 中的 Encoder 中,Encoder 对送入其中给的所有信息进行抽取和建模,并在 Mulit-Head Attention 中以 Key-Value 对的形式对每一层的信息进行插值;
然后,Transformer 中的 Decoder 对 Encoder 输出的信息进行解码(以查询的方式进行特征解码),并产生一组对感兴趣区域的预测结果,包括类别预测信息和图像的边框回归结果。在进行模型前项传播或部署测试时,我们只需要将图像进行特征提取,然后将特征和查询向量输入到 Transformer 中,就可以得到最后的预测结果。
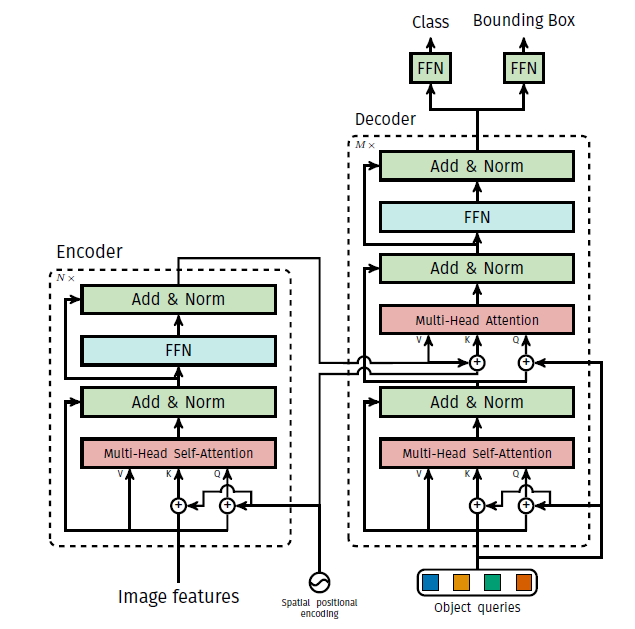
图 2 Transformer 基本结构
算法的总体结构如图 3 所示,我们在训练过程中选择简单的深度神经网络作为特整提取网络,具体的提取方式与通用的目标检测算法相同,我们将一幅图片进行降维,降维尺度为 32 倍。在 Encoder-Decoder 阶段,首先需要将特征使用 1x1 的卷积层进行特征结构化,然后将位置编码信息与结构化的特征一起送入到 Transformer 中,最后通过一个前项传播模型(FFN)输出最终的预测分类结果和边框坐标。
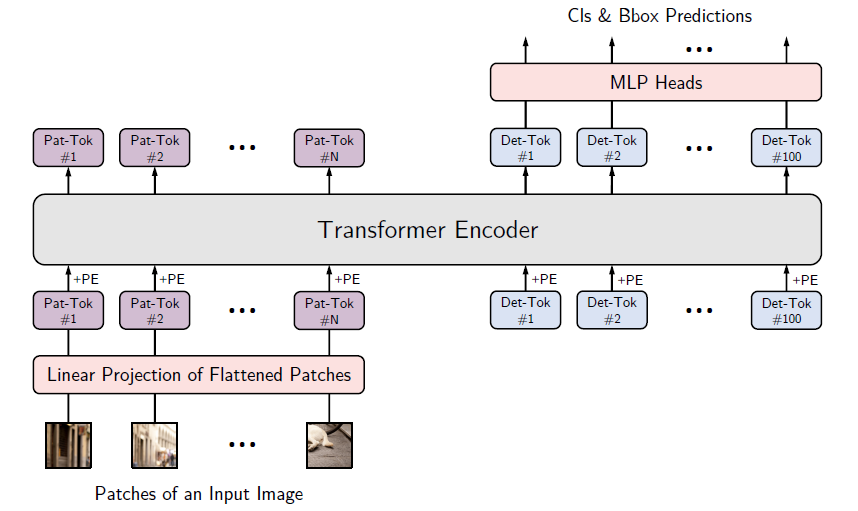
图 3 算法的总体结构
实验分析
在本章节中,我们将使用收集好的 X-Ray 违禁品数据对模型进行训练,然后与现有的目标检测算法的结果进行对比分析。
在本实验中,我们使用 X-Ray 违禁品数据进行训练和测试,首先需要将数据按照一定的比例分开,其中选择 7469 张图像作为训练集,1412 张图片作为测试集。其中带有 Gun 的图片为 4978 张,带有 Knife 的图片为 3097 张,3084 张包含 Wrench,5370 张带有 Pliers,1132 张图片中有 Scissor。
我们将所提出的基于 Transformer 的违禁品检测算法与常用的目标检测算法如 YOLO V3、SSD 等算法进行对比,具体结果如表 1 所示。为了进行更加客观的模型性能对比,我们采用的准确率(Precision)、召回率(Recall)和平均准确率均值(mAP)三种指标来从不同的方面对模型进行定量评价;在模型性能方面,使用模型的参数量、计算量以及运行时间来进行分析。
从结果中我们可以看出,本文所提出的方法在 Precision、Recall 以及 mAP 等多个方面具有极大的优势。我们的所提出的方法在参数量为 Faster RCNN 的 16%的情况下,mAP 增长了 6.9%;与 SSD 相比,我们的算法 mAP 增长了 23.1%,然而体积仅仅是 SSD 模型的 19.2%。对比实验结果表明本章中提出的基于 Transformer 的违禁品检测算法具有较好的性能,适用 X-Ray 违禁品检测任务。
表 1 模型性能
我们将所提出的算法进行实际测试,并展示了部分可视化结果,具体如图 4 所示。从图中可以看出,本项目所提出的方法检测边框更加贴合目标,并且对于复杂背景等挑战,具有较好的鲁棒性。
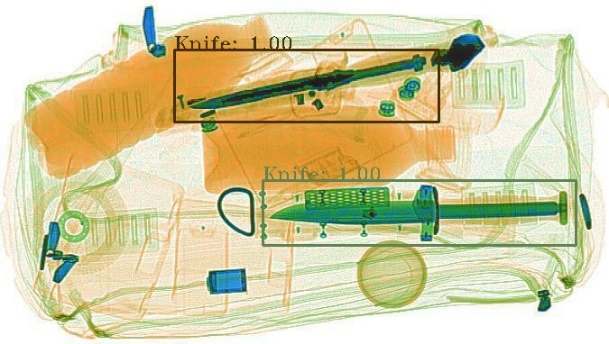
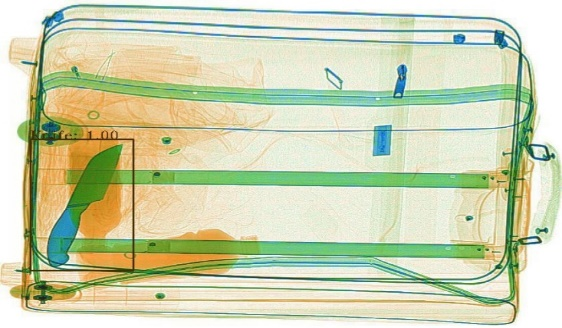
图 4 可视化结果图
总结
我们提出了一种使用基于 Transformer 的目标检测算法,并用于违禁检测领域。我们首先介绍了与 Transformer 高度相关的注意力机制,然后重点描述了 Transformer 的内部结构和算法的整体流程。最后,我们将所提出的算法在 X-Ray 数据集上进行训练,并与经典的目标检测算法进行对比,实验结果显示,本文所提出的方法可以大幅优化结果的检测精度。
作者介绍
沙宇洋,中科院计算所工程师,目前主要从事人脸识别以及无人驾驶等相关方向的研究和实际产品开发。
陈扬,中科苏州智能计算技术研究院,目前从事缺陷检测以及三维重建等相关方向的研究和实际产品开发。




