
随着每天万亿级别的业务数据流向数据湖,数据湖的弊端也逐渐凸显出来,例如:
数据入湖时效性差:数据湖主要依赖于离线批量计算,通常不支持实时数据更新,因此无法保证数据的强一致性,造成数据不及时、不准确;
查询性能差:在传统架构下,数据湖的查询速度较差,小时粒度的数据查询往往需要数分钟才能得到响应,在多个业务方同时执行数据湖查询任务时,查询响应慢的劣势更加明显;
查询体验差:数据存储在多个地方,在进行联邦分析时需要将数据从数据湖中搬迁到数据仓库平台,这会增加分析链路的长度,同时导致数据的冗余存储。在进行常规查询时,需要熟练查询多种数据库,学习成本极高;
场景融合不足:数据湖单一组件,无法满足目前的海量数据处理诉求,例如在批处理和流处理等场景下的融合能力有限。
技术选型思考
在旧架构中,数据湖组件选择的是 Hudi,查询层使用 Hive on Spark 进行查询,所有业务方的查询上层封装了 Metabase,在 Metabase 平台上编写 Hive SQL,即可通过 Spark 引擎执行计算,获取数据湖中的计算结果。
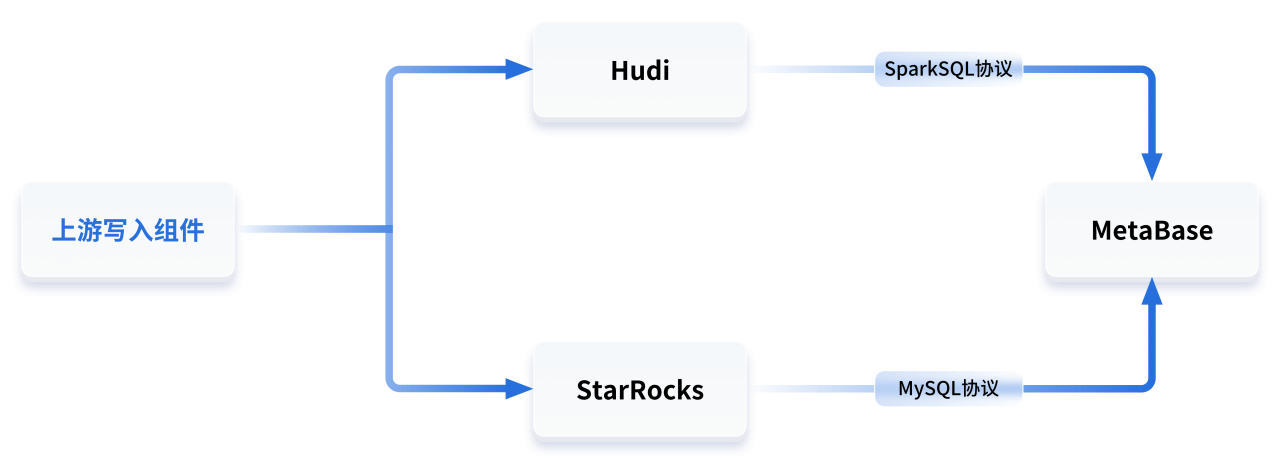
这个架构的缺点很明显:
数据湖和数据仓库是分开的两个东西,没有办法关联查询;
业务方需要同时掌握 SparkSQL 和 MySQL 两种能力,学习成本高;
SparkSQL 查询效率慢,稳定性差,资源占用高;
Spark 引擎在跑 Hive SQL 时,会偶发触发 BUG 导致查询失败,需要手工重试才能得到结果,用户体验较差。
白山云大数据团队在寻找新的架构方案时,主要关注以下几个方面:
在数据查询方面,查询效率、查询体验要显著高于传统的 Spark 引擎;
在资源利用上,查询数据使用的 CPU 和内存要远低于传统的 Spark 引擎;
可拓展性高,支持动态扩缩容;
在学习成本上,传统的 Hive SQL 相较 MySQL 语句有较高门槛,如果能兼容 MySQL 协议来检索数据湖的查询,可以极大降低数据湖的查询门槛。
基于以上需求,大数据团队选择了多个数据湖相关的查询组件,对性能、资源、稳定性等方面进行测试比对,最终选择了 StarRocks 作为数据湖的查询引擎。
如何实现架构落地
在确定了技术选型后,接下来就要考虑如何平滑地将架构落地:
StarRocks 数据湖专用集群建设
白山云大数据团队有多个数据湖 Hudi 集群,并且数据湖 Hudi 组件使用 HDFS 作为底层存储。StarRocks 如果要连接数据湖,则需要将 core-site.xml 等配置文件放到 conf 目录,并且对文件名有强依赖,因此不能做到一个 StarRocks 集群连接多个 HDFS 集群。
所以在 StarRocks 建设时,大数据团队针对每一个 Hudi 集群都建设了一个单独的 StarRocks 集群作为查询引擎。在节点选择上,由于 Hudi 专用的 StarRocks 集群不存储数据,因此不挂载硬盘。为了提高资源利用率,并减少一些数据传输时网络 IO 的消耗,大数据团队选择了和 HDFS 的 Data Node 节点混合部署。
新旧架构并行运行
在 StarRocks 集群建设完成后,大数据团队基于以下考虑,选择了新旧架构并行运行的方案,来保障整个架构的平缓更替:
由于新旧架构并行,可以使用相同的查询语句分别在新旧架构中运行,从而精准得到新旧架构的性能和资源消耗对比;
有了充足的时间推广新架构,在内部开展新架构的使用培训,并在运行过程中让业务方充分感受到新架构的高性能优势,自主切换到新架构中;
并行运行期间,如果新架构发生了预期之外的问题导致故障,可以快速回退到旧架构中,保证了线上服务不受影响。
此时的架构如下:
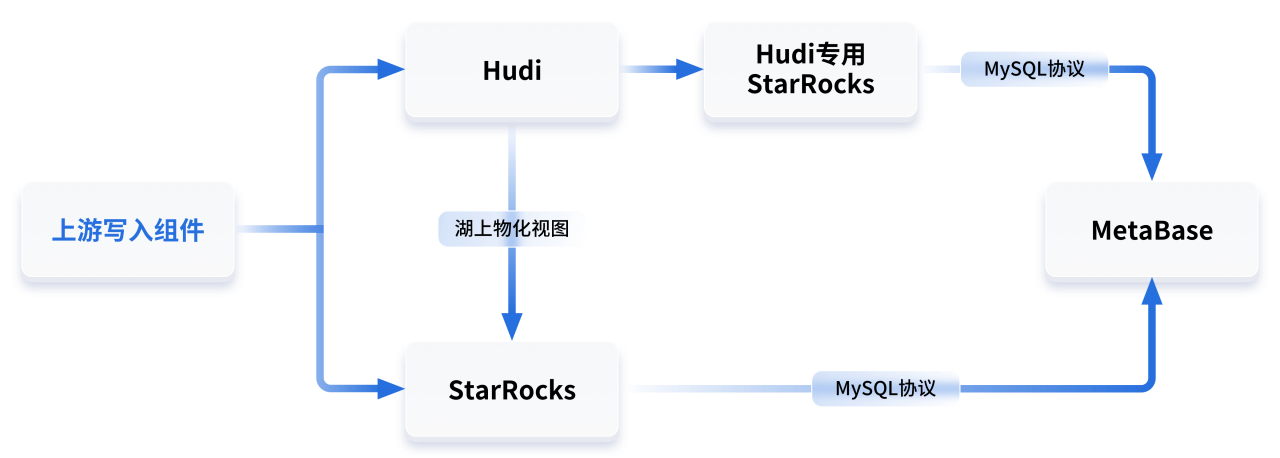
在运行过程中,新架构的优点也集中展露:
用户无需再学习 SparkSQL 的语法,只需掌握 MySQL 协议即可访问两种数据源;
数据湖和数据仓库的连接更加紧密,通过 StarRocks 湖上物化视图的功能,数据湖的数据可以将聚合结果存入 StarRocks 进行物化加速;
提供了联邦分析能力,由于数据湖和数据仓库都是使用 StarRocks 进行查询,因此可以实现同一条语句将两种数据源的数据混合计算的联邦查询;
StarRocks 在查询 Hudi 时不论是性能、稳定性还是资源占用方面都有很大的优化;
一些 StarRocks 数据仓库写入、查询压力较大的表,可以挪到数据湖中存储,然后继续通过 StarRocks 对外提供查询,实现业务方无感知的平滑迁移。
我们使用相同的查询语句在不同架构中多次执行,性能对比结果十分明显:在环境内存资源占用上 SparkSQL 是 StarRocks2.8 倍,在环境 CPU 利用上 SparkSQL 是 StarRocks3.78 倍;对于 SQL 内存消耗、SQL CPU 消耗时间上 SparkSQL 也要比 StarRocks 高出许多;对于 SQL 首次执行时间,StarRocks 要比 SparkSQL 快近 3 倍,SQL 再次执行时间 StarRocks 的速度也要比 SparkSQL 快近 6-8 倍。
滚动裁撤旧架构资源
在新旧架构长达数周的并行运行后,新架构的性能、稳定性、资源消耗等方面优势已经体现出来了,此时开始滚动裁撤旧架构的资源,让业务方只能使用 StarRocks 这一种查询引擎查询 Hudi 集群。
新数据入湖
在 StarRocks 作为数据湖的查询引擎得到大范围推广后,下一步的操作就是进一步将湖仓一体的架构体现,将其他 StarRocks 集群中对延迟要求低或者数据体量大的表写入数据湖。
对于业务方,通过 StarRocks 进行数据查询的整个流程无需改变,依旧使用 MySQL 协议查询 StarRocks 数据库。
带来的价值
资源节约:我们有多个机房和多套 Hudi 集群,在全面使用 StarRocks 替代 SparkSQL 查询 Hudi 集群后,资源消耗节省 70%;
查询性能提升:在无并发场景下,查询效率提升 3-8 倍;在并发执行场景下,查询效率提升 10 倍以上;
学习成本降低:旧架构查询数据湖需要掌握 HiveSQL 语法,新架构只需了解 MySQL 语法;
湖仓一体的深入融合:在旧架构中一些无法满足的业务需求可以得到满足,例如量级无法承接的数据可以转存到数据湖中,通过 StarRocks 集群进行查询;
联邦分析:通过 StarRocks 统一数据查询引擎,可以实现跨数据源的联邦分析场景,例如一半在 Hudi 一半在 StarRocks 中聚合到一起进行联邦分析。
未来探索方向
在湖仓一体方案稳定运行后,大数据团队将针对 StarRocks 数据库进行以下探索:
统一 StarRocks 集群:前面提到了目前受限于配置文件问题,一个 StarRocks 集群只能连接一个 Hudi 集群。和 StarRocks 社区沟通后了解到,未来 StarRocks 中 Catalog 的配置不再局限于物理机的配置文件,而是在 Catalog 的创建语句中动态传入,一旦这个方案上线,就可以实现一个 StarRocks 集群连接多个 HDFS/Hudi 集群,甚至可以实现跨 Hudi 集群的联邦查询。
存算分离探索:StarRocks 3.0 正式发布了存算分离 CN(Compute Node)节点,未来我们在湖仓一体的 StarRocks 集群中计划正式引入 CN 节点,在执行大查询时,快速扩容多个 CN 节点加速查询,在没有查询时将 CN 节点释放,减少资源占用。
湖上物化视图探索:StarRocks 支持湖上物化视图功能,针对数据湖的数据可以做到原始数据存储在数据湖中,同时聚合结果存储在 StarRocks 中。当查询条件满足物化结果,可以直接将查询改写到物化视图中,实现极速查询。
更多数据源探索:StarRocks 的 Catalog 模块除了 Hudi 等数据湖组件外,在 3.1 版本正式接入了 ES 数据库。白山云大数据团队计划构建 ES 专用的 StarRocks 集群,来将 StarRocks 的极速查询能力赋能到更多数据库中。




