
当今企业面临数字化转型和智能化升级的挑战,作为承载了庞大算力的云基础设施,成为企业打破这种挑战的重要支撑。
过去所说的算力,一般都是以 CPU 为主的传统算力。经过数十年发展,已经形成了庞大的市场规模。
随着产业智能化升级的深化,大家再提算力的时候,注意力就会更多的放到以 GPU 等为主的智能算力上来。
在过去几年,智能算力高速增长,已经快占据到算力总量的一半,和传统算力平分秋色。
这给产业智能化提供了充足的算力支持。比如自动驾驶、生物医药、行业大模型、智算中心等行业和领域,走在了智能化升级的前沿。这些行业的快速发展,也将反过来拉动了智能算力规模的高速增长。
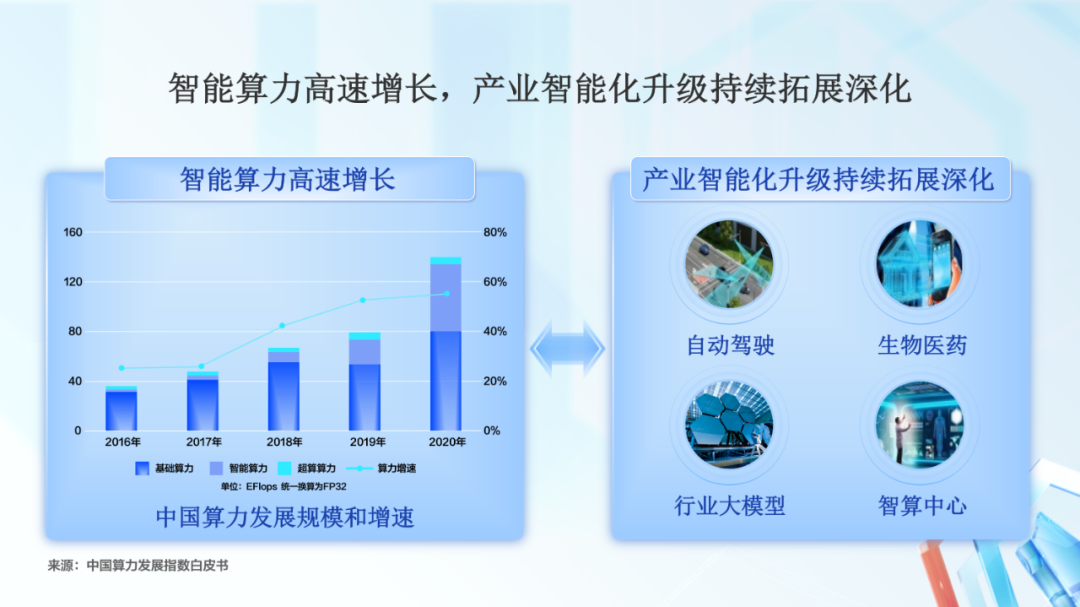
算力和产业的相互影响,促进了双方都在快速发展,不断变化。这也说明需要构建新型智能计算基础设施,支持产业智能化的深化。
那智能算力的未来应该是什么样子,才能更好地满足产业智能化升级的需求呢?
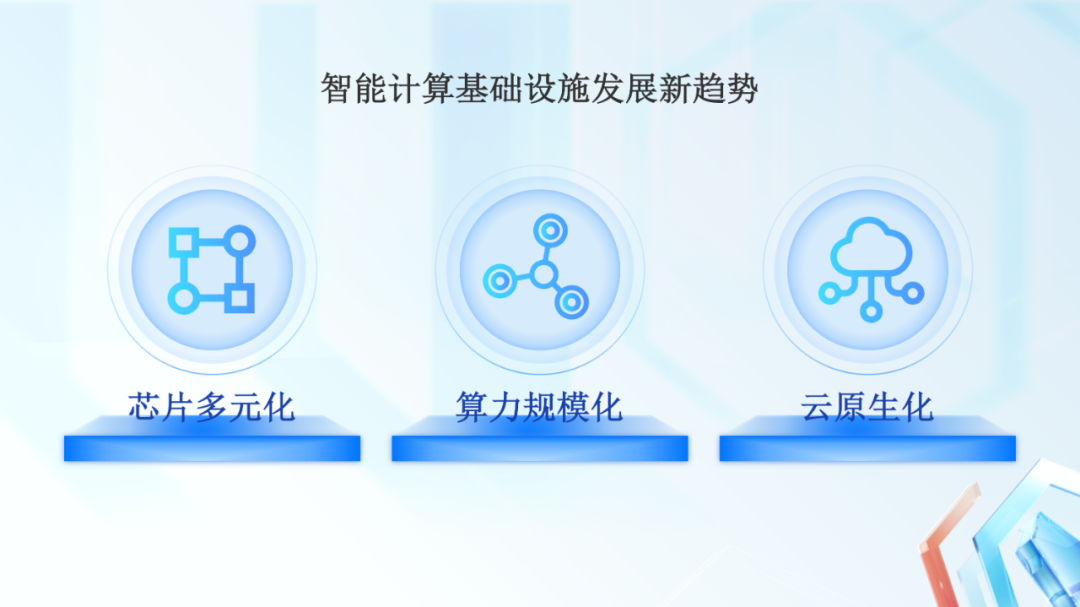
百度智能云认为,随着 AI 应用场景更加丰富、超大模型不断的出现、云上 AI 任务的管理复杂性越来越高,芯片多元化、算力规模化、以及云原生化,将成为未来智能算力发展的重点方向。
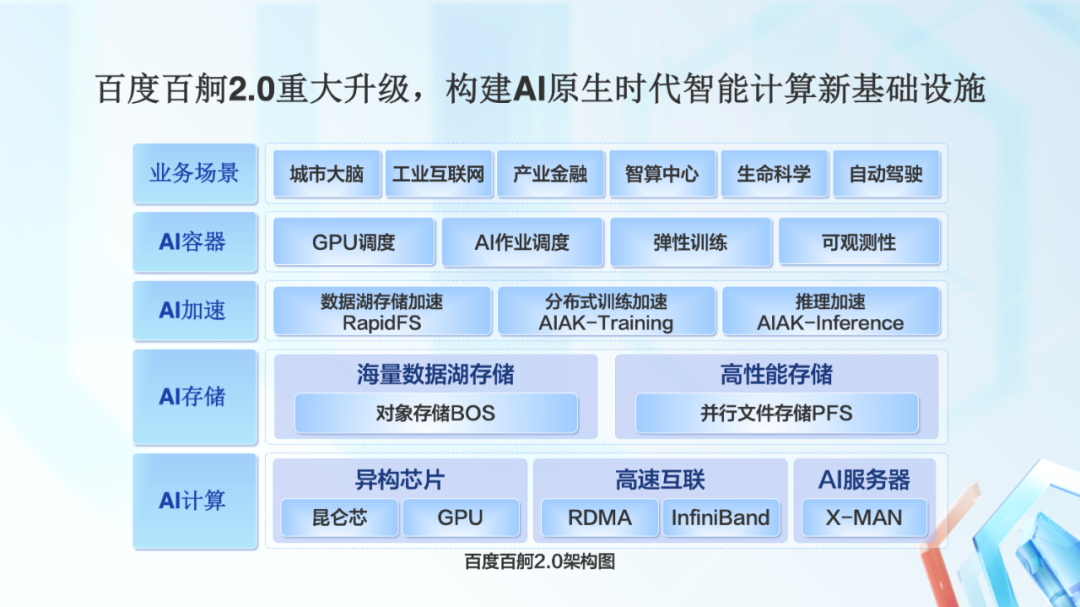
为了建设 AI 原生的云计算基础设施,我们去年推出了百度百舸·AI 异构计算平台。基于产业智能化和智能算力发展大趋势,我们今年升级发布了 2.0 版本。
百度百舸 2.0 在 AI 计算、AI 存储、AI 容器等模块上,能力进行了增强,功能进行了丰富,同时全新发布 AI 加速套件。
AI 加速套件,通过存训推一体化的方式,对数据的读取和查询、训练、推理进行加速,进一步提升 AI 作业速度。
首先我们来看 AI 相关的计算和网络部分。
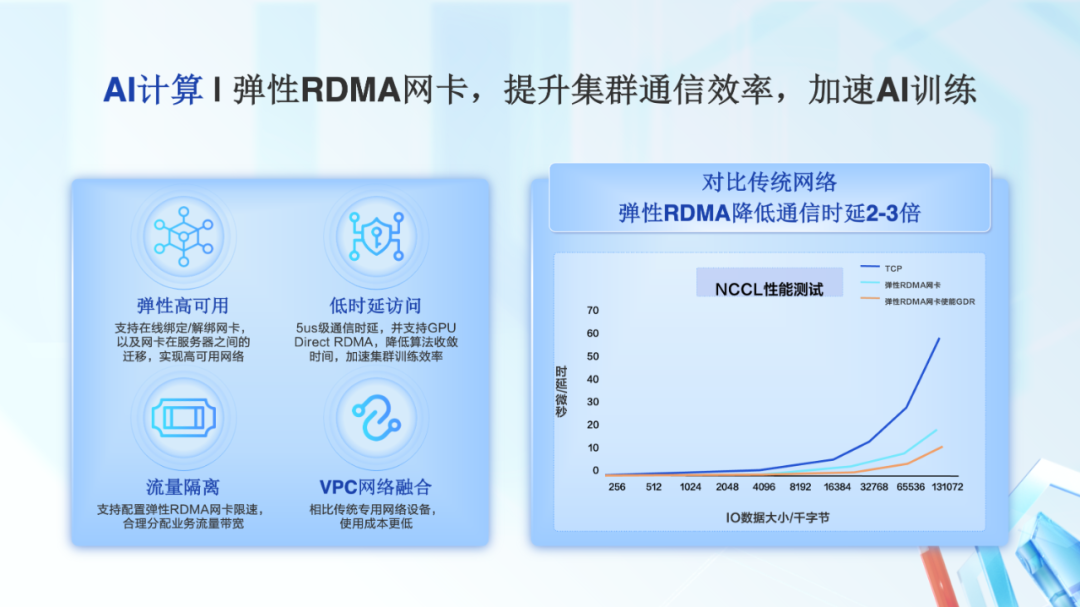
为了提升集群通信效率,我们全新发布了弹性 RDMA 网卡。相比传统专用的 RDMA 网络,弹性 RDMA 网络和 VPC 网络进行了融合,使得用户的使用成本更低。相比传统的 TCP 网络,弹性 RDMA 的通信延时降低了 2-3 倍。同时,弹性 RDMA 还支持 GPU Direct RDMA,进一步提升 AI 集群训练速度。
百度持续投入 AI 的全栈能力建设,昆仑芯是其中重要的部分。
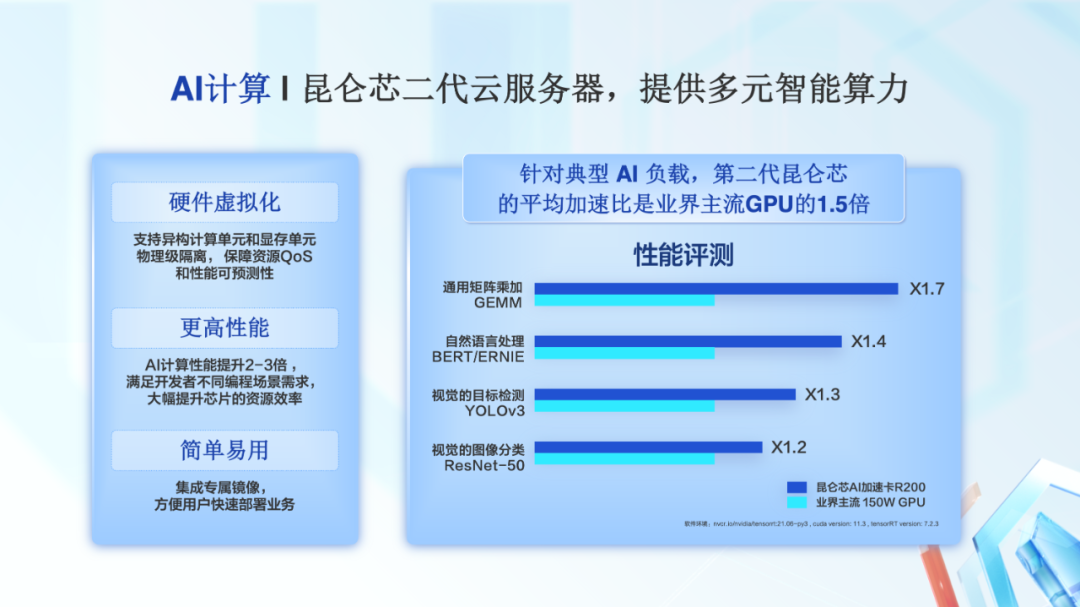
今天,我昆仑芯二代的云服务器也发布上市,为用户提供多元化的智能算力。昆仑芯二代采用了 XPU-R 架构,支持硬件级别的虚拟化,同时为用户快速地使用昆仑芯二代,我们提供了专属镜像。
针对典型 AI 负载,第二代昆仑芯的性能,相比一代提升了 2-3 倍,平均加速比是业界主流 GPU 的 1.5 倍。
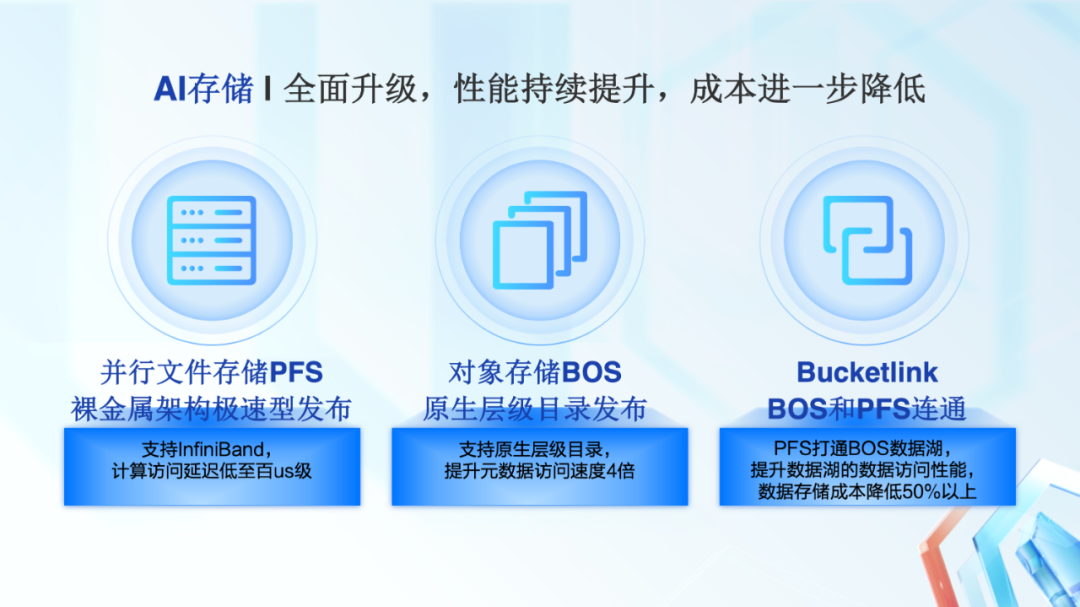
在 AI 存储部分,百度百舸 2.0 进行了全面升级,提升性能的同时降低使用成本。
我们全新发布了并行文件存储 PFS 的裸金属版本,支持 IB 网络,可将计算对数据的访问延迟降低至百 us 级别。
同时,对象存储 BOS 新增了原生层级 namespace,可以将元数据访问速度提升 4 倍以上。
在存储性能大幅度提升的同时,我们通过 Bucketlink 将 PFS 和 BOS 打通。这不仅提升了数据湖的访问性能,同时降低数据存储成本。
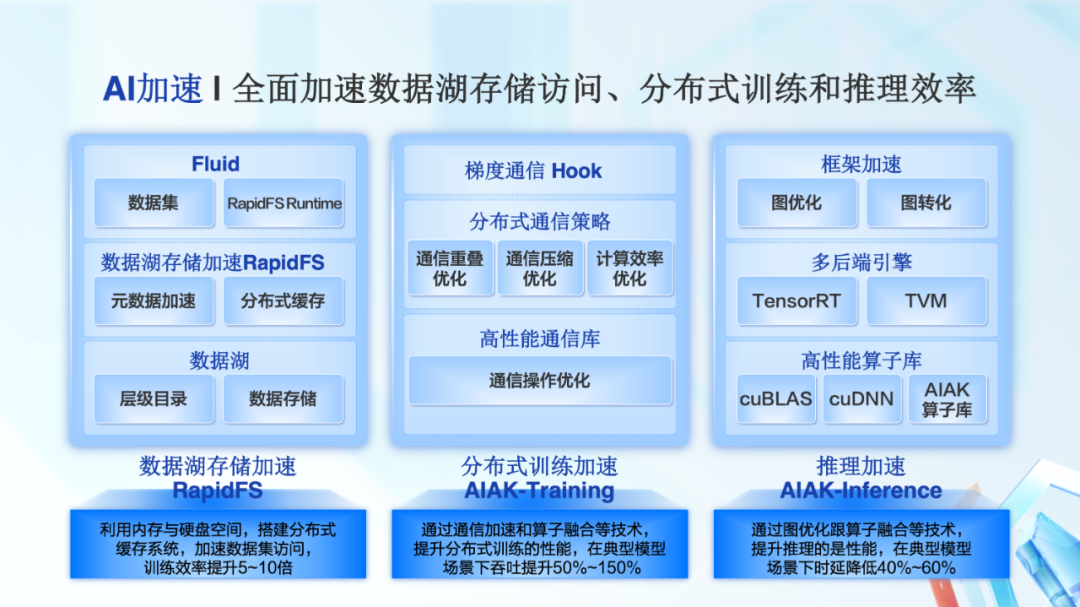
在 AI 加速部分,我们推出的存训推一体化加速方案,全面加速了数据湖存储访问、分布式训练和推理效率。
数据湖存储加速 RapidFS,这是一个分布式缓存系统,可以加速数据集访问,训练效率提升 5~10 倍。
分布式训练加速,能有效提升分布式训练的性能,在典型模型场景下吞吐提升 50%~150%。
在模型完成训练进行部署后,通过推理加速,提升 AI 应用的响应速度。在典型模型场景下时延降低 40%~60%。
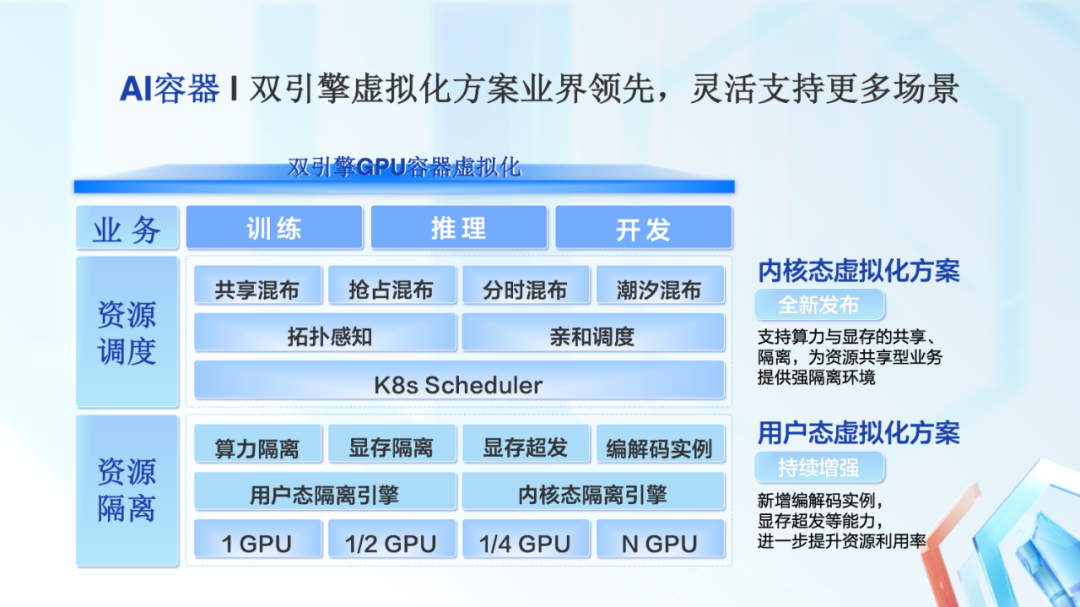
在 AI 容器部分,百度百舸 2.0 在业界率先推出了双引擎 GPU 容器虚拟化方案,可以满足各类场景的要求,提升 GPU 资源利用率。
这个双引擎 GPU 容器虚拟化方案,包括内核态和用户态两种虚拟化方案。
内核态虚拟方案是我们今年全新发布的,能够为业务提供强隔离环境。
用户态虚拟方案,是百度内部大规模使用了多年的方案,支撑了各类 AI 业务的落地。今年我们对他进行了增强,进一步提升资源利用率。
更详细内容可以参考《双引擎 GPU 容器虚拟化,用户态和内核态的技术解析和实践分享》。
在完成各个模块的升级后,百度百舸 2.0 的优异性能,在测试结果中得到了充分展现。
在今年 6 月 30 日发布的 MLPerf Trainning v2.0 的榜单中,百度百舸和百度飞桨联合提交的 BERT Large 模型 GPU 训练性能结果,在同等 GPU 配置下排名第一,超越了高度定制优化且长期处于榜单领先位置的 NGC PyTorch 框架。
从图中可以看到,百度百舸和百度飞桨的组合方案比其他结果快 5%-11% 不等。

百度百舸在行业智能化升级的深化过程中发挥了重大作用。
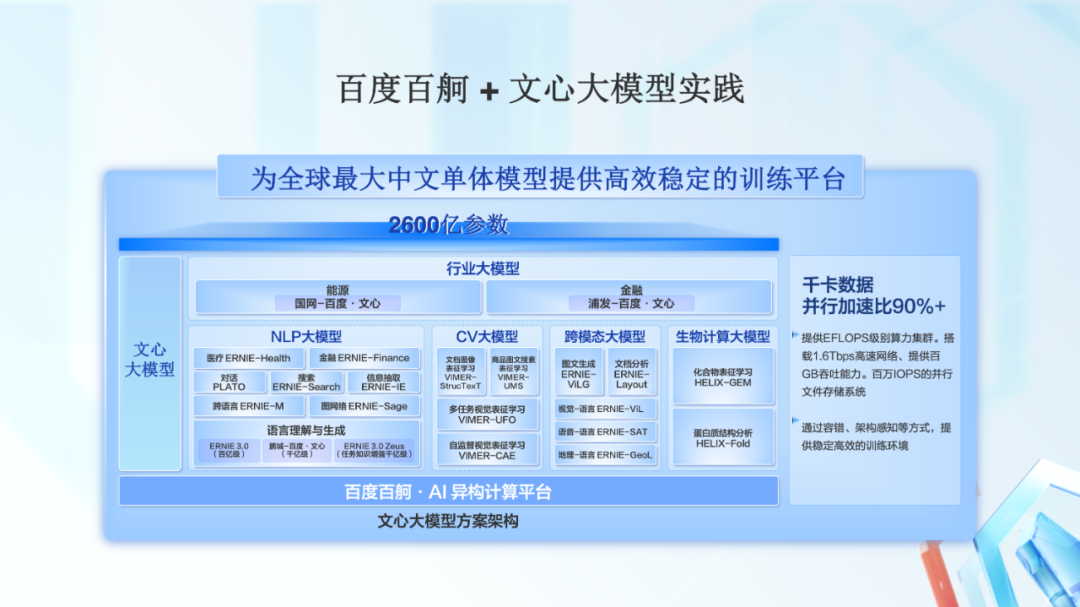
百度百舸支持了文心大模型的落地。这是全球最大中文单体模型,2600 亿参数规模。
百度百舸提供了千卡规模、单集群 EFLOPS 级别的算力,配备了 1.6Tbps 的高速网络,提供百万 IOPS 的并行文件存储系统。
通过 AI 容器提供的容错、架构感知等手段,为文心大模型的训练提供了稳定的运行环境,满足长时间周期的业务需要。
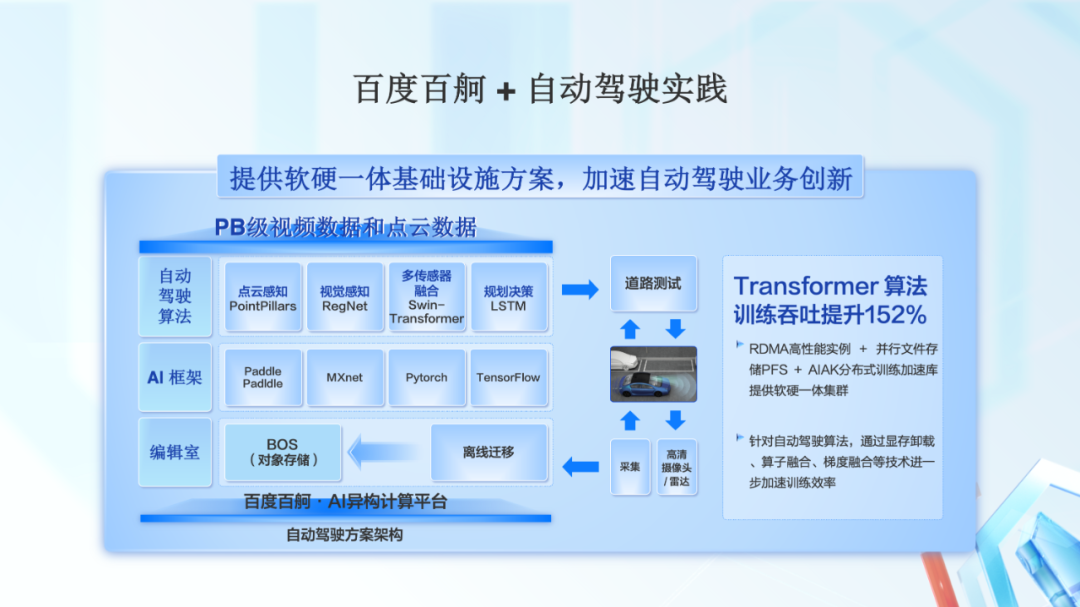
在自动驾驶领域,百度百舸为用户提供了软硬一体的智能基础设施。
在高性能的智能基础设施基础上,百度智能云针对自动驾驶算法、通过显存卸载、算子融合、梯度融合等手段,可以将 Transformer 算法训练吞吐提升了 1.5 倍以上,加速了自动驾驶的研发进程。
在生科医疗领域,百度百舸提供高性能生物计算的平台,作为高通量药物发现的引擎,可以满足 EB 级海量数据、千亿级参数的大模型训练,使得蛋白质结构的预测模型的迭代周期,从过去月级别提升至天级别。
其中,高性能网络为大规模的集群训练提供微秒级的通信时延。通过算力统一调度,满足不同场景的算力需求。同时,借助数据湖存储和对象存储之间打通后的能力,为用户降低数据存储成本一半以上。

基于百度百舸的智算中心,能够提供普惠多元的 AI 算力,支持 AI 应用的大规模发展,做到产业的全场景覆盖,推动城市数字经济的高速发展。
最近,百度智能云 - 昆仑芯(盐城)智算中心落地汽车产业重镇盐城,可为盐城周边的智能经济发展提供庞大的 AI 算力和海量的数据处理能力,加速智能化升级。
该智算中心将成为当地科技创新的动力源泉,向长三角区域源源不断地输出最前沿的科研创新成果。





