
演讲嘉宾 | 郭家 图灵机器人 COO
审核|傅宇琪 褚杏娟
策划 | 蔡芳芳
人工智能正在深度重塑教育领域,驱动着教学模式,尤其是个性化学习的革新。作为一家以语义和对话技术为核心的人工智能公司,图灵机器人用高精度 AI 知识问答、中英文语法纠错、图文识别等技术为教育行业赋能。自 2023 年起,图灵机器人用大模型逐一替代了 CNN 模型,并创新了 AI 口语老师、阅卷 AI 助理等应用,在步步高、作业帮等产品上应用上线并取得不错效果。
在用大模型重构产品的 1 年时间里,该公司对面向成本设计产品、大模型的“能与不能”都有了深度思考。本文整理自图灵机器人 COO 郭家在 QCon 2024 北京的演讲分享“教育大模型,说你行你才行”,拆解这段产品重构之路,并以实际案例,分享其中的辛酸苦辣。
本文由 InfoQ 整理,经郭家老师授权发布。以下为演讲实录。
我们是谁
图灵机器人公司专注于教育行业,已经发展了将近 15 年。在这个过程中,我们见证了许多变化,并从传统模型逐步进化到大模型。公司的 LOGO 是对图灵机器人的致敬,我们于 2017 年获得了图灵后人詹姆斯·图灵以及英国皇家社会协会的肖像授权。2019 年,我们还成为了图灵基金在中国的唯一合作伙伴。由于公司注册较早,图灵现在已成为专有名词,无法再次注册。
我们的团队成员大多来自交大系。我们的 CEO 是交大数学系毕业,一直从事人工智能和复杂决策系统的工作,CTO 老韦也是交大数学系出身,首席科学家何小坤曾是好未来 AI lab 的负责人,在双减政策实施后来到我们这家人工智能教育公司,石勇教授是中科院的合伙科学家。
我们的投资机构特色鲜明,全部是战略投资人。他们对公司的持续经营和帮助已经持续多年,也不急于退出。我们的天使投资人是赛富的创始合伙人羊东。我们还是微软在中国的第一家创投企业。此外,我们的股东还包括 HTC、奥飞动漫和洪恩教育。

公司上一次推出的 AI 产品名为虫洞语音助手,对于互联网的资深用户来说,可能对这款产品有所耳闻。我们从 2010 年开始研发并发布了这款产品,它最初是为塞班手机和黑莓手机设计的语音助手。当时,苹果公司尚未收购 Siri。随着苹果在 iPhone 4 发布期间推出 Siri,语音助手这一领域迅速变得热门,我们的用户数量也迅速增长,接近 2000 万。
在开发过程中,我们一方面专注于自己的产品,另一方面与 HTC 建立了合作关系。HTC 是安卓系统的第一款手机制造商。我们与 HTC 合作开发了小 hi 机器人,也就是小 hi 语音助手。该产品上线时拥有 100 多种虚拟人表情,400 多种技能,包括 200 多个 CP 和 SP 的接入。
我们的许多技能都是与后方的 CP 和 SP 合作实现的,例如,查询天气功能与中国天气网合作,餐饮推荐则与点评网站合作。然而,尽管用户基数庞大,语音助手的前期活跃度也不错,但将其商业化却非常困难。直到现在,手机上的语音助手仍然面临这一问题。因此,面向消费者的业务模式(to C)并不适合当时的产品。基于这一认识,我们决定将这个创业项目出售给 HTC。随后,我们开始了第二次创业。
第二次创业,我们转向了 AI To B 业务,即面向企业的人工智能服务。2014 年,我们将产品卖给 HTC 后,决定将这些技术转化为一个开放平台,主要面向开发者开放。平台吸引了超过 100 万的开发者,每天都有上百的开发者加入,他们主要利用以自然语言处理(NLP)为核心的语音助手相关产品。
2016 年,我们发现对于一家创业公司来说,儿童教育是一个需求量大、适合快速增长的领域,于是开始专注于教育领域。在 2017 年和 2018 年,我们有幸邀请到了包括我的师妹,MIT 博士贾梓筠在内的人才,一起参与这个项目,那年公司业务突破 1000 万营收。到了 2019 年,我们开始将视觉技术纳入我们的产品和服务。在教育领域,视觉技术的需求甚至超过了语音技术,例如题目识别、图片和文字识别、绘本和图画识别等,这些都需要计算机视觉(CV)技术来完成。
公司有五条主要的业务线。首先,进校业务方面,我们正在开发中高考英语口语模考系统,这种口语模考系统特别适合利用大模型技术。我们有教案的 AIGC 助手,它帮助老师生成教案,可以插入图片或精彩案例,甚至可以适时地加入一些幽默段子,让课程更加生动有趣。我们还提供大模型实验课,让学生亲自操作,测试 prompt,并使用 RAG 工具进行训练。
在出版领域,我们主要面向教辅公司和出版社,提供 AI 英语出题、AIGC 动画课等服务。此外,我们还涉足古籍、古典和学术研究领域,同样利用 RAG 技术进行数据挖掘。
运营商业务方面,我们提供 4G 电子产品,如自动翻译扫描笔、能够识别绘本和教材的台灯,以及用于口语测评方案的学生证和学生卡。
电教领域是我们公司历史最悠久、壁垒最深厚的业务之一,市场份额高达 80%。在这个领域,我们提供的服务包括语音助手、口语老师、作文批改以及翻译相关算法,如指尖翻译、手写体翻译和印刷体翻译。
最后,在汽车领域,我们为儿童领域提供重要的平台。从去年开始,新能源汽车如理想汽车推出了“小主人模式”,后排的小主人座舱需要语音助手来承载趣味内容和知识性互动。我们配套的小助人语音助手,包括音乐版权、分级阅读版权和词典版权,为儿童提供丰富的车内互动体验。

大模型产品的第一步是 Cost Down
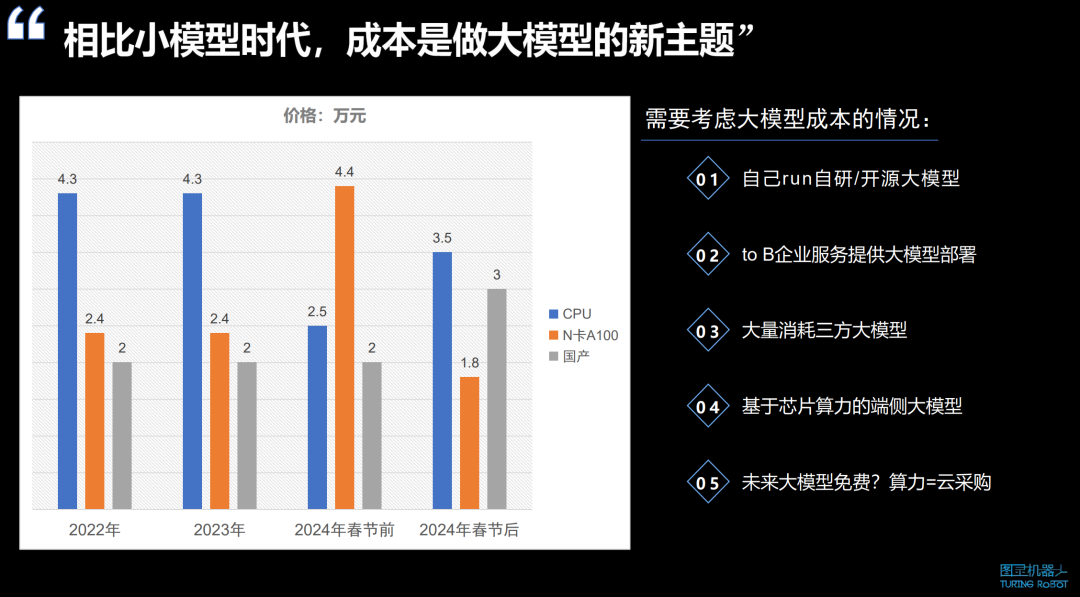
相比小模型时代,成本是做大模型的新主题
去年公司正面临大模型带来的成本压力。我们已经将许多算法商业化多年,但随着时代的发展,如果不追求大模型的发展,否则就可能被时代淘汰。要追赶大模型,我们需要考虑如何将旧算法与大模型过渡。直接将大模型引入市场,初期成本非常高。尽管图灵公司自我造血多年,但大模型的投入仍然巨大。有下述几种情况需要考虑降低成本:
自己研发或使用开源的大模型,这对算力要求很高,所有资源都需要自己提供。
为企业提供大模型服务,如进校或教育部的大模型私有化部署,学校对数据安全和隐私有严格要求,不希望竞争对手获取他们的原创内容,因此要求大模型必须私有化部署并本地训练。
大量使用第三方大模型,如按 tokens 结算的方式,初期试用成本可控,但一旦商业化,成本迅速上升,如我们之前使用 GPT 大模型接口,每月投入可达三四十万,对单个客户而言,一年几百万的成本难以承受。
端侧芯片层的大模型运行,如高通在最新芯片上运行大模型,预示着未来手机等设备将有本地大模型支持。
开源大模型的趋势,如通义、百川等公司开源大模型,目的是让更多人使用,甚至自己运行大模型,从而推动云服务的销售。未来,购买算力可能等同于购买云资源。此外,服务器情况有所变化。2023 年相比 2022 年,价格明显上涨超过 50%。2023 年 5 月的禁令前后价格也有所不同。但在 2024 年,云服务价格下降了约 20%,目前云算力和消耗量处于可控范围内,这与服务器资源逐渐变得更加充裕有关。
我们如何做大模型降本
我们的产品图灵 AI 口语老师已经推出了三个版本。C 版本是我们利用大模型技术所开发的版本,它在资源消耗方面是三个版本中最低的。右侧的图表展示了我们对成本的测算,这意味着,通过采用大模型技术,我们能够在保持产品质量的同时,有效控制成本。
C 版本口语老师用于在创作话题时,生成 AB 角的对话场景。生成对话后,系统会基于预设的预训练脚本来执行对话,重点在于发音的评测,而非表达的正确性。
B 版本的口语老师在用户每次提问时都会调用大模型进行多种识别,包括语法、地道表达、对话相关性以及句子润色等,因此大模型的调用量非常大,消耗量级也随之增加。
我们制作的大多数儿童产品的成本相对较低,可能只有几百元,甚至一百元以内。因此,在儿童电子产品上,大模型的成本是相当高的,难以承受。我们尝试了多种运营方法来进行二次转化,以降低成本。

A 版本口语老师的最大特点是教案虚拟人。虚拟人如何表达得好,关键在于情感识别。我们最初展示的口语老师形象被孩子们吐槽,因为许多学生认为这位老师给人一种压迫感,不想与其对话交流。因此,我们后来采用了更多二次元、卡通的形象。这里增加了两个成本,一是虚拟人的调用成本,二是大模型中虚拟人的情感识别成本。

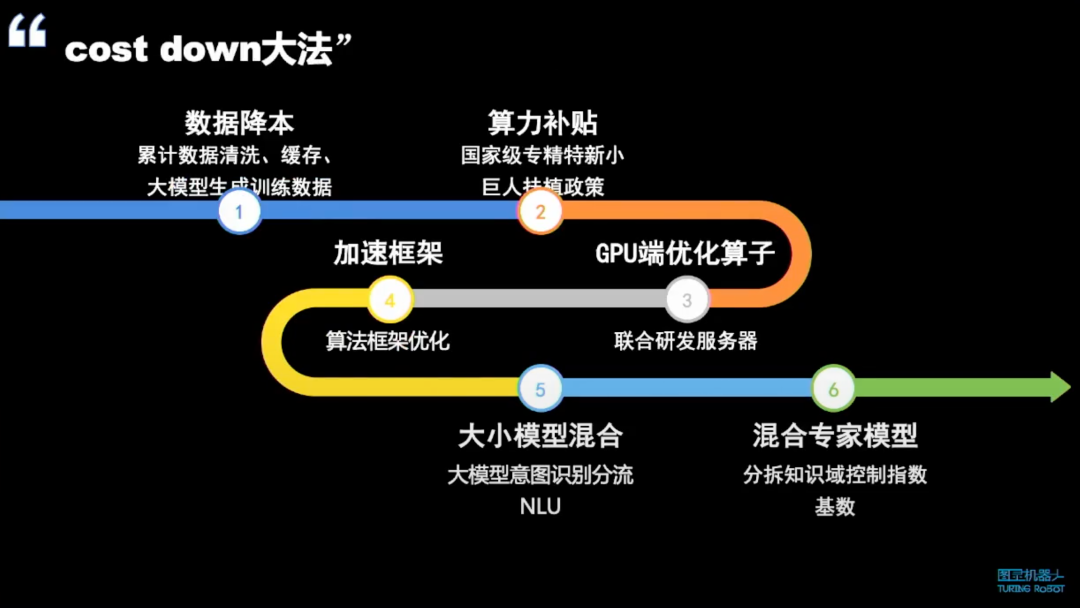
目前,我们对大模型的降本措施分为三大步,共六小步。
第一步是数据标注的降本。我们采用的方法是使用优质的大模型来生成训练数据,例如让 GPT 直接生成训练数据,这样可以轻松生成高质量的数据。
第二步是算力补贴。由于我们公司是专精特新的企业,我们申请了很多国家的补贴,这有助于降低成本。
第三步是 GPU 端的优化算子。我们与一些服务器公司,包括华为、阿里等,合作进行服务器端的优化。GPU 本身不变,但我们基于开发者模式进行自己的服务器优化,性价比非常高。
第四步是加速框架,这是算法层的框架优化。
第五步是大小模型混合。例如,我们要查天气,所有的语义槽位,如城市、日期等,这些可以直接用小模型处理,其精准度远高于大模型。用大模型做意图识别,然后将确定性的意图分流到 NLU 上,还有一些用大模型来兜底,这样成本会大幅下降。
第六步是混合专家模型。我认为这适合除了基座公司以外的所有公司。要提高准确率,就需要将领域限制得更窄,知识库限制得更窄,这样才会更准确。
试错一年终落地
在过去一年多的时间里,我们对图灵 AI 口语老师产品进行了试错和迭代。投入成本主要分为几个部分。
数据标注:这是成本中相对较小的一部分。由于我们长期从事语音助手的开发,已经积累了大量的数据,数据清洗和为大模型缓存数据还是非常高效的。
算力成本:算力成本并不高,因为产品尚未大规模推广,用户量增长有限,因此推理成本保持在较低水平。
算法重构:这是成本中较大的一块。随着大模型技术的发展,我们必须将所有的小模型算法用大模型重新开发一遍。不仅涉及到技术层面的重构,还包括算法工程师的转型和后台服务、产品测试的重构。
商业化成本:这是最大的成本部分。市场营销和应用层开发人员的投入非常巨大,尤其是在产品推向市场的过程中。作为教育公司,我们还必须购买大量正版内容。这不仅是因为训练需要,还因为在儿童教育领域,版权保护非常重要。拥有知名 IP 的版权内容能够带来溢价,家长更愿意为知名品牌的教育产品付费。
我们如何做产品迭代
我们的口语老师的第一个版本是一个名为 Free Talk 的 AI 外教产品,大约在去年 5 月份左右,我们推出了这个版本。
这个产品受到了 OpenAI 发布的一个名为 Call Annie 的产品的启发,Call Annie 是一个大头人像,能够进行英文交互。这个产品有几个特点:首先,它呈现为一个大头形象,给人一种面对面交流的感觉;其次,它进行全英文交流,不掺杂中文,模拟一对一外教的体验,并主打一对一外教的理念。
然而,在推广一段时间后,我们发现在实际使用中,无论是孩子还是成年人,都很难主动开口说话。即使有真人外教与孩子互动,孩子们也难以开口,不知道要说什么,也不会说。这导致 AI 外教很难带动孩子们进行对话。
此外,大模型在与孩子们交流时容易“超纲”。孩子们可能只学了一些非常简单的词汇,如"What’s this? It’s a bottle.",但如果让大模型反问,可能会提出很长、很复杂的问题,这让孩子们难以接受。
第二个版本
在口语老师的第二个版本中,我们采取了不同的策略来解决孩子们不知道如何开口的问题。这个版本有几个关键点。
专属陪练:基于孩子们的回复虚拟老师会进行个性化回复。
话题引导:我们设置了一些孩子们熟悉的学习主题,在这个范围内引导孩子进行回答,例如开学或者交朋友的场景,并基于这些场景与孩子进行互动。这种方法可以帮助孩子们更好地融入对话,并激发他们的表达欲望。
推荐回复:如果孩子在对话中不知道如何回答,我们会提供一些建议性的回答。这些建议是由大模型自动生成的,可以帮助孩子学习如何表达,并引导他们更顺利地参与到对话中。
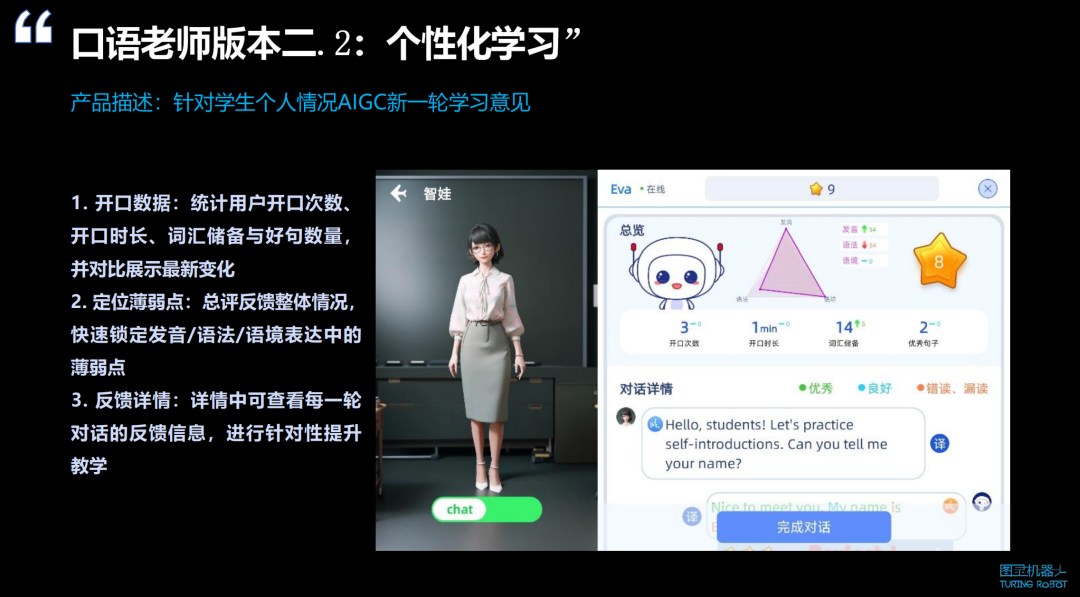
每个人的学习情况和英语掌握水平都不尽相同,即使是在有设定话题的情况下,不同学生可能会觉得内容太简单或太难。因此,我们接下来要针对每个学生的个性进行优化。
个性化学习的关键在于分析学生的开口数据,观察他们的兴趣度和意愿度。同时,还要考虑学生回答的准确率,以及他们对提示语和推荐语的使用率。这些因素都是影响个性化学习效果的重要指标。
在口语老师的开发中,第三点关键因素是教育教学体系的构建。我们生成的场景话题,无论是用于学校教育的打招呼场景还是开学场景,背后都有一支教研团队的支持,而最坚实的支撑来自于优质的教材。
以牛津树分级阅读为例,我们可以看到即使是像 VIP Kid 这样的真人外教一对一教学产品,其背后也不仅仅是外教的教学,还包括了一套教学方法和教案。外教会使用画板和教案,如牛津的《Let’s Go》系列,一步步引导孩子学习。我们利用 RAG 技术来学习并生成课程内容,RAG 在生成基于问答的内容方面非常擅长。我们首先生成一些问答内容,然后对这些内容进行加工,使其成为课程教学的一部分。这样的学习方式可以实现分级教学,根据学生的不同年级和水平来筛选话题的难度。
此外,尽管现在的 TTS 技术已经非常先进,但它仍然无法完全复制真人发音时的抑扬顿挫和适当的语速与停顿。因此,我们选择使用原版真人发声的内容,让孩子能够复述真人的发音,以此来提高学习效果。
我们还加入了真题练习,选用了与优质教材相配套的练习题。目前,使用 AIGC 技术生成的题目效果尚不理想,因此我们直接采用了教材中原有的配套习题。这些迭代和改进,都是口语老师产品不断进化的一部分,旨在提供更加个性化、系统化和有效的教学体验。
第三个版本
在口语老师的第三个版本中,我们实现了商业化的显著进展。这个版本主要针对中高考的口语模考,提供了一个全真的模拟考试环境。这个环境从孩子试音、试麦克风开始,到试听题目,再到正式进行考试,完全模拟了真实考试的各个环节和流程。
过去的口语模考打分准确率较低,常受到老师们的诟病。现在,大模型在语法打分上的准确性大幅提升。例如,在听一段短文后回答有关问题时,大模型不仅考察语法是否正确,还要看是否准确回答问题,以及答案是否与题目相关,角色、动作和时间是否匹配。这些通过传统算法难以实现的点,大模型都能很好地完成。从 2025 年开始,中国所有的中高考口语考试打分可能都会采用大模型技术,这将是一个解决痛点的质的飞跃。这也是商业化落地中一个难得的、能够快速推进的点。
最后一个特点是真题题库的应用。教育离不开版权,我们必须购买各省市的真题和模考题库。这些题库不仅涉及版权问题,而且出题人的思路独特,我们尝试过用 AIGC 技术模仿出题人的思路,但效果并不理想。如果替代率达不到一定水平,那么使用 AIGC 节省的工作量就非常有限,因此我们选择直接使用教材中的原题。
与国外产品几种不同设计理念对比
在国外,大模型口语老师产品有几种不同的做法,这里分享几个例子。
首先是 Yanadoo,这是一款来自韩国的产品,其母公司是韩国最大的互联网教育公司。Yanadoo 的特点包括:
十分钟教育系统:提出每堂课只需十分钟,强调短时间内高效学习。
奖学金激励:通过奖金激励学生。
一对一 AI 语音指导:提供一体化的 AI 指导服务。
游戏化学习:利用游戏化元素和奖金刺激,让学生在 10 分钟的高强度专注训练后,通过与 AI 老师练习并获得积分,以此提高学习效果。
大模型应用:主要用在口语纠错上,提升学习精准度。
第二个产品是 Ainder,这是一个社交产品,其特色在于:
AI 虚拟人社交:所有的社交对象都是 AI 虚拟人,每个虚拟人有不同的背景和人设。
个性化学习:用户可以与来自不同国家、不同口音和兴趣爱好的 AI 虚拟人进行英语交流。
共同兴趣:通过聊用户感兴趣的话题,比如 NBA 球星和术语,提高语言学习的兴趣和效果。
多语言者学习方式:该方法与一些多语言者通过与外国人聊天学习外语的方式相似,提供了一种自然的交流环境。
第三个产品是 Speak,这是一个 OpenAI 投资的教育公司,其特点为:
真人录播课:结合真人教学和 AI 技术,真人负责上课,AI 负责作业。
AI 作业:AI 用于听说读写作业的自动纠错和分析,包括发音、语法和词汇。
会员收费:虽然收费较高,但提供了高质量的学习体验。
产品评价:产品设计精良,无论是学英语还是其他外语,都获得了很高的评价。
第四个是多邻国,一个广为人知的平台,它在 GPT 3.5 发布时就是合作伙伴之一。多邻国采用的大模型用于:
Explain My Answer:对用户的回答进行纠错和分析。
Roleplay:在有限域下进行对话交互,让用户与 AI 进行 Free Talk 练习。
第五个产品是 Call Annie,一个提供随时视频通话的美女形象的产品,App 界面就像电话一样,提供交互体验。
最后一个是 CheggMeta,可以说是美国版的作业帮,它强调:
课后作业指导:专注于孩子回家后的作业指导。
自适应学习:根据孩子的学习情况调整下一步的学习计划。

总结来说,国内外在 AI 口语老师产品上的思路存在一些不同点。
国内 AI 口语老师产品的 1.0 版本在功能上大体相似。尽管每家公司都在训练自己的模型,影响体验最大的因素是模型训练的强度和精度。
国外产品的 1.0 版本普遍基于 GPT,因此在智能度上几乎一致。不同产品之间的主要区别在于各自的教学理念。例如,有的产品采用 10 分钟教学法,有的通过社交方式学习,有的结合真人录播课,有的游戏化学习,有的通过虚拟形象进行互动,还有的专注于作业辅导。
国内外产品在教学理念上有明显的差异。国外产品展现了多样化的教学理念,而国内产品可能在未来会根据自己的理念逐渐分化。
在英语学习的口语老师应用中,每家公司至少都会设计一个虚拟人物头像,这是虚拟人的最基本表现形式。一些公司则更为复杂,将视频录制与虚拟人制作相结合。即使是较为简单的应用,也会加入虚拟人物头像,以增强用户体验。虚拟人的表达和人的情感连接是非常重要的一环,它与大模型技术有着天然的强关联性。
在移动互联网行业中,我们常会提到“杀手级应用”,而对于大模型技术来说,虚拟形象很可能成为杀手级应用中的核心要素。这是因为虚拟形象不仅能够展示背后的价值观、人设和情感,还能通过其形象与用户建立联系。
大模型的“行与不行”
大模型在教育板块的应用存在一些问题,同时也有其不擅长的领域。
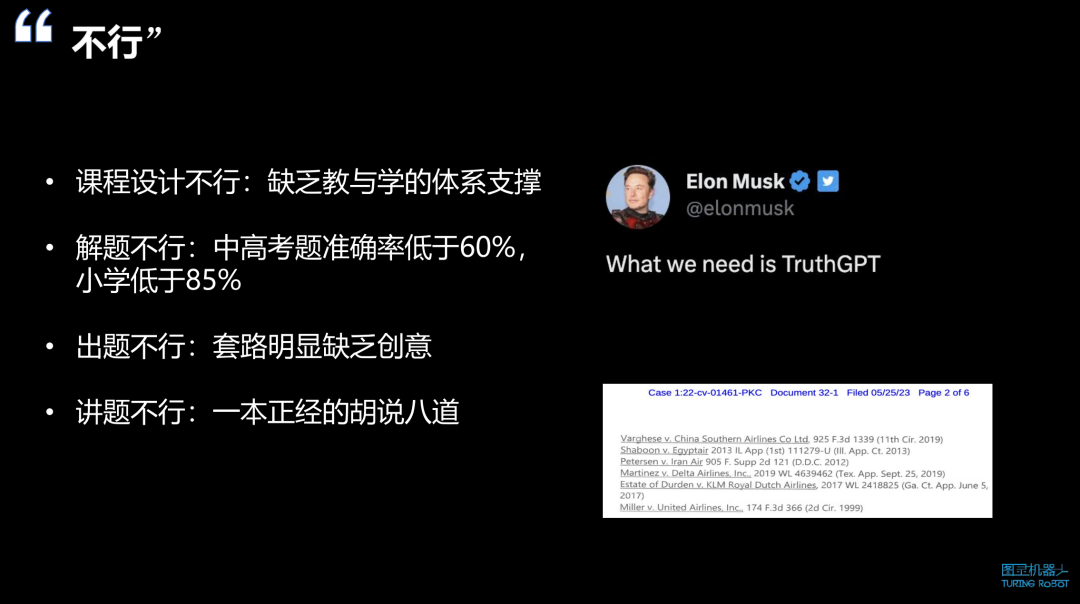
课程设计不行:大模型缺乏教与学的体系支撑,无法独立进行课程设计。课程设计需要明确的目标、大纲和学生学习进度等,而大模型目前还达不到这样的要求。
解题能力不行:尽管有报道显示大模型通过了某些考试,但实际上在教育领域的测试中表现并不理想。以高考为例,准确率普遍低于 60%,小学五年级的准确率低于 85%,只有一二三年级的情况还算可以。
出题能力不行:大模型能出题,但题目套路明显,缺乏创意。现代中高考题目,特别是北京、上海等地的试卷,已经从传统的选择题、完形填空转变为应用题,要求考生解决实际问题,这需要综合能力。大模型目前还无法满足这样的出题要求。
讲题能力不行:大模型在讲解题目时可能会出现问题,可能会“胡说八道”,即使给出正确答案,其解释过程可能会越来越偏离正确方向,最终虽然得出正确答案,但教学场景中这样的讲解是不可接受的。
大模型在教育领域的优势体现在以下几个方面。
阅读领域:大模型在阅读领域的表现是令人满意的。RAG 型的应用在这方面尤其出色,它能够增强模型对信息的检索和生成能力。大模型被成功应用于基于学习材料的自动互动场景。这种应用通过与学习材料的结合,提供了自动化的、互动式的学习体验,这在当前教育技术中是一个非常好的方向。
微调和再训练:在使用大模型时,我们发现了一个令人惊艳的现象:与小模型相比,大模型在再训练时所需的数据量显著减少。例如,在口语老师的语法纠错功能中,原本需要 10 万到 100 万级别的数据量,而大模型仅需要很少的数据量就能训练出非常好的效果。
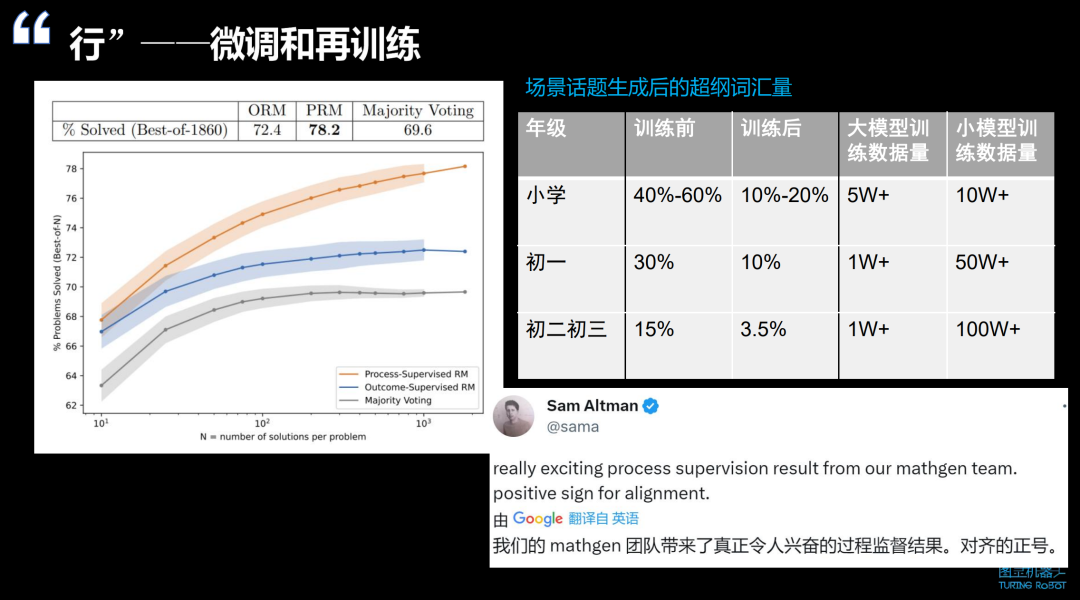
大模型在教育领域的应用还包括过程监督式的方法。通过过程监督,可以显著提升大模型在解题方面的准确性,有望快速解决解题不准确的问题。
此外,我认为未来一两年内,教育领域将面临一个重要的改革和转型理念,即真人与 AI 老师的结合。在这个模式中,真人教师的角色是组织教学活动和建立情感联系,而 AI 老师则充当工具型的角色,提供无所不能的知识支持。
这种结合利用 AI 的强大功能,同时保留真人教师在教育中不可或缺的人文关怀和情感交流。




