
从 0 到 1 的 MiniMax 语音大模型
2023 年 11 月,MiniMax 发布语音大模型 abab-speech-01。从 11 月至今,共有超过 400 家企业用户接入我们的语音大模型。
在实际应用中,来自各行各业的用户给我们反馈了很多好的建议和想法。例如,在复刻有声书场景下,市面上没有可以批量、快速生成多角色音频的解决方案;在直播电商等注重互动性的场景中,各家现有语音能力仍无法做到实时,在生成语音的过程中仍需一定的等待时间,非常影响用户体验;在教学场景中,模型碰到特殊字词或者多音字的情况,时常存在发音不准确的问题。
为了给用户带来更加高效、丰富和真实的语音定制体验,我们不断迭代 MiniMax 语音大模型,并基于用户高优需求新增语音 API 接口,并上线了多个产品功能。MiniMax 是目前第一个开放多角色配音商用接口的公司。
在模型基础能力上,我们的语音模型对长达数百万小时的高质量音频数据进行训练,基于它的训练结果,仅用 6 秒的音频就能完成音色复刻,基于文本生成语音的字错率低至万分之五,已达到全球顶尖水平。
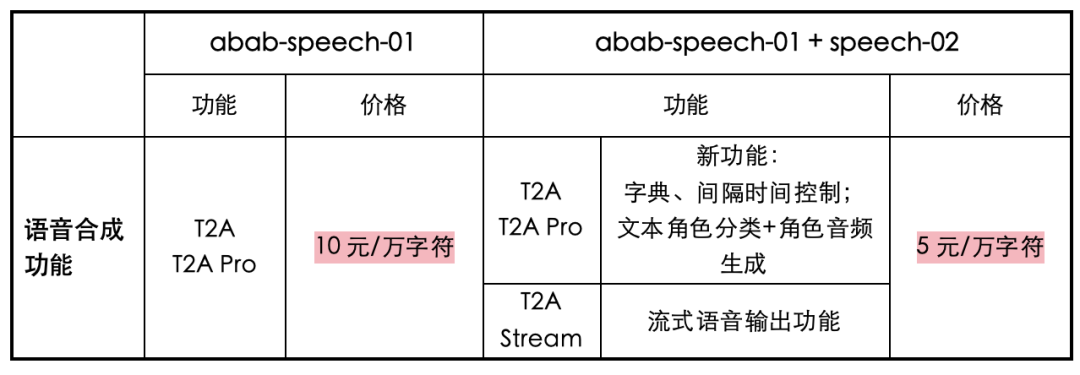
针对用户的高优需求,我们新增了以下产品功能:
三个 API 接口:多角色音频生成 API、文本角色分类 API 和快速复刻 API,帮助用户自主批量生成、克隆多角色音频;
多语种能力、字典和间隔时长控制,满足用户丰富的定制化需求,提升教学场景体验
T2A Stream (流式语音输出) 实现生成与输出的同步,减少用户在直播、对话等场景的等待时间。
为了让更多用户体验、使用我们的技术,我们在价格上也做出了调整:T2A Pro、T2A、T2A Stream 等价格下调为原先的一半,由 10 元 / 万字符降至 5 元 / 万字符。
具体功能价格调整见下表:
声音小剧场
由于语音模型没有公开的测评集,衡量一个语音模型到底怎么样主要依靠几个比较主观的评判标准,例如:自然度、相似度,可懂度和情感表现等。以下是几个基于我们语音大模型生成、复刻的一些语音效果。大家可以听听看,欢迎拍砖:)
01 中英文夹杂读着毫无压力
文本:
哎,你说你特别想念某个东西,可以说"I really miss it a lot" 或者"I'm missing it terribly." 这样表达出你的感情。有什么特别想念的嘛?想聊聊吗?
声音 1(明杰):
声音 2(晨曦):
声音 3(祁辰):
02 跨语种复刻,比原声更自然
文本:
别担心,犯错是学习的一部分,下次你会做得更好的。Don't worry, making mistakes is part of learning. You'll do better next time.
原声音频(童声):
复刻音频(中 + 英):
只用中文原声,也可以复刻出他们讲中、英、日、韩等多种语言的声音:
韩语:
日语:
03 AI 嬛嬛和四爷,有没有甄嬛十级学者来检验一下效果?
04 多音字绕口令也难不倒!
真人都不一定能读准的多音字绕口令,我们的语音模型可以:)出现多音字的绕口令对语音模型理解上下文提出了很高要求。
“人要是行,干一行,行一行,一行行,行行行,行行行,干哪行都行”
05 实时语音通话,跟小海螺打电话吧
MiniMax 不仅为企业用户和开发者提供语音相关的 API,也为普通用户打磨了多款含有语音功能的产品。例如,我们在 AI 助手海螺问问上线了实时语音通话功能——无论你遇到什么问题,都可以随时打电话给小海螺,就像在和朋友聊天一样轻松、自然。小海螺的反应比 ChatGPT 的语音功能还快哦,快来体验一下吧!
06 唱 AI 嘻哈
节奏感强、唱腔复杂的饶舌说唱,我们的模型也能够超酷演绎。
想和 AI battle 说唱的朋友可以打开链接尝试:




