
云原生大潮风起云涌,企业不再停留在理念层面,目前已在多方面落地。消息队列作为关键技术基础设施之一,也在云原生时代面临着挑战和机会。本文从传统消息队列上云所面临的三大挑战说起,并以 Apache Pulsar 为技术案例,深入浅出地讲解了如何打造适配云原生的消息队列。希望本文能对大家提供参考。
1 背景介绍
如今,云原生的概念已经渗透到了软件开发的方方面面。云原生不再只是未来的设想,而是一个现在进行时。开发人员在开发设计之初就需要考虑未来如何在云原生环境上部署、运行服务,即如何“上云”。
在云上,消息队列将成为一种基础设施,像自来水一样,可以随时按需使用,并且有无限容量。用户无需关心消息队列的型号、规格,或是否需要升级配置,只需专注上层业务。
腾讯云是腾讯集团倾力打造的云计算品牌,面向全世界各个国家和地区的政府机构、企业组织和个人开发者,提供全球领先的云计算、大数据、人工智能等技术产品与服务,助力各行各业实现数字化升级。为了更好地为广大用户服务,提供金融级可靠消息服务,腾讯云开启了消息队列上云之路,目前 Apache Pulsar 在腾讯云上已经大规模使用。
2 传统消息队列上云遇到的挑战
消息队列在上云过程中遇到了很多新的挑战,比如如何平滑扩容、如何管理海量分区、如何保证异地多活等高可用性。
挑战一:平滑扩容能力不足
传统消息队列(如 Kafka 等),在平滑扩容方面存在很多不足,很难做到快速、无感知地扩容。由于 Kafka 的数据保存在 Broker 上,而每个 Broker 上的分区数据是有状态的,因此每个 Broker 上数据可能不同,客户不能通过简单地增加 Broker 数量完成扩容。当集群增加新 Broker 进行扩容时,会涉及数据迁移和同步,进而引发磁盘 IO 和网络消耗。当流量突然爆发,业务本身使用 IO 和网络带宽就会很高。此时,如果由于集群容量不足而触发扩容,迁移的带宽占用和数据冷读会直接影响到上层业务的使用,造成高延迟和错误率飙升。如果写入的速度比迁移速度更快,那可能永远都无法完成数据迁移。
此外,通常 20% 的客户占用了 80% 的流量,有些用户对底层消息队列并不熟悉,使用方式可能不规范,导致 Broker 端出现数据倾斜,很容易造成某些节点的磁盘占满,而其他节点的磁盘有比较大的空间。只采用简单扩容、迁移数据的方式根本无法解决这种情况。
挑战二:海量分区管理无法承载
有些用户的业务比较特殊,单个分区的流量不大,但总体使用的分区数很多。现有的一些消息队列,很难承载海量的分区,例如:如果一个 Kafka 集群分区数太多,当出现 Leader 或者 Controller 切换时,恢复时间会很长。另外,如果不使用 SSD,文件写入变得分散,可能出现复制跟不上,导致 ISR(In-Sync Replicas,副本同步)频繁波动等。
为了解决上面这个问题,通常我们会为每个用户部署一个集群,保证每个集群的分区数不会过多。但由于每个集群总流量不大,会造成集群资源使用率不高,有大量闲置资源,无法发挥云原生环境的优势。
这种情况下,最理想的方式是多个用户共用一个集群的资源,分别限制资源的使用量,避免出现资源浪费。但如果把所有用户全部聚集起来放在同一个集群运行,又可能会出现几十万、上百万分区数问题,这就是我们的第二个挑战——海量分区管理。
挑战三:无开箱即用的异地多活解决方案
很多金融级用户的业务场景对高可用、RTO(Recovery Time Objective,业务恢复时间)等指标要求非常高,因此需要同城多机房或者两地三中心的异地多活的方式。对于强一致的异地多活,现有的消息队列很少有提供开箱即用的完整方案。
3 遇见 Apache Pulsar
如果使用传统的消息队列上云,要解决上述问题需要费一番功夫。通过调研,我们发现为云原生打造的下一代分布式消息系统 Apache Pulsar 能很好地解决上述的大部分问题。下面针对上述各种挑战,我们从 Apache Pulsar 具备的能力做下针对性概述。
支持秒级平滑扩容
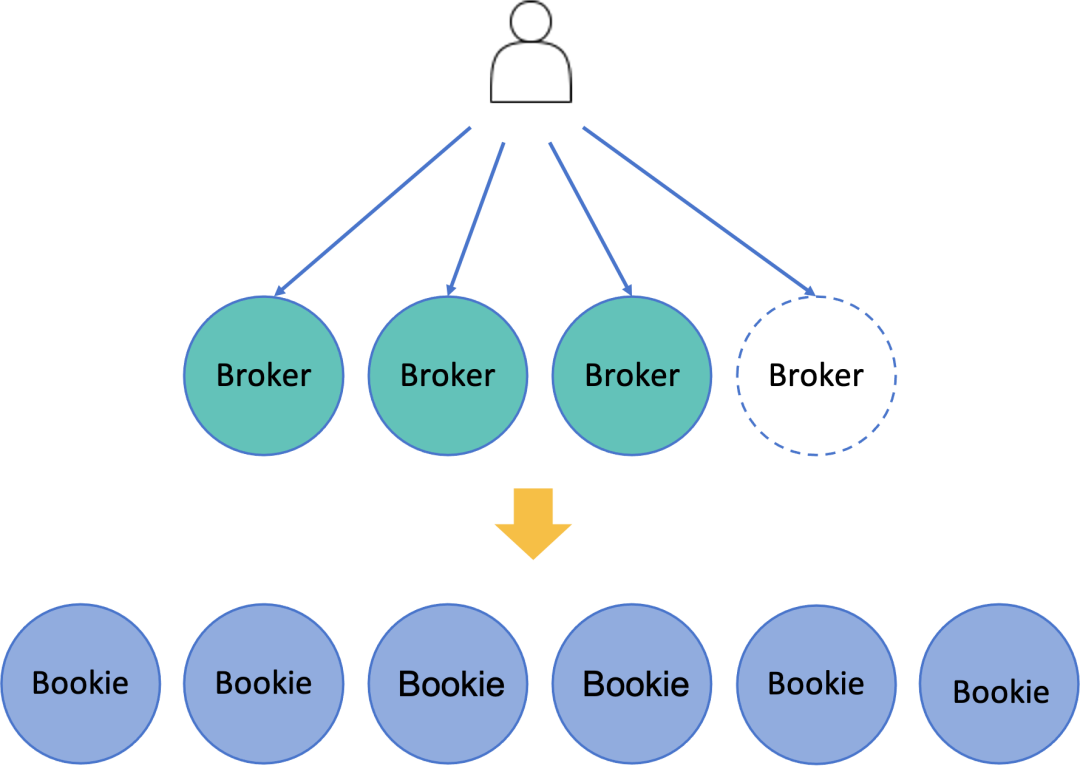
Apache Pulsar 支持云原生环境,可以充分利用云原生环境的弹性能力,达到自动、无感知的扩容,按需使用,不影响上层业务。Apache Pulsar 使用 BookKeeper 作为数据存储层,而 BookKeeper 原生避免数据倾斜问题。
Apache Pulsar 上层 Broker 无状态,原生支持平滑扩容。当流量突发增加时,只需要增加一个 Broker,然后等待部分 Topic 重新分配到新的 Broker 上,流量就会自动迁移到新的 Broker 上。整个过程只涉及元数据的修改和 Topic 分配的计算,实现秒级自动迁移。
具备海量分区支撑能力
在云上,海量分区是常见问题。假设客户有 100 万个分区,如果把每个分区的元数据信息都保存起来,那总体数据量会有几百 MB,光是下载这么多的数据都需要很多时间。
Apache Pulsar 没有完全解决所有问题,但已经具备支持海量分区的能力。Apache Pulsar 抽象了 Bundle 的概念。Bundle 的元数据保存在 ZooKeeper。每个分区落在哪个 Broker 上,这种关系信息不会直接保存起来。Apache Pulsar 使用一致性哈希,把 Bundle 作为哈希环中的节点,让所有的分区散列上去。我们只需保存 Bundle 与 Broker 之间映射关系的信息即可;分区与 Bundle 之间的关系是固定的,可以通过散列动态计算出来,不需要保存每条关系。
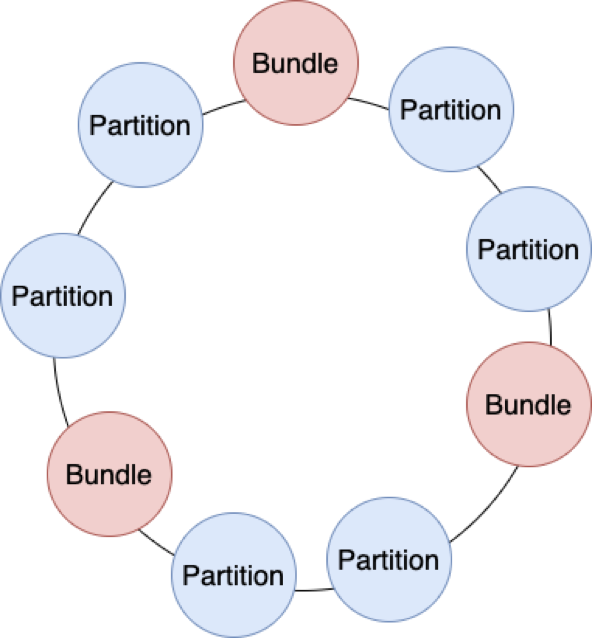
如此一来,我们需要存储的元数据就有几个量级的下降。在切换 Broker 时,基于一致性哈希的优势,分区再平衡只会涉及到部分变动,可以迅速重新进行分配。
4 Apache Pulsar 在腾讯云上的实践
通过调研后,我们决定基于 Apache Pulsar 打造一款新的消息队列——TDMQ,开启 Pulsar 在腾讯云上的实践之路。下面和大家分享下 Apache Pulsar 在腾讯云上的实践经验,探究 Pulsar 如何快速适配云原生环境
云原生下的平滑扩容
我们利用 Apache Pulsar 支持云原生环境进行平滑扩容。常见的扩容场景分为几种情况:
a) 当分区数量远大于 Broker 数量时,新增 Broker,分区用一致性哈希(hash)方式自动迁移 Topic 到新的 Broker,然后新的 Broker 就可以对外提供服务,分担压力。
b) 当分区数量少于 Broker 数量时,增加分区,让流量分布到更多 Broker 上,从而实现平滑扩容。
数据倾斜与存储层扩容
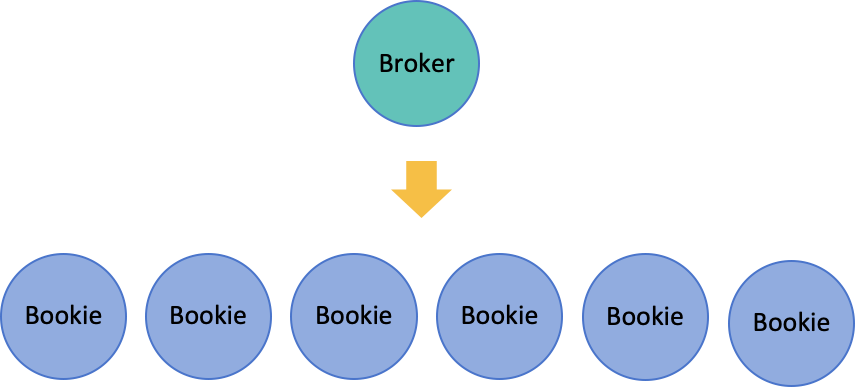
Broker 不保存数据,Broker 通过 BookKeeper Client 把数据保持到 BookKeeper 集群中,每个节点我们称为 Bookie。最终还是无法避免 Bookie 是有状态的,问题又回到了原点,有状态的 Bookie 又如何实现平滑扩容呢?
首先,我们需要了解 Apache Pulsar 的存储机制。Pulsar 使用 Quorum 机制来保证数据的一致性和高可用。当 Pulsar 持久化一条消息时,Broker 使用 BookKeeper client 同时并行写入多个 Bookie 节点,根据消息的 Ack 数,来判断有多少数据写入成功。
ENSEMBLE SIZE(E):可用 Bookie 的数量
WRITE QUORUM SIZE (QW):并行写入消息的 Bookie 数量
QUORUM SIZE (QA):Ack 消息的数量
如果 Bookie 的数量大于 QW 的值,数据会以条带化的方式落到不同节点上,过程如下图所示:
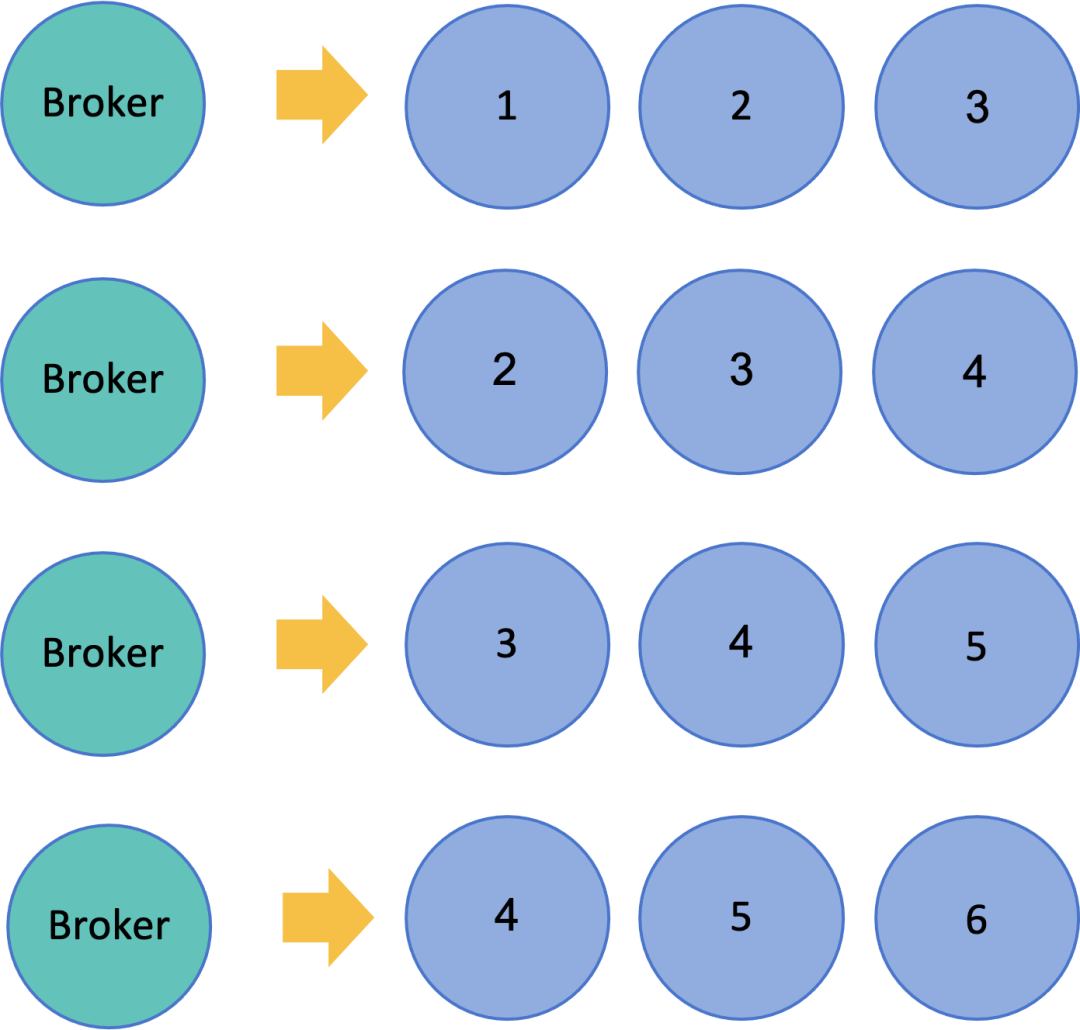
第一条消息,Broker 会同时写入 Bookie1、Bookie2、Bookie3。
第二条消息,Broker 会同时写入 Bookie2、Bookie3、Bookie4。
第三条消息,Broker 会同时写入 Bookie3、Bookie4、Bookie5。
第四条消息,Broker 会同时写入 Bookie4、Bookie5、Bookie6。
…
这种条带化写入的好处显而易见,既能充分利用每个磁盘上的 IO,还能让数据存储近似均匀,避免出现数据倾斜问题。当增加新 Bookie 节点后,无需等待数据迁移就可以对外提供服务,整个过程非常平滑。
海量分区:降低和去除 ZK 依赖
海量分区是我们要解决的一个重要问题。如上所述,Pulsar 抽象的 Bundle 的概念能很好地帮助我们解决上云过程中遇到的海量分区管理问题。但 ledger、cursor 等其他元数据还是存储在 ZooKeeper 中。当分区数量达到百万时,ZooKeeper 会不堪重负。因此,我们基于 Pulsar 做了一些改进——降低和去除 Broker 对 ZooKeeper 的依赖。
Apache Pulsar Broker 对 ZooKeeper 的依赖主要包括以下几个方面:
负载状况
生产、消费
Policy 存储
Leader 节点选举
通过对依赖的分析和梳理,我们确定了降低和去除对 ZooKeeper 依赖的两步目标:
a. 降低 Broker 对 ZooKeeper 的依赖。即使 ZooKeeper 挂掉了,Broker 至少在一段时间内不会受到很大的影响,可以继续提供读写服务,等待 ZooKeeper 的恢复。
b. 完全去除对 ZooKeeper 的依赖。将元数据全部保存到 Bookie,不再依赖 ZooKeeper 存储数据。
具体地,我们对代码做了一些改动,如:
在 ZooKeeper 挂掉、本地缓存超时的情况下,让本地的缓存快照不过期,Broker 保持当前元数据不变,继续使用缓存中的元数据。
在写入过程中,如果 Ledger 承载的 entry 数量已经超过了限制的大小,Apache Pulsar 会关闭当前 Ledger 并重开一个 Ledger。我们优化后,在这种情况下,Broker 暂时不关闭当前 Ledger ,而是继续写入,从而避免访问 ZooKeeper。
使用外部存储保存负载状况等数据。
只在启动时依赖 ZooKeeper 选举 Leader 节点,后续则通过订阅的 Exclusive 特性实现选主。
增强原生异地复制能力,提供强一致方案
有些用户的业务场景对高可用的要求非常高,需要同城多机房或者两地三中心的异地多活。Pulsar 本身有相应的异地复制能力,但属于异步复制。异步复制就要看用户对 RTO、RPO(Recovery Point Objective,恢复点目标)的容忍程度,如果要求 100% 可靠,一条消息都不能丢,那异步复制不能满足要求。
另外,异步复制即使为全量复制,为了保证消息顺序,同一时间我们通常只会使用一个中心,这样整体资源利用率最多为 50%,资源使用率不高。另外,无法保证灾备中心何时能接管流量,接管后所有业务是否正常运行。因此,我们提供了强一致的方案。
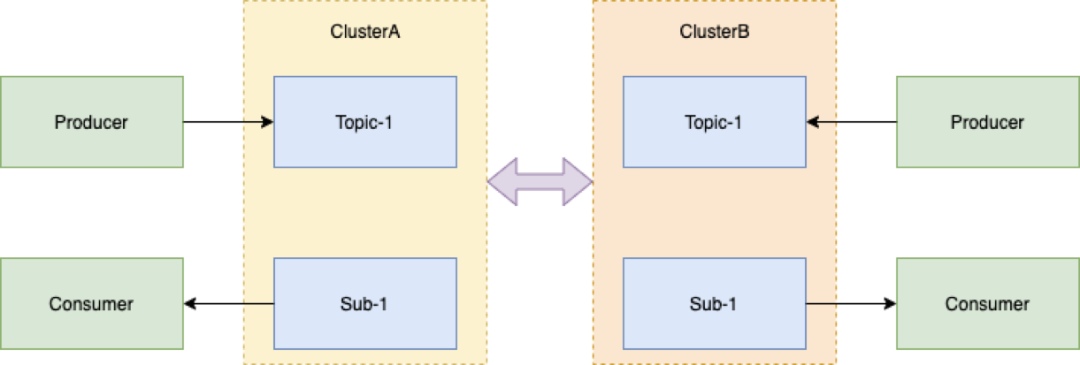
1. 同城跨机房
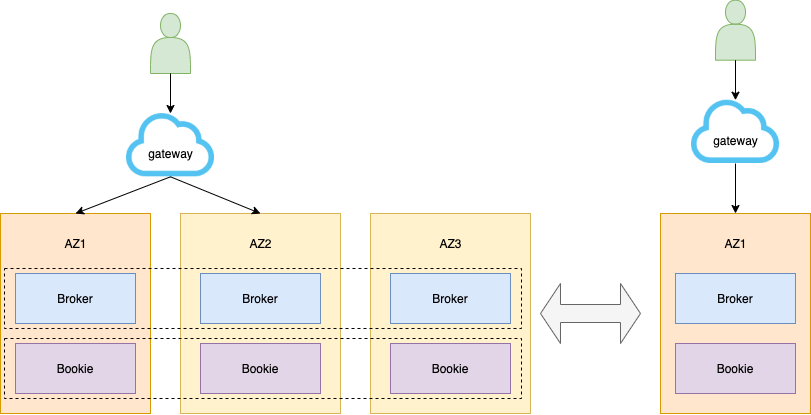
Broker 跨机房。多数据中心之间地位均等。正常模式下,多数据中心协同工作,并行为业务提供访问服务,充分利用资源。一个数据中心发生故障或灾难,其他数据中心正常运行,立即对关键业务或者全部业务实现接管,达到互备效果,使上层业务不会有明显的感知。
2.三中心高可用
跨地域场景,分为生产中心、同城容灾中心、异地容灾中心。当双中心由于自然灾害等原因而发生故障时,异地灾备中心可以用备份数据恢复业务。
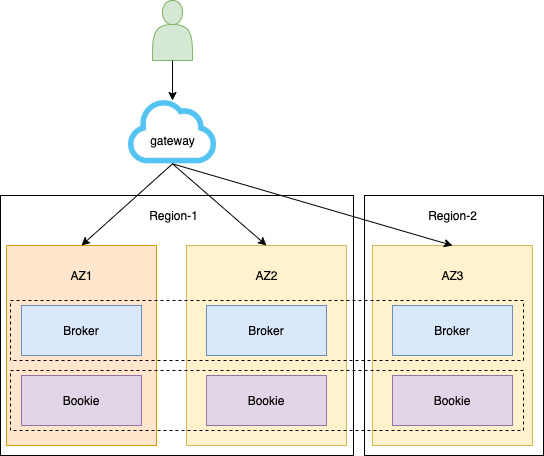
无论是同城跨机房还是三中心的高可用,对写入都有限制——限制每条消息必须要跨机房 / 地域写入,Ack 成功才算成功。
此外,我们实现了自动无感知切换模式。如果找不到相应的备份地域,自动通过模式切换进行降级,使用户可以在单个区域里面继续写入、生产、消费,实现无感知切换。
Pulsar 具备跨机架、跨区域感知的能力,云上的运营端配合 Broker 中bookkeeperClientRackawarePolicyEnabled、bookkeeperClientRegionawarePolicyEnabled、bookkeeperClientSecondaryIsolationGroups 等参数,就能实现上述能力。
除了实现 Broker 的高可用,我们也实现了跨机房 / 地域 ZooKeeper 的高可用。为了能够快速恢复集群,每一个数据中心的 ZooKeeper 都有 Observer。Observer 不参与投票和选举。当集群节点数不足时,Observer 可快速切换为对应的 Follower ,参与选举,保证 ZooKeeper 集群的高可用。
另外,我们弱化了对 ZooKeeper 的依赖。即使一段时间内 ZooKeeper 不可用,Broker 还可以继续对外提供服务,弱化上层业务对切换的感知。
由于地域之间网络延迟,保证强一致性跨地域容灾,会让上层业务使用消息队列的延迟上升,因此需要业务方根据自身的实际情况,权衡选择具体的异地多活方式。
5 未来寄语
相对于其他传统消息队列,Apache Pulsar 借助存储与计算分离的云原生架构,以及支撑平滑迁移、承载海量分区、跨区域数据复制等原生功能特性,成为解决原有消息队列上云挑战的最佳解决方案之一,目前不断吸引众多国内外企业落地并聚集了众多活跃开发者。但当前 Apache Pulsar 距离最终的 Serverless 化、无规格化、无限流量等愿景目标还有一段路要走,这也正是 Apache Pulsar 社区众多贡献者的价值所在,期待大家能够参与进来。我们会继续积极和社区合作,一起完善 Apache Pulsar 生态。
云原生是正在发生的重要技术事实,云原生落地之路也刚刚开始,期待通过丰富的场景和实践,持续推动云原生前进。希望上述我们在消息队列方向的探索与实践能够带给有着类似需求的同行一些参考。
在腾讯云上,我们基于 Apache Pulsar 推出了 TDMQ 消息队列,除了上述改动,还有其他新特性。2021 年,TDMQ 会提供更多的新特性,支持 HTTP、AMQP 等多种协议,方便使用其他消息队列的用户无缝迁移到腾讯云上。同时,我们还会有更多增强能力,如 Function、金融级 SLA 承诺、全球消息同步、Serverless Topic、弹性用量等等。
作者简介:
林琳,Apache Pulsar PMC 成员、腾讯云专家工程师,专注于中间件领域,在消息队列和微服务方向具有丰富的经验。




