
在基于事件驱动架构构建 SaaS 应用程序时,分析能力已经成为核心功能,因为它可以更容易地监控使用模式并以可视化的方式呈现数据。因此,这一功能很快成为 SaaS 平台用户的需求也就不足为奇了。
这让我们灵光乍现,我们意识到,在为客户构建这个新功能的同时,我们也可以通过内部分析仪表盘更好地了解客户如何使用我们的系统。
Jit是一家安全创业公司,旨在帮助开发团队快速识别并轻松解决应用程序中的安全问题。我们的产品已经达到了一定的成熟度,在这个阶段,让用户能够直观地了解他们在他们的安全旅途中所处的位置是至关重要的。同时,我们也希望了解哪些产品功能对我们的客户和用户最有价值。
我们开始思考如何最有效地构建一个分析解决方案,它从同一个源获取数据,并将数据呈现到几个不同的目标。
第一个目标是客户指标湖,其本质上是一个随时间变化、租户分离的解决方案。其他目标则是第三方可视化和研究工具,利用相同的数据摄取架构进行更好的产品分析。
在撰写本文时,我们的产品团队有在使用这类工具,如 Mixpanel 和 HubSpot。团队使用这些工具收集关于单个租户使用情况和产品总体使用趋势的宝贵数据。
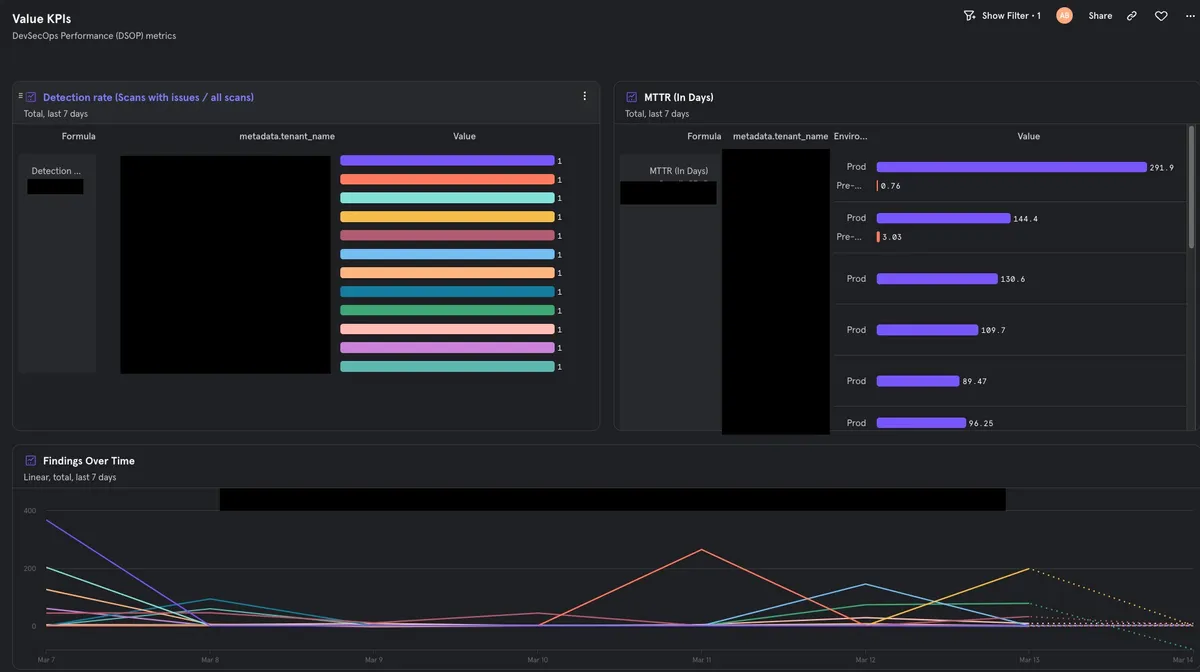
如果你曾遇到过类似的工程挑战,那么阅读本文就对了,我们很乐意深入探讨如何使用无服务器架构从头开始构建这样一个系统。
作为一个基于无服务器的应用程序,我们的主要数据存储是 DynamoDB。然而,我们很快就明白,它并没有我们聚合和呈现分析数据所需的时间序列能力。使用我们现有的工具来实现这些将需要更长的时间,并且对于我们希望监控、度量并呈现给客户的每一个新指标,都需要大量的投入。因此,我们决定使用 AWS 构建块从头开始快速构建一个能够为我们提供我们需要的双重功能的东西。
我们意识到,为了能够为每个客户创建个性化的图表,我们必须以时间序列的方式处理数据。此外,我们还要保持强大的租户隔离,确保每个客户只能访问他们独有的数据,从而防止任何潜在的数据泄露,这是这个架构的一个关键设计原则。这让我们开始寻找最经济、管理成本最低的工具。在本文中,我们将介绍我们为内部和外部用户构建新的分析仪表盘所需的技术考量和实现。
分析功能架构设计
架构设计从数据来源开始——即 Jit 的微服务写入的事件。这些事件代表了整个系统中发生的所有小事件,例如新发现的安全问题、已修复的安全问题,等等。我们的目标是监听所有这些事件,最终能够以时间序列的方式查询它们,并基于它们向用户呈现图表。
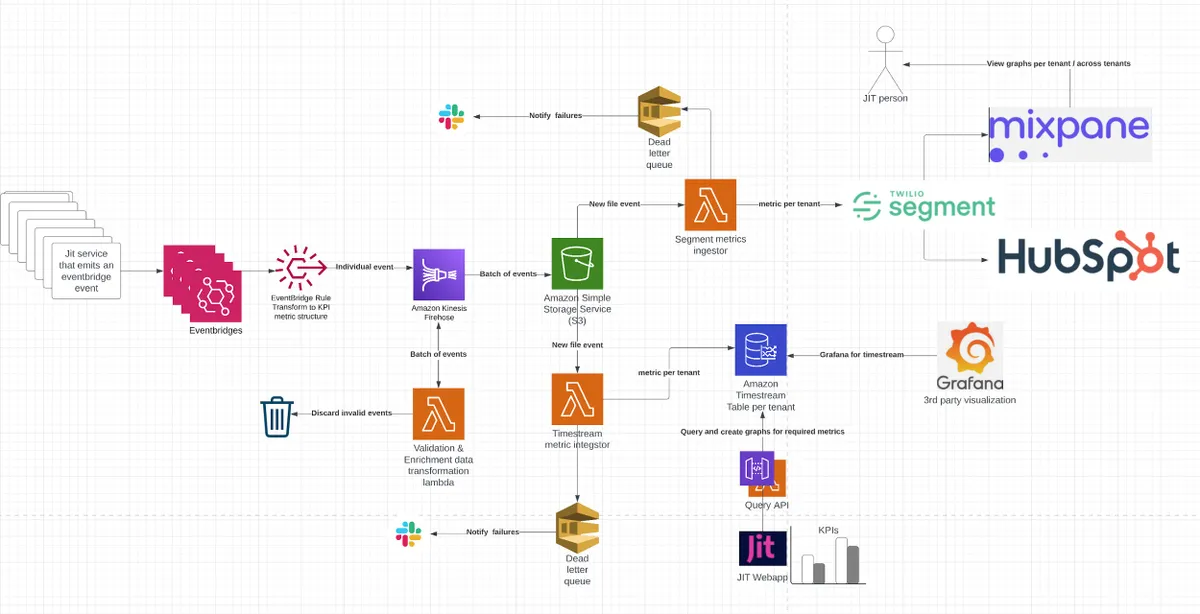
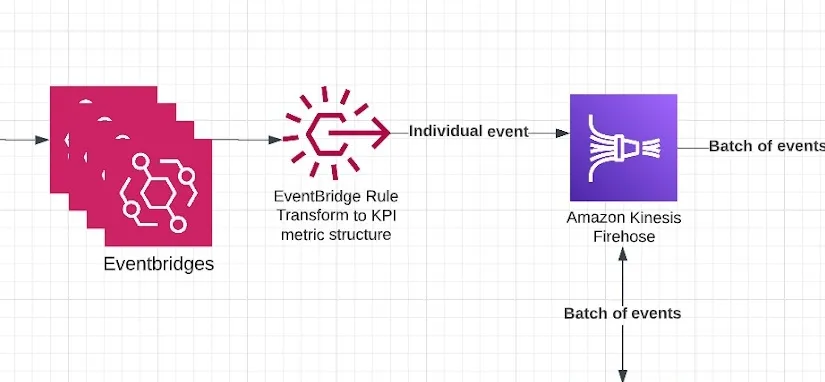
AWS EventBridge
然后这些事件被喂给AWS EventBridge,它会根据预定义的标准处理和转换事件将它们转换为由数据、元数据和指标名称组成的统一格式。这可以通过使用EventBridge Rule来实现。由于我们的架构已经是事件驱动的,而且所有这些事件已经被写入到不同的事件桥中,所以我们只需要在希望将“KPI 相关”数据喂给分析源的地方通过编程的方式添加 EventBridge Rule 即可,这很容易做到。
一旦数据和相关事件被转换成 EventBridge Rule 的一部分,它们就会被发送到 Amazon Kinesis Firehose。这可以通过 EventBridge Rule 的 Target 功能来实现,它可以将转换后的事件发送给各种目标。
被转换为统一 Schema 的事件必须包含以下参数才不会被过滤掉:
metric_name 字段,它映射到被度量的指标。
元数据字典——包含有关事件的所有元数据,每个表(租户隔离)最终都是根据 tenant_id 参数创建的。
数据字典——必须包含 event_time,它告诉我们事件到达的实际时间(因为分析和指标总是需要在一段时间内进行度量和可视化的)。
Schema 结构:
{ "metric_name": "relevant_metric_name", "metadata": { "tenant_id": "relevant_tenant_id", "other_metadata_fields": "metadata_fields", ... }, "data": { "event_time": <time_of_event_in_UTC>, "other_data_fields": <other_data_fields>, ... }}
AWS Kinesis Firehose
AWS Kinesis Data Firehose(简称 Firehose)是为分析引擎聚合多个事件并将其发送到目标 S3 存储桶的服务。
一旦事件数超过阈值(可以是大小或时间段),它们就以批次的形式发送给 S3 存储桶,等待被写入时间序列数据库和其他事件订阅者,例如需要获取所有租户事件的系统。
Firehose 在架构中发挥着重要作用。因为它会等待数据达到阈值,然后按照批次发送事件,所以当我们的代码启动并开始处理事件时,我们将从处理大小可预测的小批次事件开始,避免发生内存错误和其他意外问题。
一旦达到其中一个阈值,Kinesis 对要发送的数据执行最后的验证,验证数据严格是否符合所需的 Schema 格式,并丢弃任何不符合的数据。
我们可以调用 Firehose 中的 lambda 来丢弃不符合要求的事件,并进行额外的转换和填充,如添加租户名称。这涉及到查询外部系统并使用环境运行信息来填充数据。这些属性对于下一阶段在时间序列数据库中为每一个租户创建表来说至关重要。
在下面的代码部分中,我们可以看到:
定义了批次窗口,在例子中是 60 秒或 5MB(只要满足其中一个即可);
验证和转换所有到达事件的数据转换 lambda,确保事件可靠、统一且有效。
处理数据转换的 lambda 叫作 enrich-lambda。请注意,Serverless Framework会将其名称转换为叫作 EnrichDashdataLambdaFunction 的 lambda 资源,所以如果你也在使用 Serverless Framework,请注意这个问题。
MetricsDLQ: Type: AWS::SQS::Queue Properties: QueueName: MetricsDLQKinesisFirehouseDeliveryStream: Type: AWS::KinesisFirehose::DeliveryStream Properties: DeliveryStreamName: metrics-firehose DeliveryStreamType: DirectPut ExtendedS3DestinationConfiguration: Prefix: "Data/" # This prefix is the actual one that later lambdas listen upon new file events ErrorOutputPrefix: "Error/" BucketARN: !GetAtt MetricsBucket.Arn # Bucket to save the data BufferingHints: IntervalInSeconds: 60 SizeInMBs: 5 CompressionFormat: ZIP RoleARN: !GetAtt FirehoseRole.Arn ProcessingConfiguration: Enabled: true Processors: - Parameters: - ParameterName: LambdaArn ParameterValue: !GetAtt EnrichDashdataLambdaFunction.Arn Type: Lambda # Enrichment lambdaEventBusRoleForFirehosePut: Type: AWS::IAM::Role Properties: AssumeRolePolicyDocument: Version: '2012-10-17' Statement: - Effect: Allow Principal: Service: - events.amazonaws.com Action: - sts:AssumeRole Policies: - PolicyName: FirehosePut PolicyDocument: Statement: - Effect: Allow Action: - firehose:PutRecord - firehose:PutRecordBatch Resource: - !GetAtt KinesisFirehouseDeliveryStream.Arn - PolicyName: DLQSendMessage PolicyDocument: Statement: - Effect: Allow Action: - sqs:SendMessage Resource: - !GetAtt MetricsDLQ.Arn
下面是将 Jit 系统中的事件映射到统一结构的代码。这个 EventBridge 将数据发送到 Firehose(以下是 serverless.yaml 的代码片段)。
我们事件映射的代码示例。
FindingsUploadedRule: Type: AWS::Events::Rule Properties: Description: "When we finished uploading findings we send this notification." State: "ENABLED" EventBusName: findings-service-bus EventPattern: source: - "findings" detail-type: - "findings-uploaded" Targets: - Arn: !GetAtt KinesisFirehouseDeliveryStream.Arn Id: findings-complete-id RoleArn: !GetAtt EventBusRoleForFirehosePut.Arn DeadLetterConfig: Arn: !GetAtt MetricsDLQ.Arn InputTransformer: InputPathsMap: tenant_id: "$.detail.tenant_id" event_id: "$.detail.event_id" new_findings_count: "$.detail.new_findings_count" existing_findings_count: "$.detail.existing_findings_count" time: "$.detail.created_at" InputTemplate: > { "metric_name": "findings_upload_completed", "metadata": { "tenant_id": <tenant_id>, "event_id": <event_id>, }, "data": { "new_findings_count": <new_findings_count>, "existing_findings_count": <existing_findings_count>, "event_time": <time>, } }
我们将在系统中已经存在的一个叫作“findings-uploaded”的事件(被其他服务监听)转换为即将被指标服务摄取的事件。
Timestream——时间序列数据库
作为一种实践,如果可能的话,你应该先使用你已经在使用的内部技术,然后在必要的情况下采用其他技术(以减少复杂性)。但对于 Jit 来说,DynamoDB 已经不适用了。
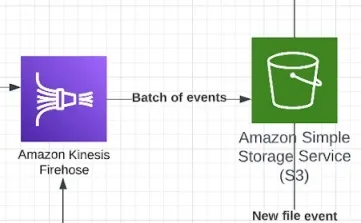
为了在 AWS 上处理时间序列数据(并执行各种查询)的同时保持服务合理的总拥有成本(TCO),我们需要探索新的选项。这些数据将在每个客户的自定义仪表盘(需要时间序列功能中呈现,并严格遵循上述的格式。在比较了可能的解决方案后,我们决定将 Timestream 作为架构的核心,它是一种全托管、低成本的数据库,具有 SQL 风格的查询功能。
这是在实际当中查询这个数据库的示例代码片段。
SELECT * FROM "Metrics"."b271c41c-0e62-48d2-940e-d8c80b1fe242" WHERE time BETWEEN ago(1d) and now()
虽然我们还调研了其他技术,比如 Elasticsearch,但我们意识到,将其作为时间序列数据库要么难以管理和实现(例如,索引和执行租户隔离会更困难),要么成本会更高。而使用 Timestream,每个租户一个表,这很简单,而且它更加经济,因为仅按使用收费,包括写入、查询和存储。乍一看收费的地方似乎很多,但我们的比较显示,根据我们可预测的使用情况和使用它提供的“心智上的轻松”(鉴于它是一个几乎零管理开销的无服务器亚马逊服务),它是更具经济可行性的解决方案。
Timestream 中的数据有三个核心属性可用于优化(你可以在文档中了解更多相关信息)。
维度(Dimensions);
度量(Measures);
时间(Time)。
维度本质上是描述数据的字段,在我们的例子中就是每个客户的唯一标识符(取自用户元数据)和环境。我们利用这些数据从事件中提取出 tenant_id,并将其作为 Timestream 的表名,从而实现了租户隔离。剩余的数据可根据这些字段进行分区,这使以后查询数据变得非常方便。我们使用的维度越多,查询时需要扫描的数据就越少。这是因为数据是根据这些维度进行分区的,从而有效地创建了索引。这反过来提高了查询性能并为我们带来了更大的规模经济效益。
度量本质上是你要递增或枚举的值(如温度或重量)。在我们的例子中,这些是我们在不同事件中测量的值,非常适合聚合数据。
时间很简单直观,它是事件的时间戳(写入数据库时),这在分析中也是一个关键功能,因为大多数查询和测量都基于特定的时间段或窗口来评估成功或改进。
使用 Mixpanel 和 Segment 可视化数据
在有了摄取、转换、批量写入和查询技术之后,构建仪表盘就很容易了。我们研究了使用 Grafana 和 Kibana 等流行的开源工具,它们与 Timestream 集成得很完美,但我们想在客户的 UI 中为客户提供最大化的定制能力,所以我们决定使用内部开发的可嵌入式图表。
在 Firehose 按照预期格式将数据写入 S3 后,有一个专门的 Lambda 可以读取数据,然后将其转换为 Timestream 记录并写入(如上所述,每个租户一个表,在元数据字段中包含 tenant_id)。然后另一个 lambda 将这些预格式化的数据发送到 Segment 和 Mixpanel,为内部摄取和外部用户使用提供整个租户数据的俯瞰视图。
我们利用 Mixpanel 和 Segment 的数据和公开查询 Timestream 的 API(通过 IAM 权限实现租户隔离)为客户构建 UI,让每个客户只能可视化他们自己的数据。
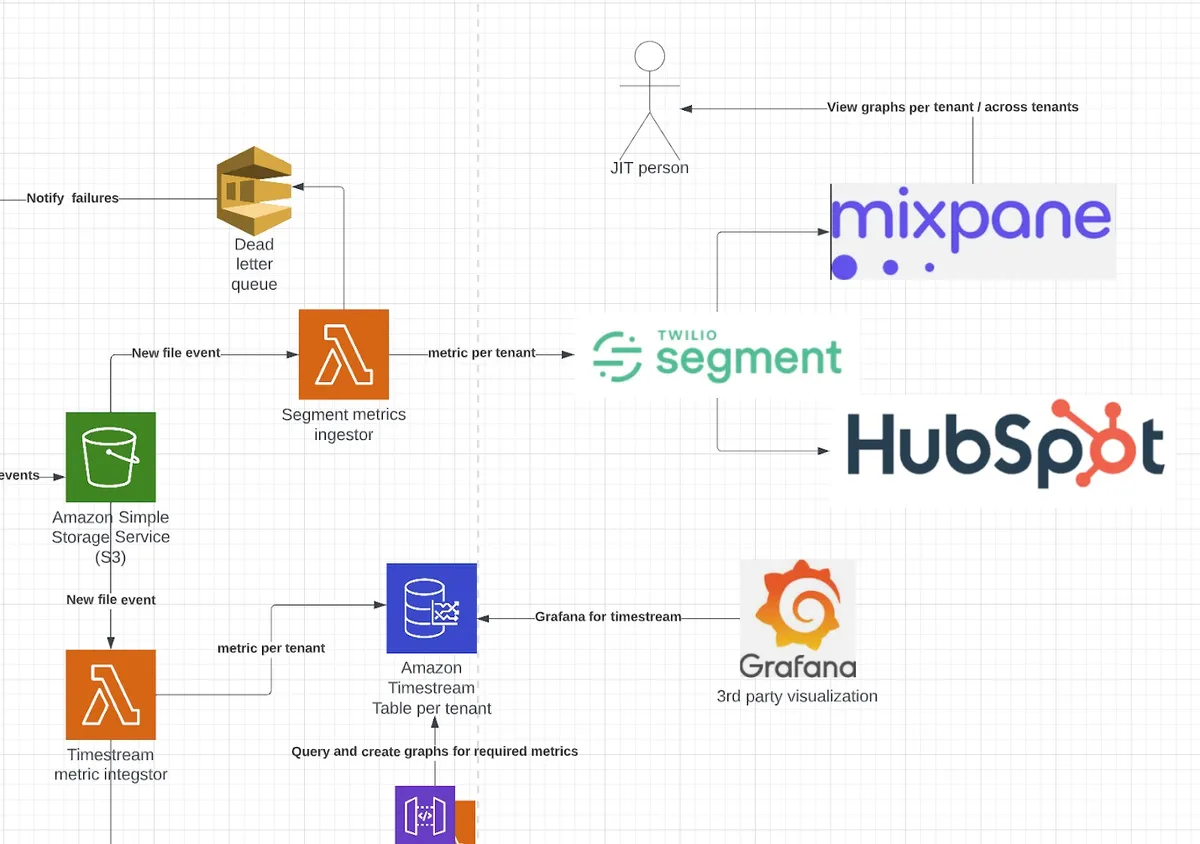
这使得我们能够利用 Mixpanel 和 Segment 作为分析的支撑,为客户提供像乐高积木那样的图表构建块。
通过利用 Mixpanel 和 Segment 等工具,我们可以对图表进行跨租户和跨客户洞察,并以此来优化我们为用户提供的功能和产品。
重要的注意事项
当说到 Timestream 和决定完全无服务器化,确实需要考虑成本和规模限制问题。我们上面讨论了 Timestream 的属性,每一个属性都有一个不能超过的阈值,知晓这一点很重要。例如,每个表的维度限制为 128,度量的最大值为 1024,因此你必须确保系统架构不超过这些阈值。
在内存方面,主要有两种配置:内存和磁性存储(即长期存储。注意,这里的“磁性”是指 AWS Timestream 的长期经济型高效存储,而不是磁带)。相比之下,内存存储价格更高,但查询速度更快,时间窗口有限(在我们的例子中是 2 周)。理论上,你可以在磁性存储上存储多达 200 年的数据,但这一切都有成本问题(我们选择了一年,因为我们觉得这已经足够了,并且可以根据需要动态升级)。 AWS 服务的好处在于大量繁重的工作是自动完成的,例如数据分层会自动从磁性存储迁移到磁盘。
其他限制包括每个账户的表数量(阈值为 50K),查询也需要至少 10MB 数据量(查询时间为 1 秒——可能不如其他引擎快,但成本优势足以让我们在查询速度上做出妥协)。因此,你应该了解总拥有成本,并优化查询,让它们始终高于 10MB 的限制,在可能的情况下甚至更高,同时还要减少客户端的延迟。解决这些问题的一个好办法是缓存数据,不要进行实时的完整查询,你可以通过联合查询将多个查询合并为单个查询。
无服务器乐高积木,永远的王
通过利用现有的 AWS 服务,我们能够快速提升分析能力,管理和维护开销很小,采用低成本的按用计费模式让我们获得了成本效益。这个可伸缩、灵活的系统的最大好处在于,随着客户需求的增加,它也可以轻松地添加新的指标。
由于所有事件已经存在于系统中,并通过事件桥进行了解析,要找到新的相关指标并加入到现有框架中就变得很容易。你可以创建相关的转换,然后立即在系统中拥有一个可以查询的新指标。
通过这个框架,我们可以在未来很容易地基于相同的聚合数据添加“消费者”。通过利用类似乐高的无服务器构建块,我们能够开发出一个可扩展的解决方案,不仅支持大量指标的并行增长,而且可以让架构适应业务和技术的不断演化。
原文链接:
https://www.infoq.com/articles/jit-analytics-architecture/




