
豆瓣成立于 2005 年,是中国最早的社交网站之一。在 2009 到 2019 的十年间,豆瓣数据平台经历了几轮变迁,形成了 DPark + Mesos + MooseFS 的架构。
由机房全面上云的过程中,原有这套架构并不能很好的利用云的特性,豆瓣需要做一次全面的重新选型,既要考虑未来十年的发展趋势,也需要找到与现有组件兼容且平滑过渡的解决方案。一番改造后, 豆瓣数据平台目前形成了 Spark + Kubernetes + JuiceFS 的云上数据湖架构,本文将分享此次选型升级的整体历程。
01 豆瓣早期数据平台
在 2019 年,豆瓣所使用的数据平台主要由以下组件构成:
Gentoo Linux,内部使用的 Linux 发行版;MooseFS ,分布式文件系统;Apache Mesos 负责整个集群的资源管理,以及 Dpark 作为分布式计算框架提供给开发者使用。
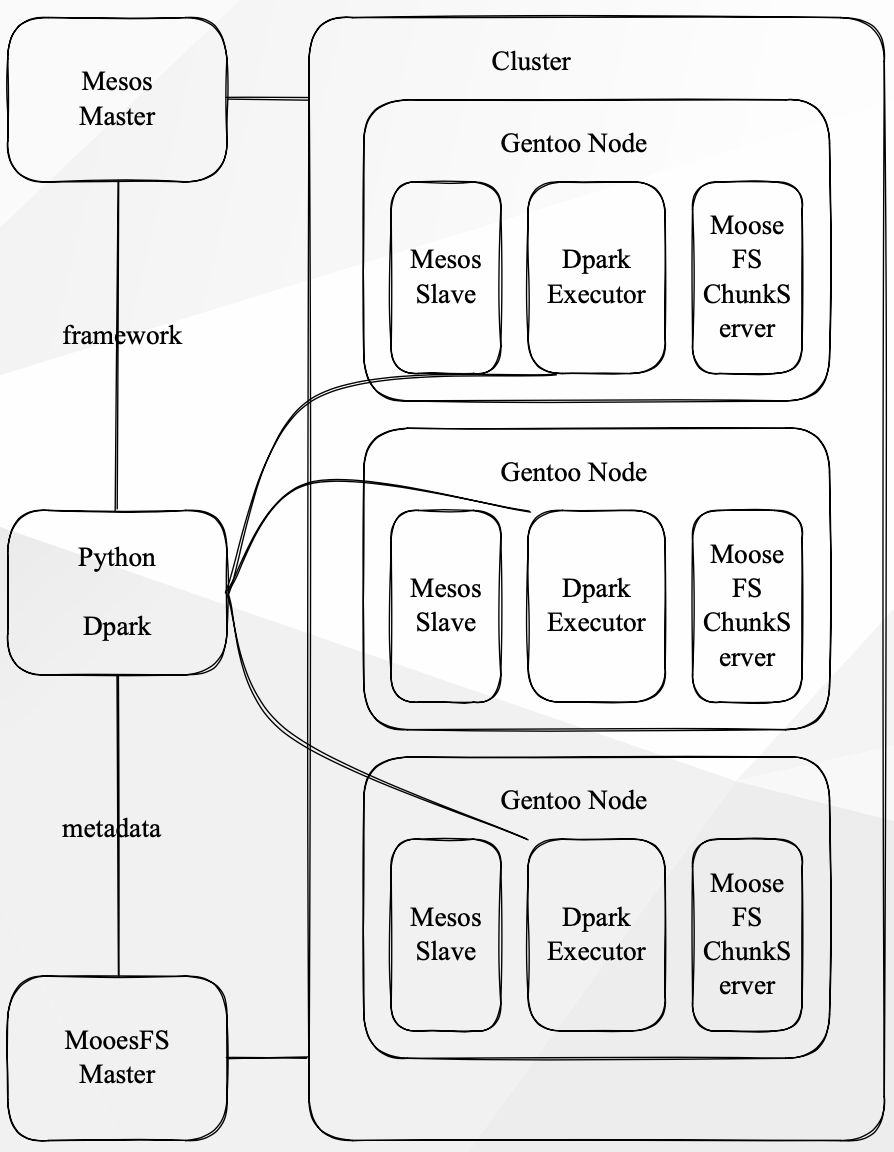
(豆瓣早期数据平台架构)
从上图可以看到在这个数据平台中,计算和存储是一体的,每个计算任务是由 Mesos 进行调度的。计算任务的 I/O 操作都是通过 MooseFS 的 Master 获取元数据,并在本地获取需要计算的数据。此外,GPU 计算集群也是通过 Mesos 进行管理,不同的是, GPU 会基于显存进行共享。
平台组件介绍
Gentoo Linux
Gentoo Linux 是一个较为小众的 Linux 发行版,具有几乎无限制的适应性特性,是一个原发行版。Gentoo Linux 采用滚动更新的方式,所有软件包都直接从社区中获取二进制包,我们则通过源代码构建我们所需的软件包。Gentoo Linux 有一个强大的包管理器,使用它也会带来很多便利,也同时存在一些问题。比如,滚动更新的速度非常快,但对于服务器来说,可能存在一定的不稳定性。
使用源代码构建软件包的好处是当社区没有预编译好我们所需的软件包时,我们可以非常简单地构建出自己所需的软件包,并且当已有的软件包无法满足我们的需求时,也可以很容易地进行定制调整。但这也会带来较高的维护成本。
另外,如果所有软件包都能按照规范进行编写的话,依赖冲突问题几乎是不存在的,因为在打包过程中就已经可以发现。但实际情况是并不是所有软件包都能遵守一个好的依赖描述的约定,因此依赖冲突问题可能仍然存在。
Gentoo Linux 是较为小众的选择,尽管社区质量很高,但是用户也比较少,一些新项目可能没有用户进行足够的测试,我们在实际使用过程中会遇到各种各样的问题。这些问题大部分需要我们自己解决,如果等待其他人回复的话,响应会比较慢。
MooseFS
MooseFS 是一个开源的、符合 POSIX 标准的分布式文件系统,它只使用 FUSE 作为 I/O 接口,并拥有分布式文件系统的标准特性,如容错、高可用、高性能和可扩展性。
对于几乎所有需要使用标准文件系统的场景,我们都使用 MooseFS 作为替代品,并在其基础上开发了一些自己的小工具。例如,我们可以直接使用分布式文件系统来处理 CDN 的回源。在早期版本中,MooseFS 没有主节点的备份功能,因此我们开发了一个 ShadowMaster 作为元数据的热备节点,并编写了一些分析 MooseFS 元数据的工具,以解决一些运维问题。作为一个存储设施,MooseFS 整体比较稳定,并且没有出现重大的问题。
Apache Mesos
Mesos 是一个开源的集群管理器,与 YARN 有所不同,它提供公平分配资源的框架,并支持资源隔离,例如 CPU 或内存。Mesos 早在 2010 年就被 Twitter 采用, IBM 在 2013 年开始使用。
Dpark
由于公司全员使用 Python,因此使用了 Python 版的 Spark,即 Dpark,它扩展了 RDD API,并提供了 DStream。
公司内部还开发了一些小工具,例如 drun 和 mrun,可以通过 Dpark 将任意 Bash 脚本或数据任务提交到 Mesos 集群,并支持 MPI 相关的任务提交。Dgrep 是用于快速查询日志的小工具,JuiceFS 也提供了类似的工具。虽然 Dpark 本身可以容器化,但公司主要的数据任务是在物理服务器上运行的。支持容器化可以让场内任务更好地利用线上业务的模型代码。
02 平台演进的思考
在 2019 年,公司决定将基础设施转移到云端并实现计算和存储分离,以提高平台的灵活性。由于以前的计算任务在物理机上运行,随着时间的推移,出现了越来越多的依赖冲突问题,维护难度不断增加。
同时,公司希望内部平台能够与当前的大数据生态系统进行交互,而不仅仅是处理文本日志或无结构化、半结构化的数据。此外,公司还希望提高数据查询效率,现有平台上存储的数据都是行存储,查询效率很低。最终,公司决定重新设计一个平台来解决这些问题。

平台演进时,我们没有非常强的兼容性需求。只要成本收益合理,我们就可以考虑将整个平台替换掉。这就像是环法自行车比赛中,如果车有问题就会考虑换车,而不是只换轮子。在更换平台时,我们如果发现现有平台的任务无法直接替换,可以先保留它们。在切换过程中,我们有以下主要需求:
Python 是最优先考虑的开发语言。
必须保留 FUSE 接口,不能直接切换到 HDFS 或者 S3。
尽可能统一基础设施,已经选用了部分 Kubernetes,就放弃了 Mesos 或其他备选项。
新平台的学习成本应尽可能低,让数据组和算法组的同事能够以最低的成本切换到新的计算平台上。
03 云上构建数据平台
目前的云上数据平台几乎是全部替换了,Gentoo Linux 的开发环境变成了 Debian based container 的环境, MooseFS 是换用了现在的 JuiceFS,资源管理使用了 Kubernetrs,计算任务的开发框架使用了 Spark,整体进行了彻底替换的,其他的设施是在逐渐缩容的过程,还会共存一段时间。
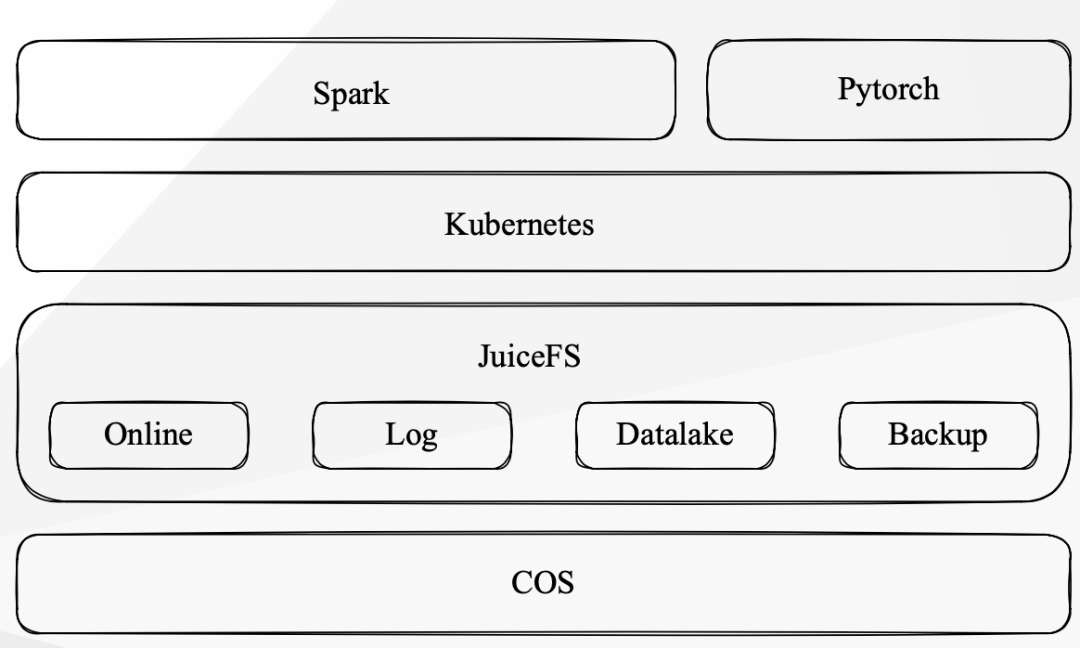
(豆瓣数据平台架构)
JuiceFS 作为统一存储数据平台
为了更好地满足不同的 I/O 需求和安全性考虑,我们会为不同的使用场景创建不同的 JuiceFS 卷,并进行不同的配置。JuiceFS 相对于之前的 MooseFS,创建文件系统更加简单,实现了按需创建。除了 SQL 数据平台外,我们的使用场景基本上都是由 JuiceFS 提供的服务。
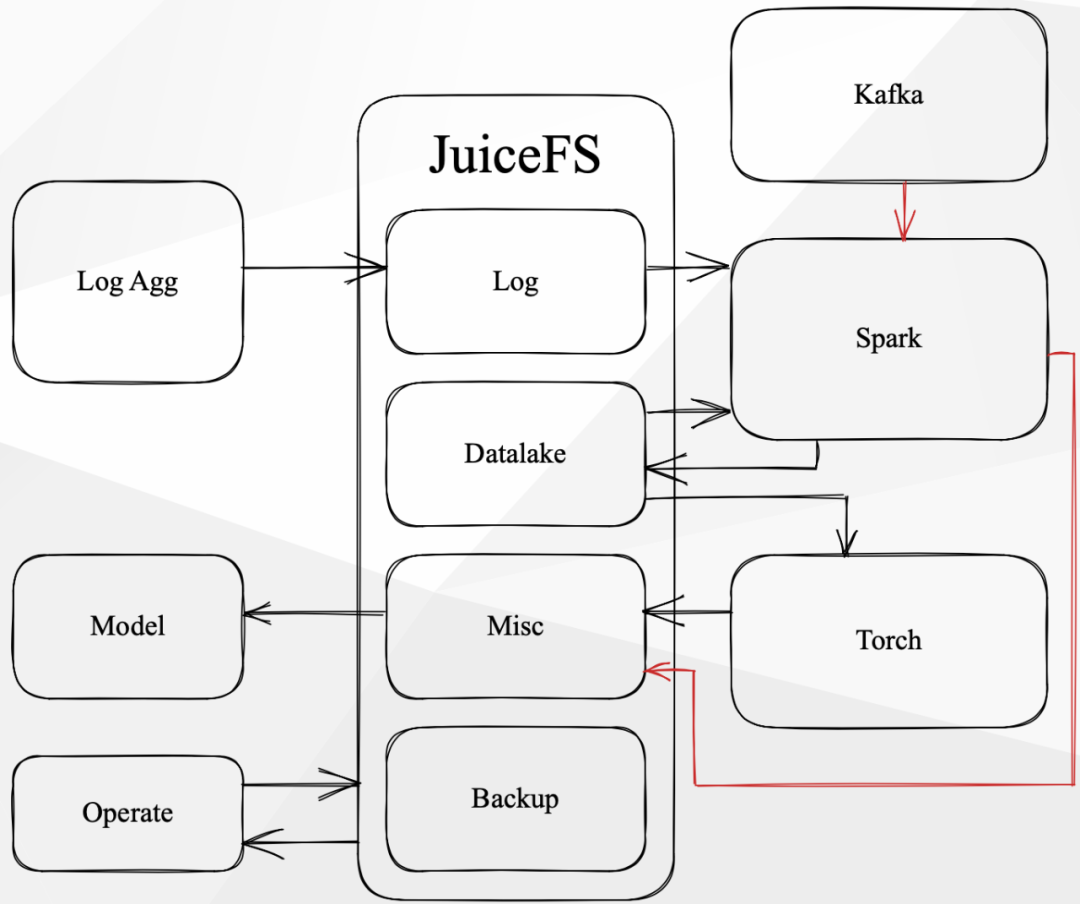
在 JuiceFS 中,数据有几种类型:在线读写、在线读取离线写入、在线写入离线读取、离线读写。
所有的读写类型都在 JuiceFS 上进行,比如日志汇聚到卷中,Spark 可能会读取并进行 ETL,然后将数据写入数据湖。此外,从 Kafka 数据源读取的数据也会通过 Spark 进行处理并写入数据湖。
Spark 的 Check Point 直接存储在另一个 JuiceFS 卷中,而数据湖的数据则直接提供给算法组的同学进行模型训练,并将训练结果通过 JuiceFS 写回。我们的运维团队则通过各种脚本或工具来管理 JuiceFS 上的文件生命周期,包括是否对其进行归档处理等。因此,整个数据在 JuiceFS 中的流转过程大致如上图所示。
新数据平台组件介绍
Debian based container
首先,运维团队选择了 Debian based container 作为基础镜像,我们就直接使用了。我们的计算平台的镜像很大,为了解决任务启动速度的问题,团队在每个节点上预拉取了镜像。
JuiceFS
切换到 JuiceFS 存储系统时,用户感受不到变化,JuiceFS 非常稳定。JuiceFS 比 MooseFS 更好的一点是,它拥有 HDFS 的 SDK,方便了团队将来切换到 Spark 等工具。团队在 Kubernetes 上使用了 JuiceFS CSI,可以直接使用 JuiceFS 作为 Persist Volume,用起来十分方便。JuiceFS 团队沟通高效,解决问题迅速。例如,当 stream 的 checkpoint 频率太高时,JuiceFS 团队早早通知并迅速解决。
Kubernentes
我们早在 1.10 版本的时候就开始试用 Kubernetes。后来豆瓣对外的服务集群在 1.12 版本开始逐步迁移到 Kubernetes,基本上是在现有机器上完成了原地的替换。计算集群则是在上云后开始搭建的,基于 1.14 版本。我们在版本升级方面可能比其他公司更为激进,目前我们的 Kubernetes 版本已经升级到了 1.26 版。
我们选择 Kubernetes 作为计算平台的原因之一是它有比较统一的组件。此外,通过 scheduling framework 或者 Volcano,我们可以影响它的调度,这是我们比较希望拥有的一个特性。
我们还可以利用社区的 Helm 非常快速地部署一些需要的东西,比如 Airflow、Datahub 和 Milvus 等服务,这些服务都是通过 Helm 部署到我们的离线 Kubernetes 集群中提供的。
Spark
在最开始测试 Spark 时,我们像使用 Dpark 一样将任务运行在 Mesos 集群上。之后我们选定了 Kubernetes,使用 Google Cloud Platform 上的 spark-on-k8s-operator 将 Spark 任务部署到 Kubernetes 集群中,并部署了两个 Streaming 任务,但并未进行大规模的部署。
随后,我们确定了使用 Kubernetes 和 Airflow,计划自己实现一个 Airflow Operator,在 Kubernetes 中直接提交 Spark 任务,并使用 Spark 的 Cluster Mode 将任务提交到 Kubernetes 集群中。
对于开发环境,我们使用 JupyterLab 进行开发。厂内有一个 Python 库对 Spark Session 进行了一些小的预定义配置,以确保 Spark 任务能够直接提交到 Kubernetes 集群上。
目前,我们使用 Kubernetes Deployment 直接部署 Streaming 任务,这是一个很简单的状态,未来可能会有一些改进的地方。另外,我们正在准备试用 Kyuubi & Spark Connect 项目,希望能够为线上任务提供更好的读写离线数据的体验。
我们的版本升级非常激进,但确实从社区中获益匪浅。我们解决了日常计算任务中许多常见的优化场景。我们激进升级的原因是希望能够尽可能多地利用社区的资源,提供新特性给开发者。但我们也遇到了问题,例如 Spark 3.2 的 parquet zstd 压缩存在内存泄漏。为了规避这个问题,我们提前引入了未发布的补丁。
现在,我们使用两种方式来读写 JuiceFS 数据:FUSE 和 HDFS。FUSE 主要用于 ETL 任务,例如读写日志和 CSV 文件。我们也会将 Hive 表转存为 CSV 文件下载供未切换到 Spark 的任务进行计算。其他的数据,则直接通过预先配置好的 HDFS(如 Hive Table 和 Iceberg Table)进行读写,这大大简化了我们的工作。
在数据湖的选择上,我们一开始考虑了 Delta Lake,但由于它不支持 Merge on Read,在目前的使用场景存在写放大,我们放弃了它。取而代之,我们选择了 Iceberg,并将其用于 MySQL CDC 处理。我们将数据直接存储在 JuiceFS 上进行读写,并且目前没有遇到任何性能上的问题。未来,如果我们需要扩大规模使用,可能需要与 JuiceFS 的团队沟通一下,看看有哪些优化措施。
04 收获与展望
我们切换到新的计算平台之后,获得了很多原来没有的功能。例如,我们现在可以使用基于 SQL 的大量任务,这些任务的性能比以前好得多,各种报表的实时性也更好了。
与 Mesos 的情况不同,Spark 声明了多少资源就使用多少资源,这与以前的 Dpark 相比有很大的差异,因为以前大家都是公平分享,相互之间会有影响。现在,每个任务的执行时间都比较可预测,任务评估也比较容易预测,整个新平台对于业务数据的读取也有更好的时效性。
以前的历史包袱是相当沉重的,现在我们已经赶上了社区的步伐。去年年末的各种统计和排名都已经迁移到了新的计算平台上,并且运行非常稳定。
我们正在优先考虑采取一些成本下降措施,以实现整个计算集群的动态扩缩容。我们正积极努力实现此目标,并希望提供更加稳定的 SQL 接口。为此,我们计划采用支持 Multi-tenant 的 SQL 服务器,并尝试引入 Spark 3.4 的最新特性。
长远来看,我们希望通过 Spark Remote Shuffle Service 进一步实现存算分离,以便更有效地利用资源。也许未来我们会开发一个“Spark as a Service”,提供给开发者使用。总之,我们正在追赶社区的步伐,并不断努力提升我们的技术水平。
直播回顾:https://www.bilibili.com/video/BV1oM41137Rp/
关于作者
曹丰宇,负责豆瓣数据平台的功能开发和维护
延伸阅读:




