
在过去很长时间里,预训练扩展定律(Pre-training Scaling Law)都是机器学习领域最重要的经验法则之一,它不仅帮助研究人员理解和优化模型训练过程,还为资源分配提供了理论依据。简单来说,当在特定任务上使用参数更大的模型、更多的训练数据和更强的计算能力时,模型性能也会更强。
而 DeepSeek R1 、 OpenAI o1 、文心大模型 X1 以及 QVQ-Max 的出现,则表明 LLM 领域的 Scaling Law 正在发生变化。这类模型在数学、代码、长程规划等问题上的表现尤为突出,而且其推理能力提升的关键,就是后训练阶段中强化学习训练和推理阶段思考计算量的增大。一方面意味着后训练扩展定律(Post-Training Scaling Laws)正在引发社区对于算力分配、后训练能力的重新思考,另一方面也让强化学习(RL,Reinforcement Learning)成为了大语言模型能力提升的新引擎。
就在本周,蚂蚁技术研究院和清华大学交叉信息院吴翼团队,发布了训练速度最快最稳定的开源强化学习训练框架 AReaL(Ant Reasoning RL),并公开了全部数据和完成可复现的训练脚本。在最新的 AReaL v0.2 版本 AReaL-boba 中,其 7B 模型数学推理分数刷新同尺寸模型 AIME 分数纪录,并且仅仅使用 200 条数据就在 AIME 2024 上复刻 QwQ-32B 的推理结果,相当于仅仅使用了 200 美金的计算成本,让所有人都可以以极低的成本实现最强的推理训练效果。
后训练定律崛起,强化学习重塑大模型能力边界
后训练扩展定律的兴起是大语言模型能力进化的重要转折点,该定律表明训练阶段的计算量不再只和参数量的上升有关,同时也会包含强化学习探索时大语言模型推理的计算量。这也就意味着可以使用微调、剪枝、量化、蒸馏、强化学习和合成数据增强等技术,进一步提高预训练模型的性能。
以强化学习为例,作为一种对标注数据数量要求更少的机器学习技术,它只通过奖励模型来训练大模型,使其学习做出与特定用例相符的决策。大模型的目标是在与环境交互的过程中,随着时间推移最大化累积奖励。
例如,一个大语言模型可以通过用户的“点赞”反应获得正向强化,这种技术被称为基于人类反馈的强化学习 (RLHF)。另一种更新的技术是基于 AI 反馈的强化学习 (RLAIF),它使用 AI 模型的反馈来指导学习过程,从而简化后训练的优化工作。
通过引入强化学习机制,大语言模型可借助实时反馈对生成内容进行动态优化,使其输出更精准地适配人类偏好,从而将海量知识储备有效转化为针对特定场景的任务解决能力。
不过,强化学习虽然效果显著,但针对大语言模型的大规模强化学习训练门槛却一直很高:
例如在数据方面,某些大规模强化学习训练需要大量高质量的人类反馈数据,需要收集和处理大量的人类偏好数据,可能还会涉及隐私和伦理问题。
计算资源方面,大规模强化学习训练需要强大的计算资源,包括 GPU 集群和高效的分布式训练算法。
成本方面,大规模强化学习训练所需的时间成本、财务成本都比较高,对不少团队来说都是一个挑战。
算法复杂度方面,强化学习算法设计比较复杂,奖励模型构建和策略优化都需要考虑在内,还需要处理自注意力机制、长距离依赖等问题。
模型设计方面,也需要平衡模型的复杂度与性能,同时由于奖励模型准确率直接影响强化学习的效果,还需要高质量训练数据的支持。
生成评估方面,需要结合人工评估与自动指标,如果是多模态模型,还需要应对跨模态任务评估的难题。
总体来说,大规模强化学习训练的流程复杂,涉及模块繁多(如生成、训练、奖励判定等),这为实现高效稳定的分布式训练带来了很多挑战;其次,类似 DeepSeek R1 这样的推理模型输出长度会很长(超过 10K),随着训练持续变化,很容易造成显存和效率瓶颈;最后,目前的开源社区中缺乏高质量的强化学习训练数据,也缺乏完整可复现的训练过程。
针对上述挑战,蚂蚁技术研究院于上个月正式开源了强化学习框架 AReaL(Ant Reasoning RL)。AReaL 基于开源框架 ReaLHF 构建,旨在训练每个人都可以复现和贡献的大型推理模型。

AReaL 秉承完全开放与可复现的理念,团队将持续公开包括 LRM 训练模型的全套代码、完整数据集及系统化训练方案。项目所有核心算法组件完整开源,开发者可自由进行模型验证、功能改进及实际应用,推动大型推理模型、智能体开发领域的协作创新。
此外,AReaL 可以适配多种计算资源环境,从单节点开发调试环境到千卡级 GPU 集群分布式训练场景均可实现全流程高效执行。在首次发布的 v0.1 版本中,就包含了基于 AReaL 的可复现实验,涵盖 1.5B 和 7B 参数的推理模型,并在多种计算预算下进行了验证。
通过 AReaL ,开发者可以在 40 小时内稳定完成 1.5B 的强化学习训练,使其在数学推理任务能力上超越 o1-Preview ;或者在 Qwen2.5-7B 大模型上实现稳定复现的强化学习训练,从而系统化验证 thinking token 的演化规律及模型数学推理能力的持续优化过程。
而本周发布的 v0.2 版本 AReaL-boba ,则让普通人也拥有了“手搓” QwQ-32B 的能力。
开源框架革新:三大核心解锁强化学习规模化
AReaL 团队表示,新版本“boba” 的命名一方面源自团队对珍珠奶茶的偏爱,另一面也是希望强化学习技术能如奶茶成为大众饮品一般,渗透至 AI 开发的每个日常场景,普惠整个社区。事实上,AReaL-boba 也完全拥有这样的能力,其技术亮点主要表现在以下三个方面:
全面拥抱 SGLang 框架,训练速度大幅提升
AReaL-boba 是首个全面拥抱 SGLang 推理框架的开源训练系统,并充分利用了 SGLang 推理框架的多种优势,包括更高的推理性能、更低的资源消耗、更高的灵活性、易于集成等等。
AReaL-boba 在初代 AReaL 版本的基础上实现了突破性进展:通过深度整合 SGLang 框架并实施多维度工程优化,AReaL-boba 能够灵活适配不同的计算资源配置,并且性能提升呈现出显著的规模效应——在 1.5B 参数模型上训练速度提升 35%,7B 模型加速达 60%,当扩展至 32B 大模型时更获得 73% 的显著性能跃升,为大规模强化学习训练提供了高效的解决方案。
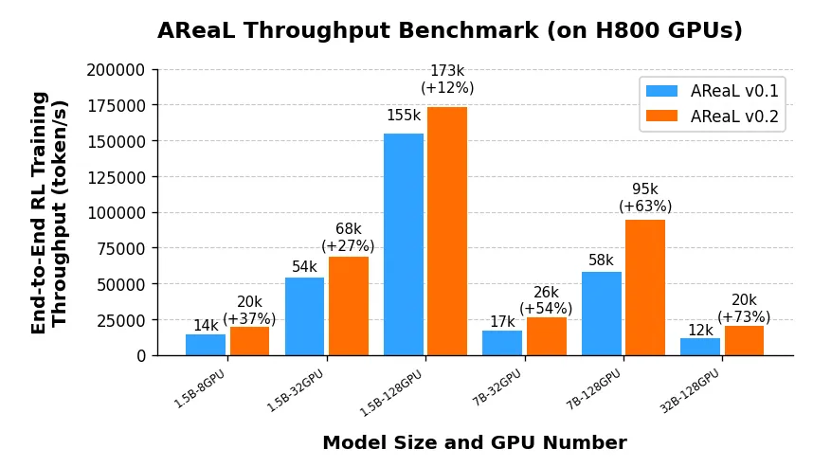
此外,AReaL-boba 也展现出了卓越的大模型训练效率:仅需 128 张 H800 显卡即可在 24 小时内完成 1.5B 参数的 SOTA 推理模型训练;当扩展至 256 张 H800 时,可在 48 小时内完成 7B 参数的 SOTA 推理模型训练。这些也得益于 AReaL-boba 在系统级方面的优化:
生成后端升级
AReaL-boba 的生成后端升级到了 SGLang v0.4.0 ,并通过 RadixAttention 机制显著提高了从同一提示中采样多个响应的场景中的吞吐量。此外,SGLang 会在权重更新时自动刷新 Radix 缓存,从而确保强化学习的正确性。
优化可变长度序列与大批量训练
为了高效处理可变序列长度问题, AReaL 团队摒弃了填充操作,转而将序列打包为 1D 张量。通过动态分配算法(近似)最优地将序列分配到最大令牌预算下,在平衡微批次规模的同时最小化微批次数量。该方法能最大化 GPU 内存利用率,从而支持高效处理大规模可变长度输入。
面向千卡级 GPU 扩展的高性能数据传输
AReaL 团队采用了基于 InfiniBand/RoCE 协议的 GPU 直连远程直接内存访问(GDRDMA)技术,配合 NVIDIA 集合通信库(NCCL),实现了 GPU 间的直接通信。该技术绕过了传统 CPU 中介传输和 PCIe 总线瓶颈,相较于基于以太网的传统方案,显著降低了通信延迟并提升了传输吞吐量。即使在包含 1000 块 GPU 的超大集群中,也能将生成到训练流程的数据传输开销控制在 3 秒以内。
种种技术加持之下, AReaL-boba 成为了目前训练速度最快的开源框架。
强化学习赋能,7B 模型数学推理分数刷新开源社区纪录
数学推理是大型模型实现强人工智能的关键,它不仅能直接提升模型在数学相关任务的表现,更通过培养逻辑严谨性、抽象思维和问题分解能力,间接增强模型在通用领域的推理效能。
AReaL 团队基于 Qwen-R1-Distill-7B 基础模型,通过大规模强化学习训练,在 48 小时内即可取得领域最佳的数学推理能力,并刷新开源社区新纪录,实现 AIME2024 61.9 分与 AIME2025 48.3 分的优异成绩,显著超越 OpenAI o1-preview 模型。
与基础模型相比,AReaL-boba 通过强化学习实现了模型的能力跃迁,分别较 AIME2024 和 AIME2025 提升了 6.9 分与 8.6 分,进一步验证了强化学习规模化应用在推理模型优化中的关键价值。
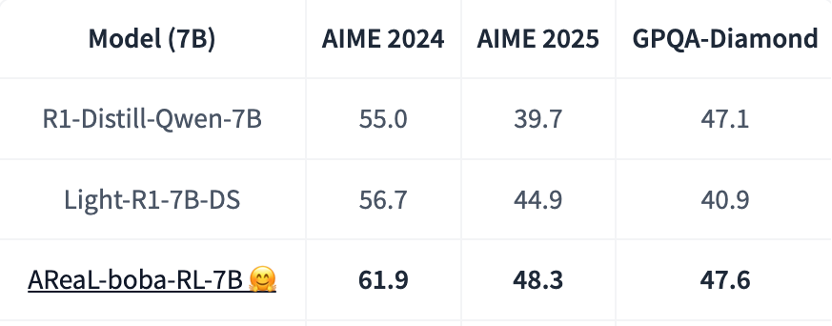
基于 AReaL 完全开放与可复现的理念, AReaL-boba 在开源推理模型的基础上也开源了所有的训练数据 AReaL-boba-106k ,以及全部的训练脚本和评估脚本。同时在项目官方仓库上,AReaL 团队也放出了极其详细的技术笔记,总结了大量训练中的关键点,包括 PPO 超参数、奖励函数设置、正则化设置、长度上限设置等等。
例如,AReaL 团队以 PPO 超参数作为核心训练算法,为节省计算资源,移除了策略评估网络(Critic 模型)。同时,将折扣因子 γ 和广义优势估计(GAE)参数λ均设置为 1。这些配置策略与 Open-Reasoner-Zero 项目的实现方案保持一致。
在奖励函数设置方面, AReaL 团队则采用了稀疏序列级奖励机制。模型被要求将最终答案用方框标出(即\boxed{}格式),随后系统会对该答案进行验证。若答案正确则给予 +5 的奖励,错误则处以 -5 的惩罚。同时,由于 KL 散度奖励可能对模型性能产生负面影响,尤其是在长思维链训练中,因此将其系数设为 0 以消除干扰。
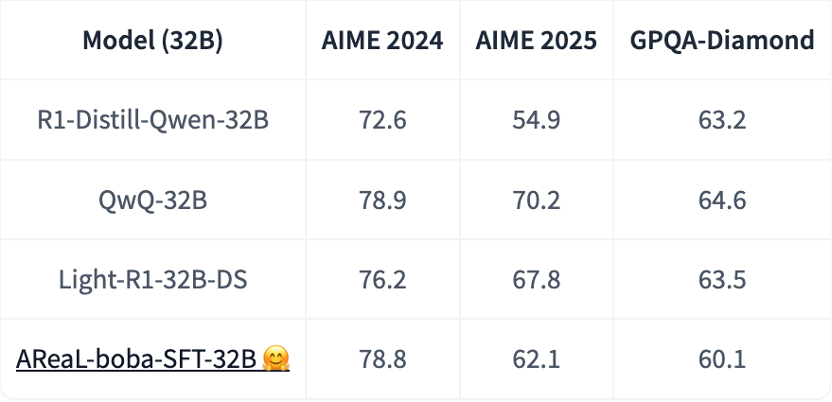
创新性蒸馏技术,200 条数据轻松复刻 QwQ-32B
针对 32B 参数规模的推理模型,AReaL 团队进一步精简了训练数据并发布了 AReaL-boba-200 数据集以及相关训练脚本,在以 Qwen-32B-Distill 作为基础模型时, AReaL-boba 采用轻量级监督微调(SFT)技术,在 AIME2024 评测中成功复现了 QwQ-32B 模型的推理性能,并且整个训练过程仅需 200 美元的计算成本,为开发者甚至普通人提供了低门槛实现高性能推理训练的可行性路径。
结尾
与传统的深度学习算法相比,强化学习更为复杂,且模块更多,这使得搭建适应强化学习算法的训练系统成为了一件颇具挑战的课题, AReaL 作为一个专为大型推理模型设计的灵活高效的开源强化学习系统,如今已经更新到了训练速度更快的 AReaL-boba 版本,这无疑为强化学习在大模型时代的创新应用注入了新的活力。
值得一提的是,AReaL 团队的核心成员均来自蚂蚁研究院强化学习实验室,以及交叉信息研究院吴翼团队,项目也借鉴了大量优秀的开源项目,比如 DeepScaleR、Open-Reasoner-Zero、OpenRLHF、veRL、SGLang、QwQ、Light-R1 和 DAPO。作为国内第一个完整开源(数据、代码、模型、脚本全开源)的项目团队,AReaL 的初衷就是真正实现 AI 训练的普惠。
在项目官方仓库中,AReaL 团队也列出了团队后续的开源计划和目标,包括异步训练、训练吞吐优化、数据集和算法升级,以及代码和 Agent 智能体能力支持。也许,下一个 AReaL 版的“奶茶”,也已经在路上。
这不仅是一次技术开源尝试,更是推动算力普惠化的积极探索——当 AReaL-boba 将大模型强化学习训练简化为如同点奶茶般简易的操作时,人人都能“手搓”大模型的时代,可能马上就要来临了。




