
作者|纵腾集团数据技术架构师 张彬华
福建纵腾网络有限公司(简称“纵腾集团”)成立于 2009 年, 以“全球跨境电商基础设施服务商”为企业定位,聚焦跨境仓储与物流, 为全球跨境电商商户、出口贸易企业、出海品牌商提供海外仓储、商业专线物流、定制化物流等一体化物流解决方案, 旗下拥有谷仓海外仓 、云途物流 、WORLDTECH 等知名品牌 。
随着纵腾集团业务的快速发展,各产品线提出的数据需求越发严格,而早期基于多套 CDH 大数据架构的技术栈和组件繁杂,开发和运维难度高、效率低,数据质量和时效难以保障,已无法满足当下数据分析需求,严重影响相关工作的开展。因此,纵腾集团在 2022 年正式引入 Apache Doris,基于 Apache Doris 构建了新的流批一体数据架构,同时建立了以 Apache Doris 为核心的数据中台。 构建过程中对读写时效性、服务的稳定性及高并发读写等多方面进行了优化,在这一过程中我们也积累了诸多实践经验,在此总结分享给大家。
早期架构
早期数仓架构主要分为两套基于 CDH 的大数据集群,这两套架构用于不同产品线的数仓需求、数据大屏和 BI 报表等应用。
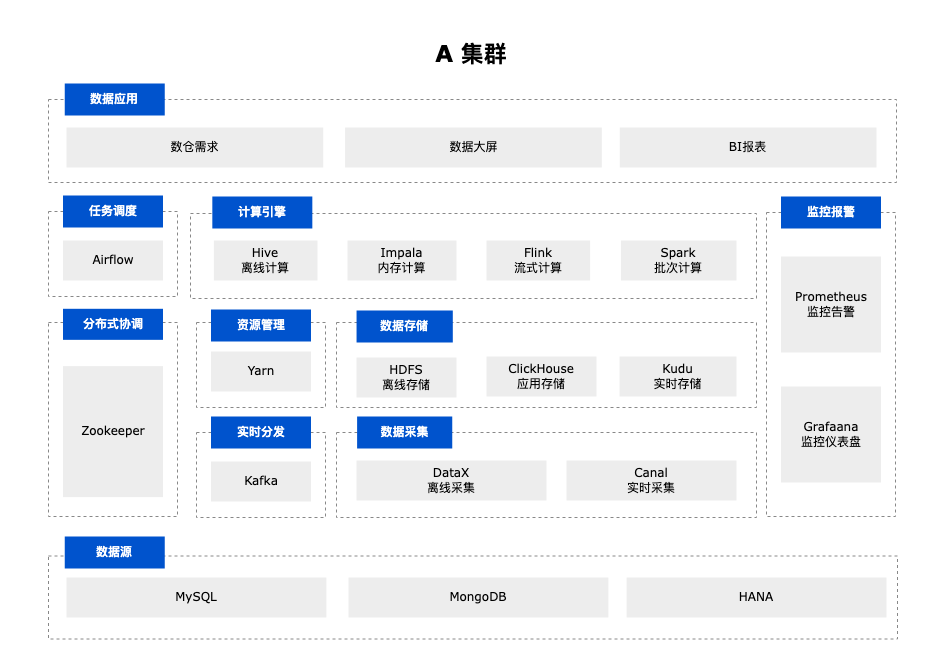
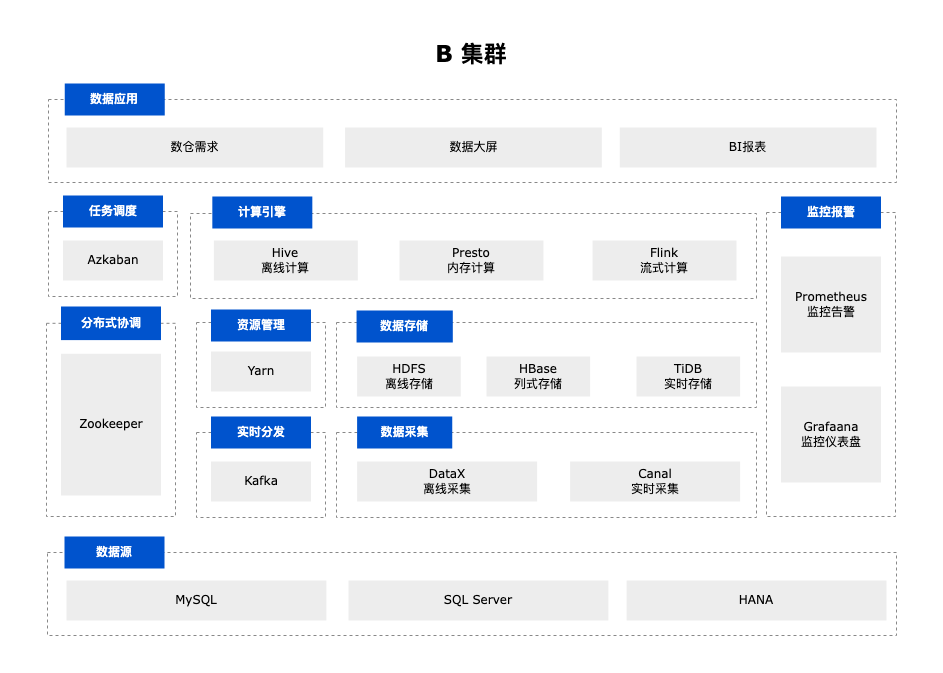
这两套架构为独立的数据管道,具有耦合度低,集群间相互独立等特点,便于精细化管理。但随着业务需求的不断变化,这样的特点也引发出许多新的问题。
遇到的问题
元数据和数据质量缺乏管控,数据质量无法得到保证
不同业务数据独立存储维护导致数据孤岛,不利于数据整合
每个集群的机房分布不一,维护成本非常高
集群间的技术栈和组件较多且存在差异性,对统一开发运维和数据整合都极具挑战性
架构选型
为了解决早期架构的痛点、更好满足日益严苛的数据需求,我们希望能有一款产品帮助我们快速构建流批一体的数仓架构、构建数据中台服务。

我们对传统数仓、 实时数仓和数据湖进行了对比。从上图可知,传统数仓可以支撑超 PB 级的海量数据,但是交互查询性能相对差一些,偏离线场景,不满足我们对数据实时性的要求;数据湖可以支撑超海量的数据,支持数据更新,查询性能适中,但是数据湖近两年才开始应用,成熟度较低,使用风险较大;实时数仓适用 PB 级数据存储,支持数据更新且查询性能非常好。结合我们的要求,实时数仓与我们的使用和需求场景都比较贴合,因此我们最终决定选择实时数仓作为数据底座。
接着我们对市面上较为流行的三款实时数仓:ClickHouse、Apache Druid、Apache Doris 进行了选型对比,对比图如下:
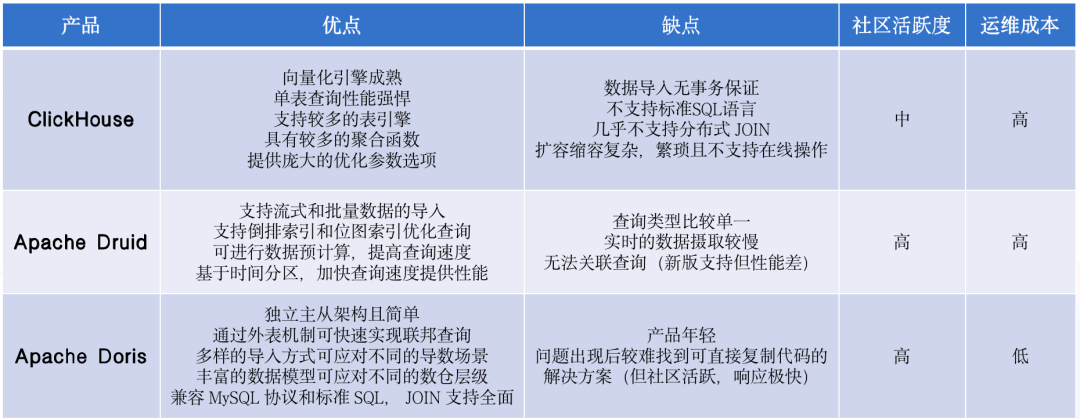
对比可知,Apache Doris 优势明显、性价比更高,具有独立主从架构简单、运维更灵活便捷、丰富的数据模型、优秀的查询性能和周全的生态规划等诸多优势,对比这三个产品,Apache Doris 最符合我们的选型要求。
新数据架构
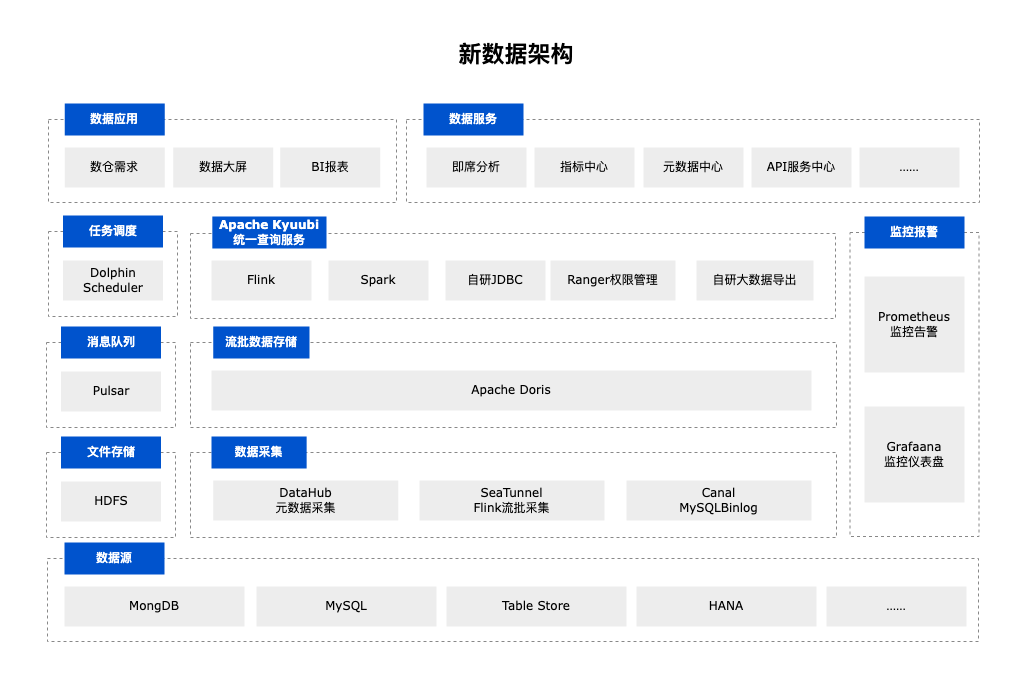
新数据架构基于 Apache Doris 简化了数据采集、存储和计算的流程:
结合 DataHub 实现自研元数据采集和周期管理
通过 Seatunnel 集成 Flink Doris Connector 稍加改造实现全量加增量数据的一体化采集
简化存储媒介,对 ClickHouse、Kudu、HBase 等技术栈进行收敛,由 Apache Doris 进行流批数据的统一存储
以 Apache Doris 为核心数据底座,结合 Apache Kyuubi 的 JDBC 引擎直连查询(自研)和 Spark 引擎中的 Spark Doris Connector 进行 ETL 开发(原生),统一计算引擎管理、权限管控和对外服务。
基于上述几点进行了数据应用开发及对外提供数据服务,构建了数据中台。
数据中台
我们以 Apache Doris 为核心底座创建了数据平台,核心功能包括:指标中心、元数据中心、基础配置中心、即席分析和数据接口服务中心,其中指标中心和即席分析的数据主要来源于 Aapche Doris ,当前已上线几百个指标。
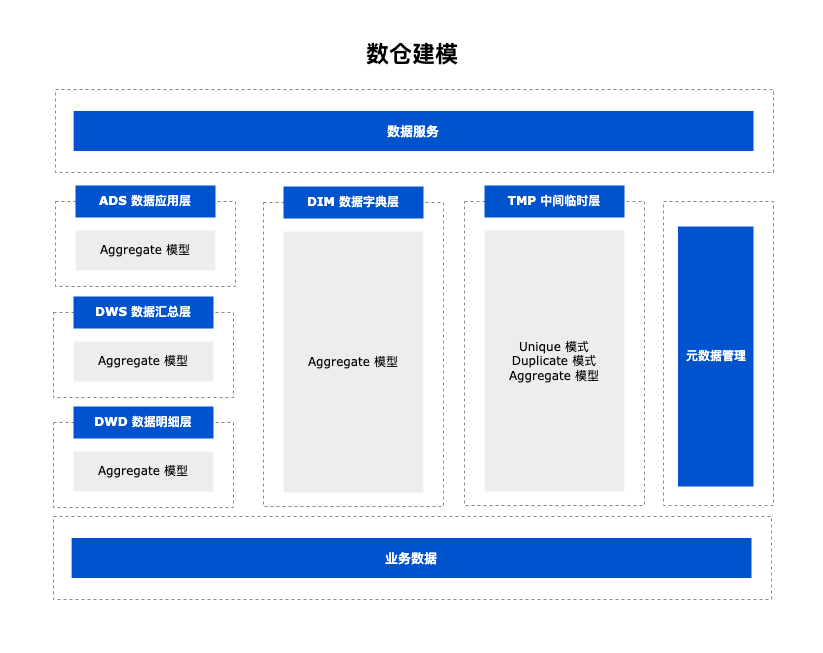
数仓建模
我们结合 Apache Doris 的特性重新对数仓进行了建模,数仓分层与传统数仓类似,其中 ODS 数据为存量加增量一体的导入模式,同时为防止出现[随机查询结果问题],ODS 层最终选用 Unique 数据模型,相比于 Aggregate 模型可以实现写时合并(Merge-on-Write),有效提高数据实时性,且 Aggregate 模型查询性能更接近于 Duplicate 模型,对于 ODS 层是非常好的选择。
DIM/DED/DWS/ADS 层主要选用 Aggregate 数据模型;Aggregate 数据模型提供的四种聚合方式可以在大部分场景下达到事半功倍的效果,帮助我们快速应对不同的需求场景。
SUM: 能够高效实现 PV 类指标计算,但对于 UV 类的指标需要考虑预去重。
MAX/MIN: 常用于最大最小运单时间节点类指标或包裹体积/重量最大最小值的指标计算。
REPLACE_IF_NOT_NULL: 可以自动地过滤空值,非常便捷地实现仅记录最后一条数据,适用于大部分 DW 场景。
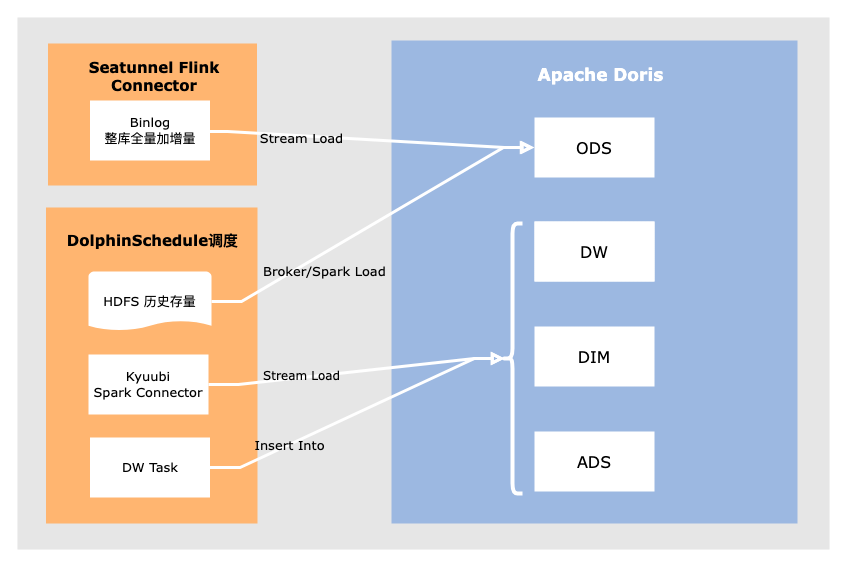
数据导入
ODS 层的数据导入目前主要以 Stream Load 为主,在 HDFS 上的历史存量数据也会通过 Broker Load 或 Spark Load 导入。DW 层数据主要以 insert into 方式导入,同时为减轻 Doris 内存压力,我们将部分 ETL 任务放到 Kyuubi On Spark 引擎上去计算,目前在 DolphinScheduler 每天平稳调度 Doris DW 任务有上万个,其中大部分为 T+1 任务,小部分为小时级任务。
实践经验
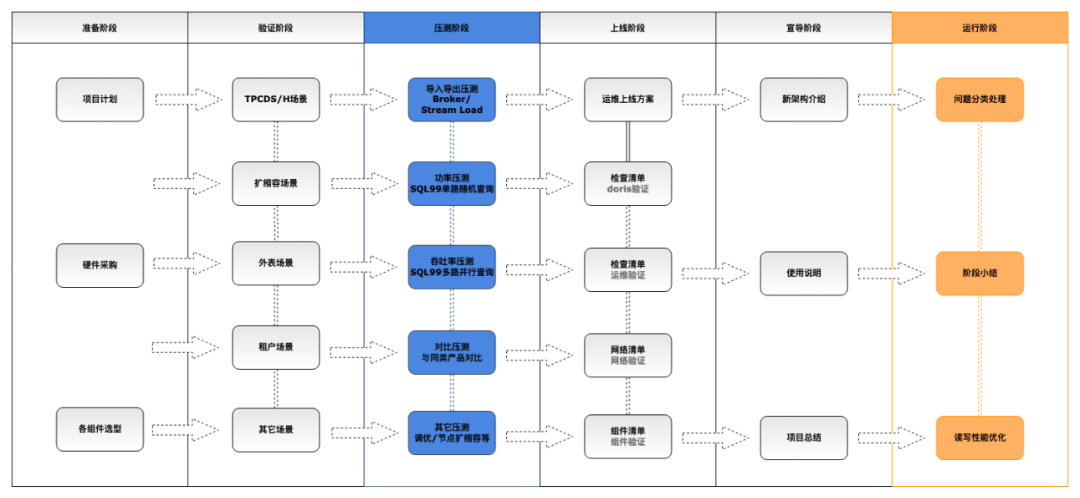
对于以 Apache Doris 为核心的新数据架构,我们规划了 6 个阶段进行运行测试,直至可以上线运行。(重点关注压测阶段和运行阶段,有一些调试优化经验分享给大家)
1、准备阶段
引入 Apache Doris 时是 2022 年 2 月,因此选择当时最新版本 Apache Doris 0.15 Release 版本进行应用,主要考虑维度如下:
支持事务性插入语句功能
支持 Unique Key 模型下的 Upsert
支持 SQL 阻塞 List 功能,可以通过正则、哈希值匹配等方式防止某些 SQL 的执行
官方不支持跨两位版本号进行升级,而 0.15 为当时最新的 Release 版本,选用该版本利于后期版本升级
可通过资源标签的方式将一个 Apache Doris 集群中的 BE 节点划分为多个资源组,实现多租户和资源隔离
该版本提供了官方认可的 Flink-Doris-Connector/Spark-Doris-Connector/DataX Doriswriter 等插件,利于 ETL 流程建设
2、验证阶段
该阶段主要是为了二次验证官方文档中介绍的功能是否满足我们的实际运用场景,比如生态扩展中的 Connector、外表联邦查询、各种 Load 方式、多租户隔离及物化视图等。
3、压测阶段
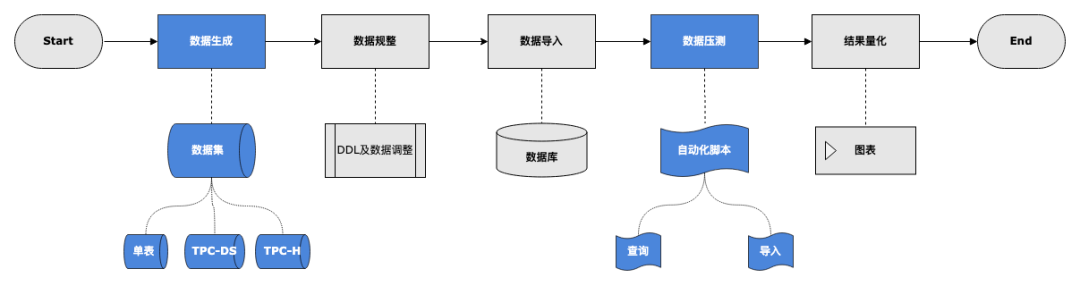
压测阶段首先进行数据生成,数据集选用的是 TPC-DS 数据,接着根据 Doris 的特性对 DDL 和 SQL 等规则进行对应调整,最后通过脚本将数据导入到 Apache Doris 存储中,再通过自动化脚本进行查询及导入压测,最终将压测结果输出到 MySQL 表中,量化为图表进行展示。下方为本阶段的基本配置及压测过程介绍:
- 硬件环境
内存:256G
CPU:96C
硬盘:SSD 1.92T * 8
- 软件环境
Apache Doris 版本:0.15-release/1.0-release(该阶段进行时,1.0-release 版本刚好发布)
Apache Doris 集群:3 FE + 9 BE
系统:CentOS Linux release 7.9.2009
- 数据集信息
我们生成了 1T、5T、10T 的 TPC-DS 数据集,1T 的数据集约有 30 亿数据量。

查询压测
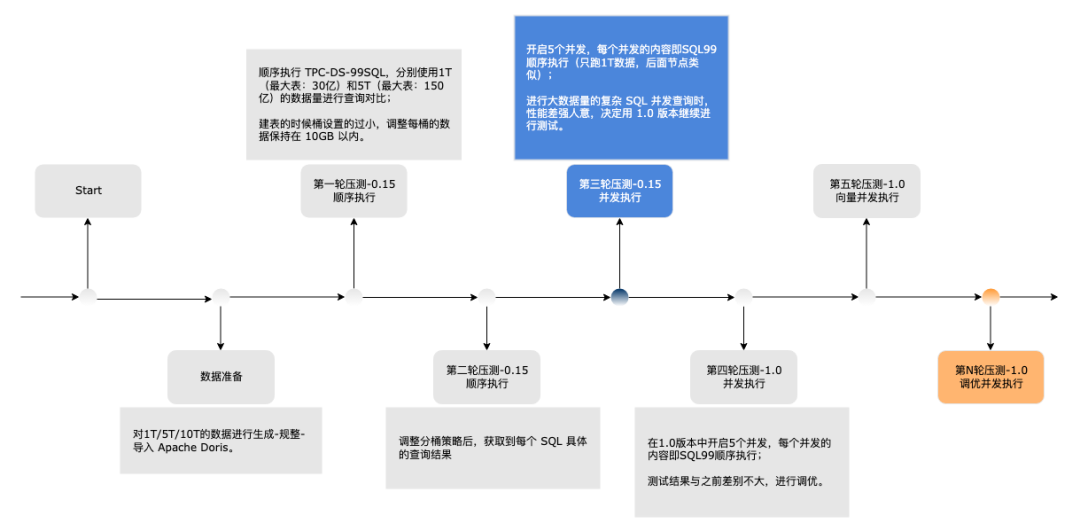
压测过程中,最初使用 0.15-release 版本进行测试,正巧 1.0-release 版本发布,后决定更换为 1.0-release 版本进行后续的压测。下图是基于 1T 的 TPC-DS 数据在同等硬件配置环境下和某商业 MPP 数据库的对比结果:
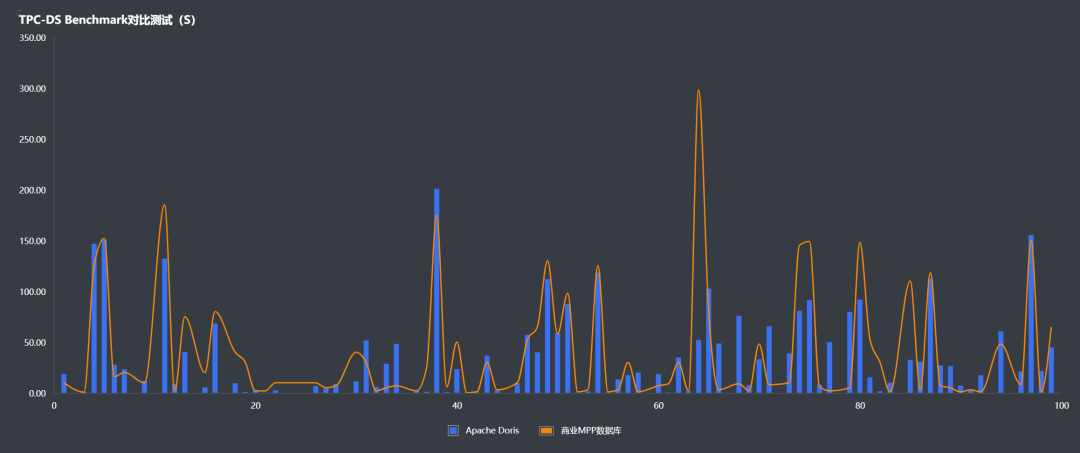
如图所示,Apache Doris 的查询压测性能优异,有着明显的性能优势,作为开源产品能够达到这样的效果是非常优秀也是十分不易的。
导入压测
导入方式:通过 DataX Doriswriter 以 StreamLoad 方式进行写入压测
数据来源:为避免因 Source 端原因影响写入时效,选择 100 张相同大表,即 100 个并发从内网 Hive 中导入(例如 tpcds-ds 的 store_sales_1t 表)
数据模型:选用 Unique 模型(模拟 ODS 层),同时为充分考虑 Compaction 性能及小文件场景,每张表设置 70 个 Tablet
经调整优化后,最大写入时效为 269 MB/S&680K ops/s,平均写入时效 70 MB/S&180K ops/s,写入时效大幅提升。
4、上线阶段
该阶段主要是确认 Apache Doris 上线需要的检查清单、预调参数、BE 资源组规划及用户权限的划分。
检查清单:包括但不限于 FE & BE 端口、网络检查及 Apache Doris 的一些功能性验证,例如读写是否正常等。
预调参数:确认优化后的 FE&BE 参数是否配置,是否开启
global enable_profile、动态分区以及数据盘保存位置是否有误等。BE 资源组:由于我们需要通过 Apache Doris 的多租户特性对不同的用户进行资源隔离,所以需要提前规划好每个 BE 节点对应的资源组。
用户权限:对于不同的用户群体提前规划好权限范围,比如分析师开发只需要
SELECT_PRIV权限,而 ETL 工程师需要SELECT_PRIV、LOAD_PRIV 和CREATE_PRIV权限。
5、宣导阶段
该阶段主要是输出前面各阶段的 TimeLine、总结以及上线后使用 Apache Doris 的注意事项说明,比如我们用到多租户隔离,那么 DDL 建表时则需要在 Properties 中显示指定各副本对应的资源组:
create table zt_table......properties( "replication_allocation"="tag.location.group_a:1, tag.location.group_b:1, tag.location.group_c:1")6、运行阶段
Tablet 规范问题
问题描述: 上线运行一段时间后,随着越来越多的数据增长,集群每次重启后一周左右,读写就会开始变得越来越慢,直到无法正常进行读写。
问题处理:
经过对生产和 UAT 环境的对比测试以及对数仓表的 Schema 的分析,我们发现有些表数据并不大,但是 Bucket 却设置的非常大。

结合
show data from database命令,我们将整个集群所有表的 Bucket 信息罗列出来,明确了大部分表的 Bucket 设置的不合理;而当前集群共 20T 左右数据,平均 1T 数据近 10W 个 Tablet,这就会导致小文件过多,造成 FE 元数据负载过高,从而影响导入和查询性能。定位原因后与社区小伙伴二次确认,并根据官方建议将 Bucket 设置不合理的表全部调整,调整后集群逐步恢复读写正常。(即将发布的 Apache Dorie 1.2.2 版本将推出 Auto Bucket 动态分桶推算功能,可以根据历史数据和机器数目自动推算新建 Partition 的分桶个数,保证分桶数始终保持在合理范围内,可有效解决上述问题)
问题小结:
Tablet 数 = 分区数 * 桶数 * 副本数
1TB 数据的 Tablet 数量控制在 8000 个左右(三副本控制到 2.4W 左右)
建议大表的单个 Tablet 存储数据大小在 1G-10G 区间,可防止过多的小文件产生
建议百兆左右的维表 Tablet 数量控制在 3-5 个,保证一定的并发数也不会产生过多的小文件
集群读写优化
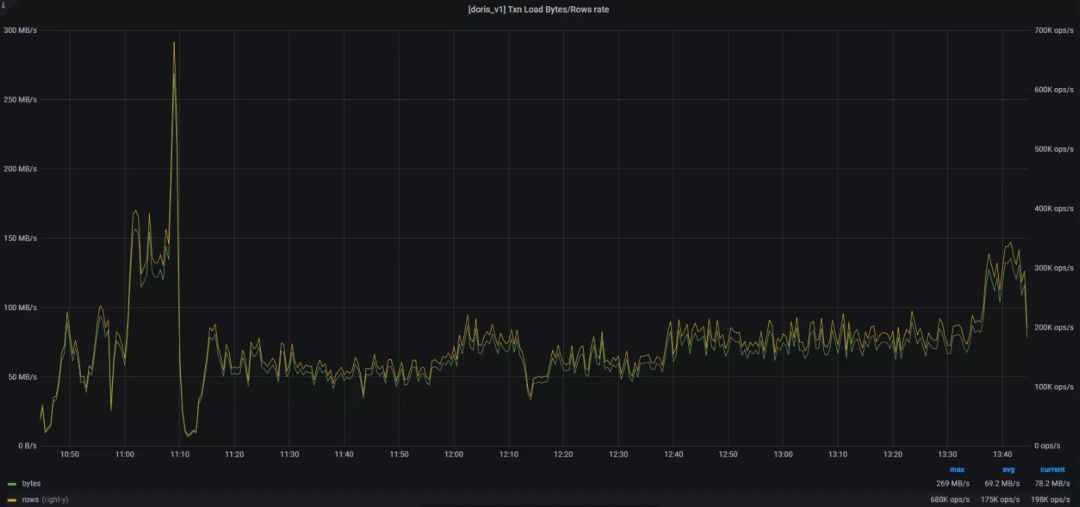
问题描述: 1.1.3 release 版本中,高并发的同时进行 Stream Load、Broker Load、insert into 和查询时,读写会变得非常慢,如下图 11/01 19:00 并发上来后的 Txn Load 所示:
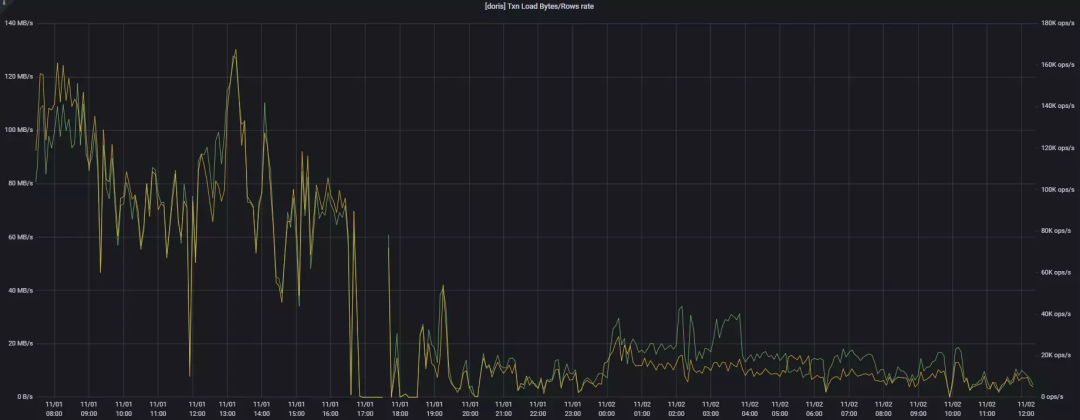
问题处理:
我们进行了十几轮对比测验,结论如下:
写入速度与并发的增长成反比(但不会骤变,而是缓慢变化)
单表 Bucket(Tablet)设置过大会导致集群写入速度骤减;例如 A 库的 TA 表,设置 80 个 Bucket 时,启动相关 Flink Sink Job 就会导致集群整体写入速度迅速变慢,降低 Bucket(9~10 个)时写入恢复正常。
insert into select的 ETL 任务与 Stream Load 写入任务会进行资源抢占,同时并发运行会使整个集群读写变慢。
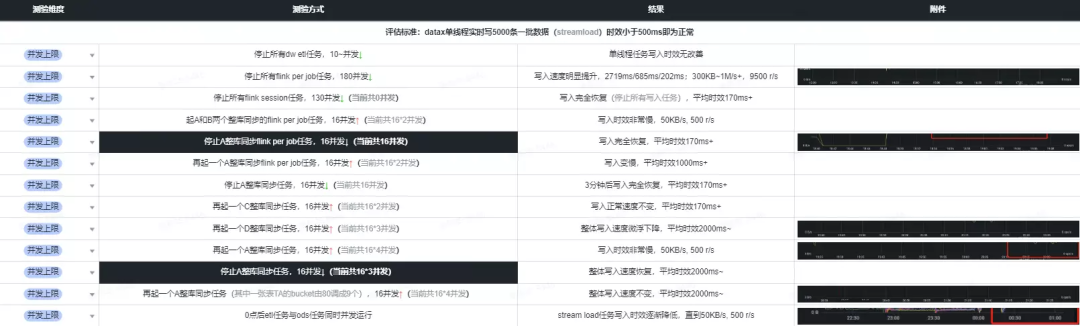
通过
be.INFO发现,80 个 Bucket 表写入某个 Tablet 的memsize/rows/flushsize/duration数值比 10 个 Bucket 写入时的数值呈数倍之差,即 80 个 Bucket 表的数据写入时效无论 Memsize 还是 Flushsize 都非常小、但花费时间却很长。
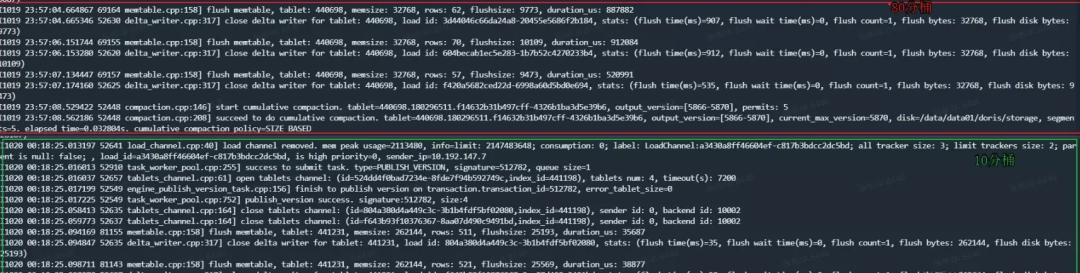
同时收集 Pstack 日志,经过分析可以确定,Tcmalloc 在频繁地寻找
pageheap_lock,导致高频竞争锁从而降低了读写性能。
于是,进行如下参数调整:
减少doris_be进程内存返回给linux系统的频率,从而减少tcmalloc频繁竞争锁的情况tc_use_memory_min = 207374182400tc_enable_aggressive_memory_decommit = falsetc_max_total_thread_cache_bytes=20737418240调参并滚动重启 BE 后,集群状况如下图所示:
18:50 前将 Broker Load、insert into 和查询任务同时开启,18:50 后将 Stream Load 任务也开启(包括 80 bucket 的表),集群整体的读写性能不仅没有下降,反而 Stream Load 时效突破了压测阶段的最大值 269 MB/S&680K /ops/s,并且持续稳定。
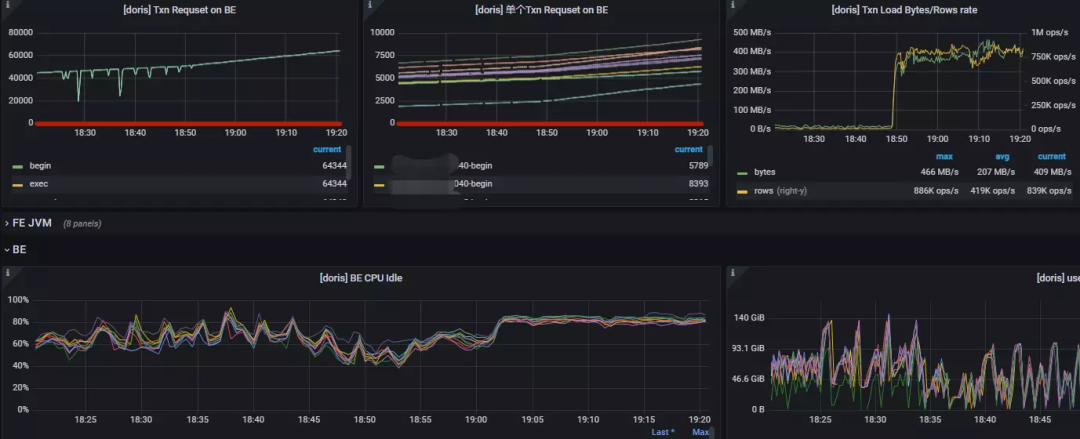
问题小结:
使用 Apache 1.1.3 及以上版本,非常推荐调整 Tcmalloc 相关参数,减少doris_be进程与系统之间的内存申请回收过程,可明显减少锁竞争的现象,大大提升读写性能和集群稳定性。(从 Apache Doris 1.1.5 版本开始,增加了 Tcmalloc 简化配置,可将众多 Tcmalloc 参数归约到参数memory_mode中,compact 为节约内存模式,performance 为性能模式,用户可根据实际需求进行调整)
总结收益
当前 Apache Doris 的生产集群为 3 FE + 9 BE 组合, 已导入集团存量和增量数据的 60%以及部分 DW 数据生成,3 副本共占 44.4TB 的存储。

依赖 Apache Doris 自身优异特性及其生态圈帮助我们快速构建了一套新的流批一体数据架构,平均每天实时入库的数据量达到上亿规模,同时支持上万个* *调度任务平稳运行,相比早期架构单表查询效率提升近 5 倍 ,数据导入效率提升近 2 倍**,内存资源使用率显著减少。除此之外,Apache Doris 以下优势也是我们快速构建数据架构的重要推动力:
扩展表:联邦查询的设计,便于集成其它存储
数据表设计:丰富的数据模型,可快速应对不同的数据需求。
数据查询:不同的 Join 算子结合自身完善的优化器,让查询快而稳。
架构设计:架构清晰明了且运维简单,大大地降低了我们的运维成本。
数据导入:各种 Load 方式及 Connector 的扩展,基本涵盖大部分的数据同步场景应用。
活跃度:社区高度活跃,SelectDB 为 Apache Doris 社区组建了一支专职技术支持团队,疑难杂症基本能在 12H 内快速响应并有社区小伙伴跟进和协助解决。
未来规划
结合当下业务场景的考虑,未来我们将引入数据湖进行非结构化和结构化数据一体存储,进一步完善流批一体架构。同时也会将 Apache Doris 回归它最本质的定位,专注于 OLAP 分析场景,并通过 Apache Doris 统一湖仓查询引擎层,发挥其最大的功效。

最后,非常感谢 Apache Doris 社区和 SelectDB 团队的张家锋、曲率和杨勇强等小伙伴对我们无私的技术支持,未来我们也将持续参与 Apache Doris 社区建设中,贡献绵薄之力。祝 Apache Doris 社区和 SelectDB 越来越好,日臻完善!




