
生成式 AI 促进了向量数据库的火爆,但如今的技术风向变化似乎也挺快。作为全球最著名的 AI 项目之一,AutoGPT 宣布不再使用向量数据库,这一决定可能让不少人感到惊讶。毕竟从一开始,向量数据库就一直协助管理着 AI 智能体的长期记忆。
那么这个基本设计思路怎么就变了?又该由哪种新方案代替?对于大模型应用来说,矢量数据库是必要的吗?
事情发展
AutoGPT 是今年 3 月 30 日发布的一种“AI agent(AI 智能体)”,类似的还有 LlamaIndex 和 LangChain。AutoGPT 一发布就名声大噪,上线仅 7 天就在 GitHub 上获得了 44,000 颗星。相较于之前一遍又一遍向模型输入提示词的用法,它能够自行工作、规划任务、将问题拆分成多个较小的部分、再逐个加以执行。毫无疑问,这是个雄心勃勃的计划。
AutoGPT 的设计思路还涉及一种以嵌入形式管理智能体记忆的方法,外加一套用于存储记忆并在必要时检索的向量数据库。从当时的角度看,向量数据库被认为是整个解决方案当中最重要的组成部分。而且其他通用人工智能(AGI)项目也纷纷采取同样的方法,例如 BabyAGI。
之前在默认情况下,AutoGPT 支持五种存储模式:
LocalCache (will be renamed to JSONFileMemory)
Redis
Milvus
Pinecone
Weaviate
但现在查看 AutoGPT 的说明文档,我们会发现一条令人惊讶的警告消息:

AutoGPT 最近刚刚经历了“向量记忆改造”,其删除了所有向量数据库实现,包括 Milvus、Pinecone、Weaviate,仅保留几个负责记忆管理的类。如今,JSON 文件成为存储记忆/嵌入的默认方式。
原因是向量数据库没有附加价值?
其实,AutoGPT 的维护者 Reinier van der Leer 于今年 5 月份就在 GitHub 上询问大家对“增加不同存储方式的价值”的看法,因为他们想进行重构,并打算放弃除“本地”内存提供程序(现在称为 json_file)之外的所有东西,同时努力实现 Redis VectorMemoryProvider。

有开发者对此表示赞同,认为如果后端足够好,那么没有理由保留这些向量数据库。“但我建议将 pinecone(如果有优势的话,那也可以是 redis)集成到自定义 JSONFileMemory 中。”
当然也会有反对者,他们认为“向量数据库比当前的 JSON 文件内存系统更高效。它们是为此类任务而构建的,可以简化开发并减少 token 消耗。”Reinier 对此进行了反驳,“这说法太笼统了,是否有例子或假设案例来证明这一点是正确的?”
至于以后要不要恢复向量数据库,该开发团队表示这肯定不是当前的首要任务,况且他们也没发现向量数据库能带来什么特别的附加价值。

在开发内存系统时,我们要关注数据结构,而不是存储机制。使用具有 JSON 持久性是最简单的实现方法,为实验留出了空间。
为什么 AutoGPT 一开始采用但现在又放弃向量数据库?是向量数据库的价值问题还是架构设计问题?InfoQ 询问了流数据库公司 RisingWave(risingwave.com)创始人 &CEO 吴英骏,他认为更多的是设计决策上的事情:
AutoGPT 最开始采用矢量数据库进行矢量存储与查询,相信单纯是为了快速打造产品原型,缩短开发周期。选用矢量数据库进行初代产品的开发可以更快得到高效可靠的矢量存储查询功能。而如今,AutoGPT 选择“放弃”矢量数据库,多半也是发现运维与使用矢量数据库的代价已经超过了其带来的好处。在这种情况下,重新自己造轮子更符合项目发展的长远收益。毕竟,在软件开发过程中,过早优化会带来极高开发成本与风险,导致软件复杂度不可控。
这也正如 AutoGPT 项目维护者 Reinier 所言,AutoGPT 支持多个向量数据库,确实会拖慢开发速度。那么像 AutoGPT 这样的大模型应采用向量数据库并不是必要的吗?对于长期记忆,我们还有其他选择?
该如何选型?
早在 4 月份,就有网友对AutoGPT最初的选择提出批评,认为向量数据库是种“小题大做的解决方案”。他的论证过程也很简单:
假设大语言模型需要 10 秒钟才能生成一条结果,即需要存储的单条新记忆。那么我们获得 10 万条记忆的时间周期将为:100000 x 10 秒 = 1000000 秒——约等于 11.57 天。而即使我们用最简单的暴力算法(Numpy 的点查询),整个过程也只需要几秒钟时间,完全不值得进行优化!也就是说,我们就连近似最近邻搜索都不需要,更不用说向量数据库了。
那么我们应该如何为自己的项目选型?吴英骏老师认为,对于任何大模型应用,是否需要选用矢量数据库,完全取决于该应用对于矢量存储与查询的依赖程度。
“对于需要存储大量矢量的场景,如海量图像检索、音视频检索等,很显然使用矢量数据库可以获得更加强大、专业的功能,而对于数据量并没有那么大的场景来说,还不如使用 Numpy 等 Python 库计算来的高效、便捷。实际上,在矢量数据库这个赛道上,也分为轻量级矢量数据库以及重量级矢量数据库等,到底是选择 PostgreSQL 上的 pgvector 插件还是选择一个专用的分布式矢量数据库,也是需要对于特定应用做出具体分析之后再做出决策。”
这个说法也符合如今 AutoGPT 项目的真实选择,使用 np.dot 进行嵌入比较:
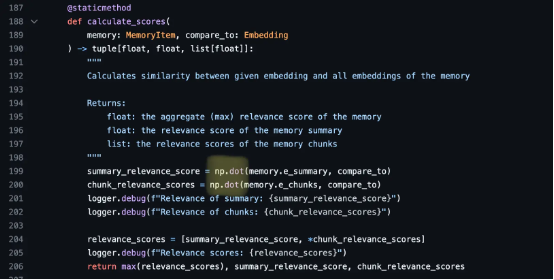
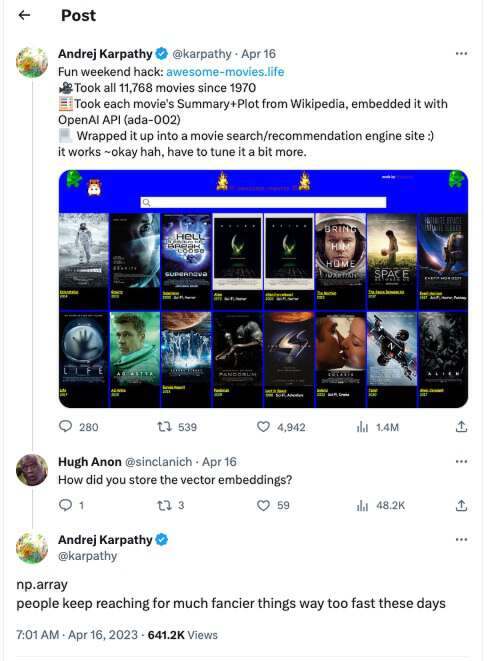
Andrej Karpathy 也曾在 Twitter 上表达过此类观点。之前他利用 OpenAI 的 API 建了一个大模型应用,有网友问使用了什么向量数据库,Karpathy 表示,不用追风一些“奇特的东西”,使用 Python 库中的 np.array 已经足够了。推文底下当即有人评论说,这种务实的观点应该传播到学术界和整个机器学习社区!
写在最后
目前据我们所知,不采用向量数据库的也不止 AutoGPT:比如 GPT Engineer、GPT Pilot 甚至是 GitHub Copilot 等都不使用向量数据库——相反,它们通过最近文件、文件系统内的邻近度或查找对特定类/函数的引用来获取相关上下文。
是否选择使用向量数据库要看情况,而 AutoGPT 放弃向量数据库,是朝着正确方向迈出的重要一步,即专注于提供价值、而非深陷技术泥潭。
会不会有一天,向量数据库又将重返 AutoGPT?向量数据库到底算不算是 AI 技术革命中的重要组成部分?或者说,向量数据库 Pinecone 成为 AI 长期记忆方案的愿景,只是一句空洞的口号?或许也有人认为,真正的问题是像 AutoGPT 这样的项目并没能带来任何价值。也许目前我们能够论证的就只有这些,余下的只有靠时间来证明......
延伸阅读:




