
GTC 2025 大会的 China AI Day - 云与互联网线上中文专场,将于北京时间 3 月 18 日上午 9:30 开始直播。本次专场汇聚了国内领先的云与互联网企业,包括字节跳动、火山引擎、阿里云、百度、蚂蚁集团、京东、美团、快手、百川智能、赖耶科技以及 Votee AI,他们将分享在大语言模型 (LLM)、多模态大语言模型 (MLLM)、数据科学和搜推广领域的前沿进展,展示如何采用软硬件协同优化方法实现生产级 AI 的性能和效率提升。
无论您是开发者、工程师、IT/DevOps/MLOps 专家,还是企业技术负责人、商业决策人,或是老师、学生,通过本次专为中文用户打造的线上专场,您都将从上述企业使用 NVIDIA 软硬件解决方案极致优化工作负载的最佳实践中获取灵感、了解应用场景背后的商业洞察,并可以管中窥豹,领略从生成式 AI 向代理式 AI 的范式跃迁。此外,您还可以在本专场演讲录播上线后,下载演讲嘉宾授权分享的独家讲义。
GTC 2025 大会 China AI Day - 云与互联网
线上中文专场演讲主题速览


扫码注册
预约观看 China AI Day - 云与互联网线上中文专场演讲
主题一:LLM 优化
3 月 18 日 10:00
会议代码:S72580
构建以 Megatron-Core 为核心的大语言模型训练加速生态

黄俊
阿里云智能集团资深算法专家
演讲介绍:
Megatron-Core 是 NVIDIA 开发的用于训练超大规模 Transformer 模型的分布式框架,具有出色的分布式性能,是训练具有数千亿或更多参数的大语言模型的必备工具。
PAI-Megatron-patch 是阿里云人工智能平台 PAI 开发的大语言模型训练工具包,包含基于 Megatron-Core (Mcore) 构建高效 LLM 训练系统的关键组件,如 Mcore 和 HuggingFace 之间的双向 ckpt 转换,弥合 Mcore 和 HuggingFace 生态系统之间的差距;实现了 Distributed Optimizer CPU 卸载技术,进一步降低了大模型训练的成本;还开发了给定硬件资源条件下的自动超参数优化工具,提高了框架的可用性等功能。在此基础上,它提供了训练各种开源大语言模型的最佳实践。
3 月 18 日 10:30
会议代码:S72643
使用投机采样和计算通信 Overlap 提升 LLM 推理效率

苏磊
百川智能技术负责人

肖彬
百川智能高级软件工程师
演讲介绍:
介绍百川智能自研投机采样 (Clover 系列模型) 与计算通信 overlap 在大模型推理优化上的设计到落地流程。
1.使用投机采样优化 decode 阶段效率问题,通过设计高命中率低成本的模型结构及动态的候选 token tree 结构,提升投机采样有效性;2.采用计算通信 overlap 优化通信占比大场景下 prefill 效率问题,通过创新的序列内 overlap 提升计算利用率,从而降低 prefill 阶段耗时。
3 月 18 日 11:00
会议代码:S72443
GLake: 大模型训练和推理的显存优化探索

赵军平
蚂蚁集团 AI Infra-推理服务与异构算力资深专家

张锐
蚂蚁集团 AI Infra-推理服
务高级研发工程师
演讲介绍:
大模型需要巨大的 GPU 显存。为缓解显存不足 OOM (out of memory) 问题并实现高性能和易用性,我们将介绍一系列基于 CUDA 虚拟内存管理 (VMM) 的显存优化方案,包括训练和推理。
1.对于训练,我们分享 GMLake (ASPLOS2024) 来减少显存碎片。它动态地将非连续物理显存融合成连续的虚拟地址且对模型透明,在八个模型上的评测表明,GMLake 可每卡节省显存 9.2GB~25GB。
2.对于推理,我们介绍 vTensor 和 LayerKV。前者是基于 VMM API 而新派生的 PyTorch tensor 数据结构,它可替代 vLLM PagedAttention,使得集成或定制新的 attention kernel 变得非常简单,例如只需修改 3 行代码可在 vLLM 中支持新的稀疏或量化 kernel。后者重点优化了显存不足导致的排队和首字延迟激增问题,在高负载下可将首字优化 3X~69X 包括张量并行 (TP) 和 PD 分离。
3 月 18 日 14:00
会议代码:S72276
Laiye AI Foundry - NVIDIA AI Enterprise 在中国的最佳实践

赵磊
赖耶科技首席技术官
演讲介绍:
在生成式人工智能时代,企业正迎来前所未有的机遇与挑战。为了助力企业实现智能化转型,Laiye AI Foundry 应运而生。它是一个专为企业场景应用打造的大模型定制化平台,致力于构建一个自主可控的人工智能生态系统。通过保障企业的数据主权,Laiye AI Foundry 为企业提供了坚实的数据基础,驱动企业迈向智能化的未来。
利用 NVIDIA AI Enterprise 组件,如 NVIDIA NeMo 框架,Laiye AI Foundry 构建了一个持续改进和优化的“数据和模型飞轮”。这一机制确保了企业大模型的性能和效果能够随着时间的推移而不断提升,通过不断的学习和适应,模型能够更好地服务于企业的具体需求。基于 NVIDIA AI Enterprise 提供的 BCME (Base Command Manager Essentials) 集群管理系统,提供私有化集群部署服务保障了 GPU 集群稳定高效和稳定的运行。
此外 Laiye AI Foundry 基于 NVIDIA AI Blueprint,融合了 NVIDIA AI Enterprise 组件中的 NVIDIA NIM、NeMo 等微服务,打造了全面的大模型企业服务, 提供了强大的模型构建和部署能力,确保了服务的灵活性和可扩展性,以满足不同企业在智能化转型过程中的多样化需求。
3 月 18 日 14:30
会议代码:S72647
LLM 2-bit 后量化的加速与部署实践

陈伟
字节跳动工程师

郭义
字节跳动工程师
演讲介绍:
我们深入研究了用于 LLM 的高精度 2-bit 权重压缩。将模型参数解耦为整数和浮点部分,并通过对权重和 scale/zp 的交替迭代进行优化,求解局部极小值,最终在 Llama-1/2 7B~70B 的 2-bit 后量化上实现了 SOTA 精度。
此外,我们还探索利用 2-bit 内存访问优势的新技术,并基于 TensorRT-LLM 中的 w4a16 GEMM 运算符开发 GEMM CUDA 内核,该内核可以高效加速 w2a16 模型的推理,并在 NVIDIA GPU 上实现 1.4 倍至 1.7 倍的加速。
主题二:MLLM 优化/应用
3 月 18 日 9:30
会议代码:S72498
UFO-Lite: 基于自推测解码的低延迟多模态大模型

希滕
百度资深工程师,中科院客座教授/研究员
演讲介绍:
近年来,多模态大语言模型 (MLLM) 展示了卓越的能力和强大的泛化能力。然而,目前的 MLLM 往往难以满足快速响应的需求,推理延迟成为其在现实应用中的一个重要的挑战。
本讲座将介绍 UFO-Lite,这是 VIMER-UFO MLLMs 系列的最新快速版本,其针对现实场景中的高效化部署进行了优化。
具体而言,UFO-Lite 引入了自推测解码机制,显著的减少了端到端的延迟,且准确性几乎没有损失。它采用了新颖的双 LLM 结构,将自回归生成任务中序列化的多次前向推理卸载到了快速分支(即草稿模型),并通过原始模型对草稿序列进行并行的验证,以保持精度。
为了实现自推测解码,UFO-Lite 基于量化感知的知识蒸馏,有效地开发了双 LLM 的快速分支,确保其分布与原始模型相似且具备较高的推理速度。
此外,UFO-Lite 还提出了基于置信度的自适应切换,利用动态验证窗口大小,而不是固定大小,并兼容短序列生成。UFO-Lite 在 AI2D 和 MathVista 数据集上展示了与 Qwen2-VL-7B 和 InternVL2-8B 相当的性能。在 MMMU 上,它实现了与 InterVL2-8B、MiniPCPMV2-2_6 和 GLM-4V-9B 相当的结果。与上述模型相比,UFO-Lite 可以加速 2 倍以上。此演讲可以为进一步发展高效且有效的多模态大语言模型提供有价值的见解。
3 月 18 日 11:30
会议代码:S74181
重塑短视频视觉体验,基于 TensorRT-LLM 加速的智能视频质量评价与处理大模型

袁坤
快手算法专家
演讲介绍:
快手视频内容丰富多样,记录并分享了每一种生活。相较于由专业机构生产的视频,快手包含了更多样的用户创作内容。但这些视频由于多种因素存在画质差异,为了提升用户消费体验,快手音视频部门致力于通过 AI 算法和大数据进行视频的内容理解、质量评价和增强修复处理。
本次分享会介绍快手音视频结合大模型技术进行的业务实践:(1)KVQ: 白盒化的视频质量评价算法,针对复杂的视频内容和低质成因提供一致性的客观质量打分和归因分析;(2)LPM: 兼具真实性与保真度的处理大模型,基于海量数据和 DiT 大模型重塑视觉体验;(3)高效部署:通过引入 TensorRT 和 TensorRT-LLM,推理效率相较于原生 PyTorch 加速 5 倍以上。
3 月 18 日 15:30
会议代码:S72639
面向海量模型业务场景的文生图高效推理加速解决方案

李克森
阿里云智能集团基础设施事业部技术专家

吴正彪
阿里云智能集团基础设施事业部高级工程师
演讲介绍:
文生图掀起了一股 AI 创作浪潮,是当下生成式 AI 赛道最受关注的应用方向之一。然而,这些服务的推理部署上线面临着诸多挑战,例如面向消费者 (ToC) 场景下,处理大量用户自定义模型时所带来的高昂编译优化成本;较长的图片生成时间导致的用户体验下降;频繁加载/切换不同模型导致的 GPU 资源利用效率低下等问题。
为了应对这些挑战,我们推出了一套基于 TensorRT 的文生图推理加速解决方案。利用 cuBLAS、cuDNN、CUTLASS 和 CUDA 算子融合技术,在各类算子中都实现了极致的性能。我们还设计了高效的权重重排、权重更新和线上模型免编译等技术,实现推理服务期间快速的模型优化与切换。总体而言,相较于未定制优化的社区 PyTorch 版本,我们在各种 NVIDIA GPU 上实现了最高 1.8 倍的加速比,业务成本降低多达 40%,同时显著改善了生成式 AI 用户的体验。
3 月 18 日 15:30
会议代码:S72031
使用 GPU 加速图像视频处理方法的演进

朱亦凡
火山引擎高级软件工程师
演讲介绍:
在实际应用过程中,基于卷积神经网络的 AI 算法,由于优越的性能表现,逐步取代了传统算法。但是随着生活水平的提高,人们对于视频质量的要求也越来越高,各种算法对于算力的要求也越来越高,CPU 已经不能满足最新算法的算力要求,因此 GPU 加速方法得到了广泛的应用。
随着 AI 技术的发展,增强技术从单一模型逐渐发展到多模型叠加,取得了更好的增强效果。最新试验表明,基于画质信息结构化的动态自适应模型叠加方法成为了主流。
AI 算法处理高分辨率的视频图像对显存的巨量开销,和有限的 GPU 显存形成了天然矛盾。我们会描述如何在一张 GPU 上运行几十种图像增强模型的调度方法,以及最新的 VLM 调度优化的内容。经过异步执行器调度优化,填补了 LLaVA 算法中的 GPU 空隙,通过 nsys 分析得到的结果,整体速度相比 SGLang 提升了 20%。
主题三:搜推广
3 月 18 日 16:30
会议代码:S72995
基于 TensorRT-LLM 的广告场景生成式推理加速方案

张泽华
京东算法总监

李健
京东算法架构师
演讲介绍:
电商平台具有极其复杂的用户决策和行为逻辑,传统的推荐算法存在明显的容量瓶颈。而大语言模型在复杂模式识别、语义理解和泛化性上具有显著优势,配合 DPO 等偏好对齐算法在具体的召回优化任务上体现出极强的适应性和灵活性。LLM 及相关技术将推动搜索、广告和推荐领域的技术创新和效率突破。京东广告基于这一技术洞察,探索了一套可实现的生成式召回服务解决方案,并且基于 TensorRT-LLM 解决生成式大型模型的端到端推理性能问题。
3 月 18 日 16:30
会议代码:S74073
下一代生成式推荐模型训推引擎的建设和落地实践

于磊
美团资深技术专家

马驰
美团高级技术专家
演讲介绍:
大模型技术在搜索、推荐和广告领域的应用如火如荼,尤其是以生成式推荐为代表的研究被视为下一代搜推广稀疏大模型的全新技术路线,成为各大公司争相探索和落地的方向。
本次分享主要介绍我们基于 Torch 搭建的一套易于使用的高性能分布式训推框架,低成本支持类似 GPT-3 计算规模甚至更大 FLOPS 的稀疏大模型的训练、推理、部署和线上实验。引入生成式推荐技术后,多个业务场景下都观察到了扩展定律 (scaling law),线上 AB 实验也取得了一定的效果收益。
主题四:数据科学
3 月 18 日 15:00
会议代码:S71445
使用 NVIDIA 技术为你的母语构建 LLM

陈豪杰
Votee AI
首席技术官

钟卓熹
Votee AI 人工智能
研究工程师
演讲介绍:
我们将提供详细的路线图,以便使用 NVIDIA 强大的 GPU 架构和软件工具训练专为资源稀缺语言(例如广东话/粤语)训练的大语言模型。
了解如何使用 NeMo Curator 预处理数据集,以高效处理语言细微差别,并利用 NeMo 框架优化模型训练和超参数调优。我们将探索专为资源稀缺语言设计的架构调整,演示模型性能的量化,并分享重点介绍实际应用的案例研究。最后,您将拥有切实可行的实施和部署 LLM 的策略,以满足服务水平低下的语言社区的独特需求。
3 月 18 日 16:00
会议代码:S72470
在 GPU 上加速基于位图的集合操作

黄瓒
NVIDIA 加速计算专家
演讲介绍:
从信息检索到各种大数据工作负载(包括混合检索和留存分析),高效的集合操作可使许多应用受益。
Bitmap 是构建高性能集合操作工具包的基本数据结构,我们看到其中一些工具包在行业中取得了巨大成功。与此同时,GPU 上基于位图的集合操作工具包仍需进一步优化。
在本次演讲中,我们将分享基于位图的集合操作优化实践,详细阐述高效集合并集、交集、差集和其他操作的设计和实现要点,并展示如何与现有的基于排序数组的 GPU 集合操作工具包 (如 Thrust) 合作。通过充分利用 GPU 设备显存带宽和高效的线程调度机制,并通过位图减少显存占用,我们可以在密集集合的运算上提供比现有工具包更高的吞吐量。
扫码注册
预约观看 China AI Day - 云与互联网线上中文专场演讲
请扫描上方二维码或点击阅读原文进行注册,并关注后续的系列预告。
如何预约云与互联网线上中文专场演讲
步骤一:扫码或电脑打开链接到专场落地页,点击希望预约的“Add to Schedule”绿色按钮,链接 https://www.nvidia.cn/gtc-global/sessions/cloud-service-and-consumer-internet/?ncid=pa-so-othe-906777-vt33
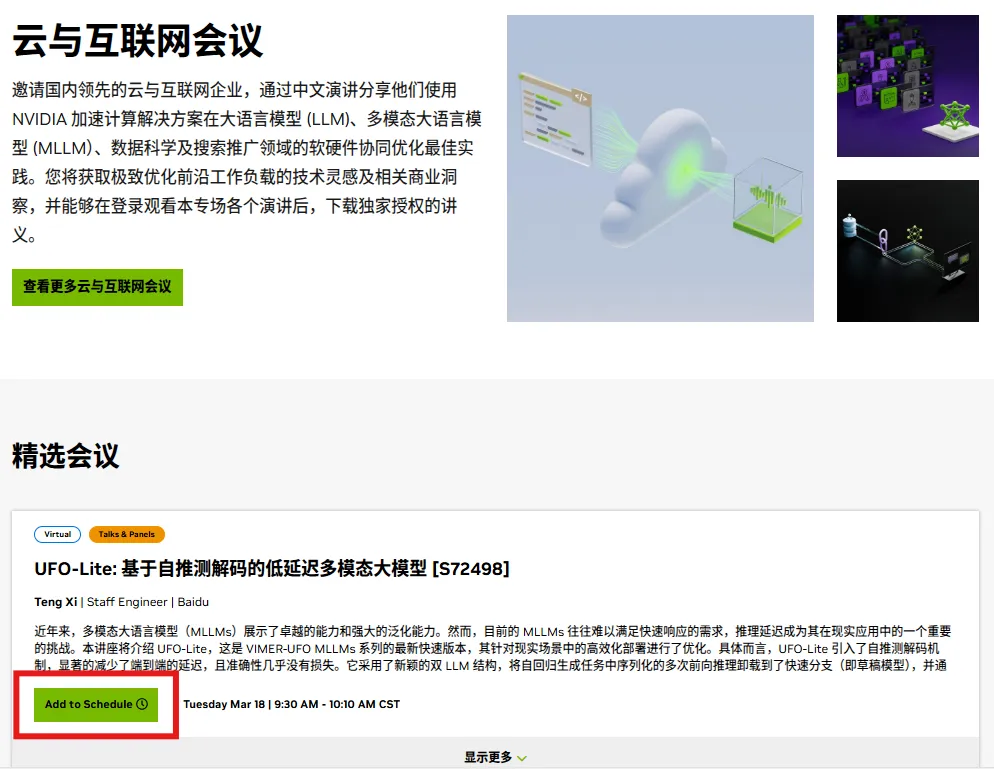
步骤二:输入电子邮箱地址注册或登录,或按照页面指引注册免费线上参会账号

步骤三:进入注册入口,选择“免费线上大会”,完善页面相关信息

步骤四:请留意,免费线上参会需勾选“GTC Virtual Registration”后点击“Submit Order”
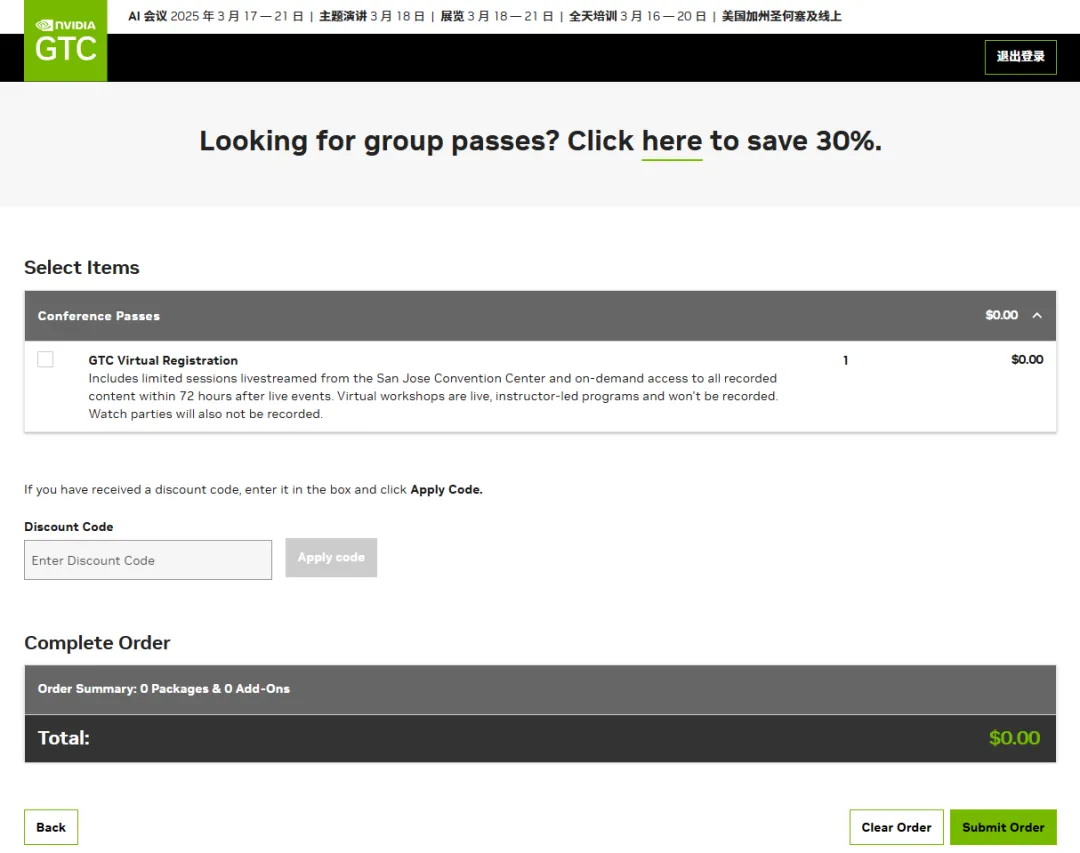
步骤五:完成注册/登录后,重新扫码或打开专场落地页链接,点击希望预约演讲的“Add to Schedule”绿色按钮,跳转到新页面后再次点击,状态变为“Scheduled”即预约成功,链接:https://www.nvidia.cn/gtc-global/sessions/cloud-service-and-consumer-internet/?ncid=so-wech-371101-vt04;点击“Scheduled”按钮可以取消预约。
GTC 2025 将于 2025 年 3 月 17 至 21 日在美国加州圣何塞及线上同步举行,扫描下方海报二维码,立即注册线上大会或购买现场参会门票。





