

处理大规模数据集时常是棘手的事情,尤其在内存无法完全加载数据的情况下。在资源受限的情况下,可以使用 Python Pandas 提供的一些功能,降低加载数据集的内存占用。可用技术包括压缩、索引和数据分块。
开展数据科学项目中的一个重要步骤,就是从 API 下载数据并加载到本地内存,之后才能处理数据。
在上述过程中需要解决一些问题,其中之一就是数据量过大。如果数据量超出本机内存的容量,项目执行就会产生问题。
对此有哪些解决方案?
有多种解决数据量过大问题的方法。它们或是消耗时间,或是需要增加投资。
可能的解决方案
-
投资解决:新购有能力处理整个数据集,具有更强 CPU 和更大内存的计算机。或是去租用云服务或虚拟内存,创建处理工作负载的集群。
-
耗时解决:如果内存不足以处理整个数据集,而硬盘的容量要远大于内存,此时可考虑使用硬盘存储数据。但使用硬盘管理数据会大大降低处理性能,即便是 SSD 也要比内存慢很多。
只要资源允许,这两种解决方法均可行。如果项目资金充裕,或是不惜任何时间代价,那么上述两种方法是最简单也是最直接的解决方案。
但如果情况并非如此呢?也许你的资金有限,或是数据集过大,从磁盘加载将增加 5~6 倍甚至更多的处理时间。是否有无需额外资金投入或时间开销的大数据解决方案呢?
这个问题正中我的下怀。
有多种技术可用于大数据处理,它们无需额外付出投资,也不会耗费大量加载的时间。本文将介绍其中三种使用 Pandas 处理大规模数据集的技术。
压缩
第一种技术是数据压缩。压缩并非指将数据打包为 ZIP 文件,而是以压缩格式在内存中存储数据。
换句话说,数据压缩就是一种使用更少内存表示数据的方法。数据压缩有两种类型,即无损压缩和有损压缩。这两种类型只影响数据的加载,不会影响到处理代码。
无损压缩
无损压缩不会对数据造成任何损失,即原始数据和压缩后的数据在语义上保持不变。执行无损压缩有三种方式。在下文中,将使用美国按州统计的新冠病毒病例数据集依次介绍。
- 加载特定的数据列
例子中所使用的数据集具有如下结构:
import
pandas
as
pd
data
= pd.read_csv(
"https://raw.githubusercontent.com/nytimes/covid-19-data/master/us-counties.csv"
)
data
.sample(
10
)
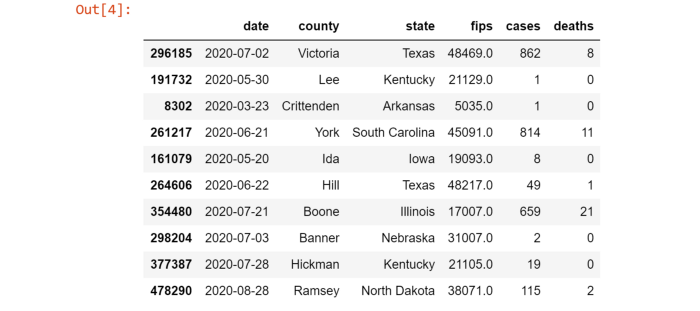
加载整个数据集需要占用 111MB 内存!

如果我们只需要数据集中的两列,即州名和病例数,那么为什么要加载整个数据集呢?加载所需的两列数据只需 36MB,可降低内存使用 32%。

使用 Pandas 加载所需数据列的代码如下:

本节使用的代码片段如下:
#加载所需软件库 Import needed library
import pandas as pd
#数据集
csv =
"https://raw.githubusercontent.com/nytimes/covid-19-data/master/us-counties.csv"
#加载整个数据集
data = pd.read_csv(csv)
data.
info
(
verbose
=
False
,
memory_usage
=
"deep"
)
#创建数据子集
df = data[[
"county"
,
"cases"
]]
df.
info
(
verbose
=
False
,
memory_usage
=
"deep"
)
#加速所需的两列数据
df_2col = pd.read_csv(csv , usecols=[
"county"
,
"cases"
])
df_2col.
info
(
verbose
=
False
,
memory_usage
=
"deep"
)
代码地址: https://gist.github.com/SaraM92/3ba6cac1801b20f6de1ef3cc4a18c843#file-column_selecting-py
- 操作数据类型
另一个降低数据内存使用量的方法是截取数值项。例如将 CSV 加载到 DataFrame,如果文件中包含数值,那么一个数值就需要 64 个字节存储。但可通过使用 int 格式截取数值以节省内存。
-
int8 存储值的范围是 -128 到 127;
-
int16 存储值的范围是 -32768 到 32767;
-
int64 存储值的范围是 -9223372036854775808 到 9223372036854775807。
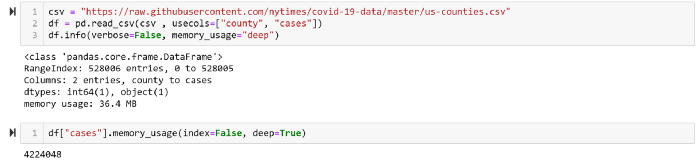
如果可预先确定数值不大于 32767,那么就可以使用 int16 或 int32 类型,该列的内存占用能降低 75%。
假定每个州的病例数不超过 32767(虽然现实中并非如此),那么就可截取该列为 int16 类型而非 int64。

- 稀疏列
如果数据集的一或多个列中具有大量的 NaN 空值,那么可以使用 稀疏列表示 降低内存使用,以免空值耗费内存。
假定州名这一列存在一些空值,我们需要跳过所有包含空值的行。该需求可使用 pandas.sparse 轻松实现(译者注:原文使用 Sparse Series,但在 Pandas 1.0.0 中已经移除了 SparseSeries)。

有损压缩
如果无损压缩并不满足需求,还需要进一步压缩,那么应该如何做?这时可使用有损压缩,权衡内存占用而牺牲数据百分之百的准确性。
有损压缩有两种方式,即修改数值和抽样。
-
修改数值:有时并不需要数值保留全部精度,这时可以将 int64 截取为 int32 甚至是 int16。
-
抽样:如果需要确认某些州的新冠病例数要高于其它州,可以抽样部分州的数据,查看哪些州具有更多的病例。这种做法是一种有损压缩,因为其中并未考虑到所有的数据行。
第二种技术:数据分块(chunking)
另一个处理大规模数据集的方法是数据分块。将大规模数据切分为多个小分块,进而对各个分块分别处理。在处理完所有分块后,可以比较结果并给出最终结论。
本文使用的数据集中包含了 1923 行数据。

假定我们需要找出具有最多病例的州,那么可以将数据集切分为每块 100 行数据,分别处理每个数据块,从这各个小结果中获取最大值。
本节代码片段如下:
#导入所需软件库
import pandas
as
pd
#数据集
csv =
"https://raw.githubusercontent.com/nytimes/covid-19-data/master/us-counties.csv"
#循环处理每个数据块,获取每个数据块中的最大值
result
= {}
for
chunk
in
pd.read_csv(csv, chunksize=
100
):
max_case = chunk[
"cases"
].max()
max_case_county = chunk.loc[chunk['cases'] == max_case, 'county'].iloc[
0
]
result
[max_case_county] = max_case
#给出结果
print(max(
result
, key=
result
.
get
) ,
result
[max(
result
, key=
result
.
get
)])
代码地址: https://gist.github.com/SaraM92/808ed30694601e5eada5e283b2275ed7#file-chuncking-py
第三种方法:索引
数据分块非常适用于数据集仅加载一次的情况。但如果需要多次加载数据集,那么可以使用索引技术。
索引可理解为一本书的目录。无需读完整本书就可以获取所需得信息。
例如,分块技术非常适用于获取指定州的病例数。编写如下的简单函数,就能实现这一功能。

索引 vs 分块
分块需读取所有数据,而索引只需读取部分数据。
上面的函数加载了每个分块中的所有行,但我们只关心其中的一个州,这导致大量的额外开销。可使用 Pandas 的数据库操作,例如简单的做法是使用 SQLite 数据库。
首先,需要将 DataFrame 加载到 SQLite 数据库,代码如下:
import
sqlite3
csv
=
"https://raw.githubusercontent.com/nytimes/covid-19-data/master/us-counties.csv"
# 创建新的数据库文件
db
= sqlite3.connect(
"cases.sqlite"
)
# 按块加载 CSV 文件
for c
in
pd.read_csv(csv,
chunksize=100):
# 将所有数据行加载到新的数据库表中
c.to_sql(
"cases"
, db,
if_exists="append")
# 为“state”列添加索引
db.execute(
"CREATE INDEX state ON cases(state)"
)
db.close()
代码地址: https://gist.github.com/SaraM92/5b445d5b56be2d349cdfa988204ff5f3#file-load_into_db-py
为使用数据库,下面需要重写 get_state_info 函数。

这样可降低内存占用 50%。
小结
处理大规模数据集时常是棘手的事情,尤其在内存无法完全加载数据的情况下。一些解决方案或是耗时,或是耗费财力。毕竟增加资源是最简单直接的解决方案。
但是在资源受限的情况下,可以使用 Pandas 提供的一些功能,降低加载数据集的内存占用。其中的可用技术包括压缩、索引和数据分块。
原文链接:
https://towardsdatascience.com/what-to-do-when-your-data-is-too-big-for-your-memory-65c84c600585










