

时间序列是一种十分常见的数据格式,用于描述事物如何随时间的变化。最常见的时间序列数据来源包括工业机器和物联网设备、IT 基础设施堆栈(如硬件、软件和网络组件)以及共享其随时间变化的结果的应用程序。由于其数据模型不适合于通用数据库,要高效地管理时间序列数据绝非易事。
因此,我很高兴地告诉大家 Amazon Timestream 现已全面开放。Timestream 是一种快速、可扩展且 无服务器 的时间序列数据库服务,借助它可以每天轻松收集、存储和处理数万亿个时间序列事件,与关系数据库相比,其处理速度最高提升了 1000 倍,成本低至后者的十分之一。
这要归功于 Timestream 管理数据的方式:将最近的数据保存在内存中,然后根据您定义的保留策略将历史数据移动到成本优化的存储中。所有数据始终跨同一 AWS 区域 的多个 可用区 (AZ) 中自动复制。新数据将会写入内存存储,在返回操作成功的消息前,其中的数据将跨三个可用区复制。数据复制基于仲裁机制,因此节点或者整个可用区的丢失不会影响持久性或可用性。此外,作为一项额外的预防措施,内存存储中的数据会持续备份到 Amazon Simple Storage Service (S3) 。
查询会自动跨层访问和合并最近的数据和历史数据,无需您指定存储位置,并且支持特定于时间序列的功能,以帮助您近乎实时地识别数据中的趋势和模式。
没有前期成本,您只需为您写入、存储或查询的数据付费。根据负载的大小,Timestream 会自动扩展或收缩以调节容量,无需管理底层基础设施。
Timestream 与流行的数据收集、可视化和机器学习服务集成,从而可以方便地与现有和新的应用程序配合使用。例如,您可以直接从 AWS IoT Core 、 Amazon Kinesis Data Analytics for Apache Flink 、 AWS IoT Greengrass 和 Amazon MSK 摄入数据。您可以从 Amazon QuickSight 可视化显示存储在 Timestream 中的数据,并使用 Amazon SageMaker 将机器学习算法应用于时间序列数据,例如用于异常检测。您可以使用 Timestream 的 AWS Identity and Access Management (IAM) 精细权限,轻松提取或查询来自 AWS Lambda 函数的数据。我们提供可将 Timestream 与 Apache Kafka 、 Telegraf 、 Prometheus 和 Grafana 等开源平台配合使用的工具。
从控制台使用 Amazon Timestream
在
Timestream 控制台
中,我选择了
Create database
(创建数据库)。我可以选择创建一个
Standard database
(标准数据库)或用示例数据填充的
Sample database
(示例数据库)。我继续使用一个标准数据库,我将其命名为
MyDatabase
。

默认情况下,所有 Timestream 数据都会 加密 。我使用默认主密钥,但您可以使用您借助 AWS Key Management Service (KMS) 创建的客户管理的密钥。通过这种方式,您可以控制主密钥的轮换,以及有权使用或管理主密钥的人。
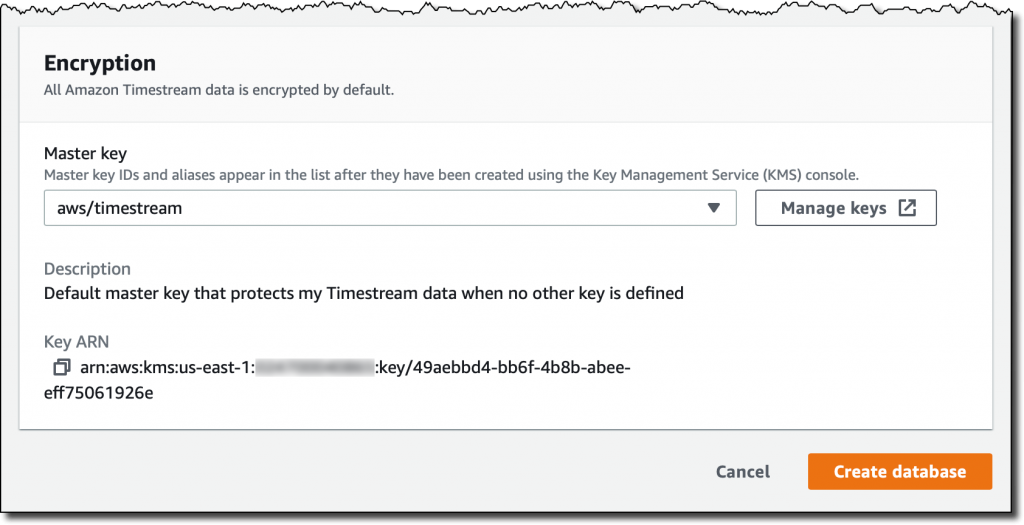
我完成了数据库的创建。现在我的数据库是空的。我选择
Create table
(创建表)并将其命名为
MyTable
。
每个表都有自己的数据 retention (保留)策略。第一个数据将被摄入 memory store (内存存储)中,数据可以在这里存储至少一小时到最长一年。之后,数据将被自动移动到 magnetic store (磁性存储)中,数据可以在这里保存至少一天到最长 200 年,然后将被删除。在我的例子中,我选择 1 小时的内存存储保留期和 5 年的磁性存储保留期。
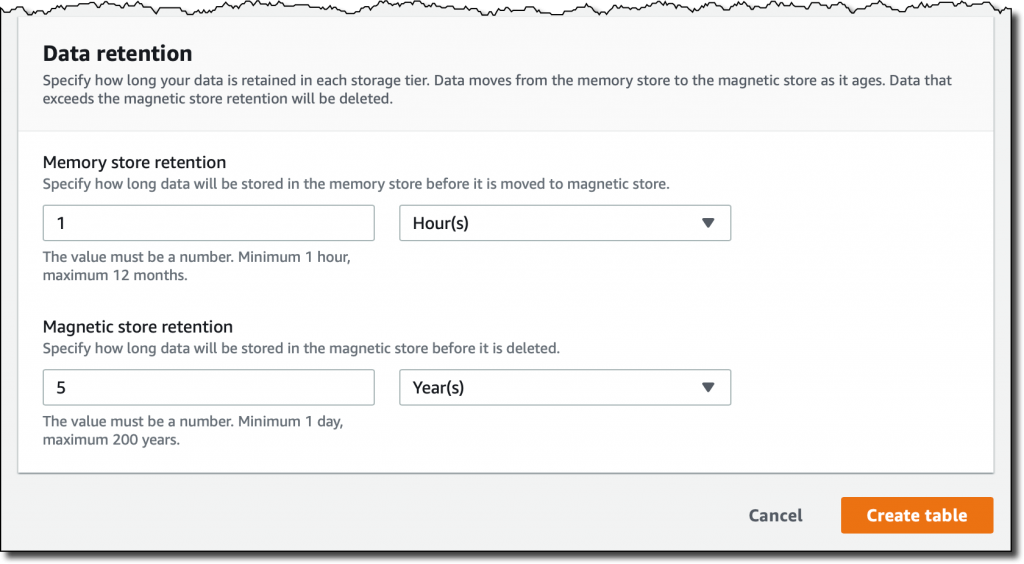
将数据写入 Timestream 时,不能插入早于内存存储保留期的数据。例如,在我的例子中,我将无法插入早于 1 小时前的记录。同样,您不能插入带有未来时间戳的数据。
我完成了表的创建。正如您注意到的那样,系统没有要求我提供数据 schema。Timestream 会在摄入数据时自动推断数据 schema。现在,我要在表格中放置一些数据!
将数据载入 Amazon Timestream
Timestream 表中的每条记录都是时间序列中的单个数据点,其中包含:
- measure name (度量名称)、 type (类型)和 value (值)。每条记录都可以包含单个度量,但同一表中可以存储不同的度量名称和类型。
- 采集度量的 timestamp (时间戳),粒度为纳秒。
- 描述度量的零个或更多 dimensions (维度),可用于筛选或聚合数据。表中的记录可以具有不同的维度。
例如,假设我们构建一个将从服务器采集 CPU、内存、交换和磁盘使用情况的简单监控应用程序。每台服务器都通过主机名来标识,并用国家 / 地区和城市来表示位置。
在此例中,所有记录的维度都是相同的:
-
country -
city -
hostname
表中的记录将会度量不同的事物。我使用的度量名称是:
-
cpu_utilization -
memory_utilization -
swap_utilization -
disk_utilization
所有记录的度量类型都是
DOUBLE
。
对于监控应用程序,我使用的是 Python。我使用 psutil 模块来收集监控信息,我可以使用以下命令来安装此模块:
pip3
install
plutil
以下是
collect.py
应用程序的代码:
import time
import boto3
import psutil
from
botocore.config import
Config
DATABASE_NAME =
"MyDatabase"
TABLE_NAME =
"MyTable"
COUNTRY =
"UK"
CITY =
"London"
HOSTNAME =
"MyHostname"
# 您可以使用 socket.gethostname() 使其动态化
INTERVAL = 1 # Seconds
def prepare_record(measure_name, measure_value):
record = {
'Time'
: str(current_time),
'Dimensions'
: dimensions,
'MeasureName'
: measure_name,
'MeasureValue'
: str(measure_value),
'MeasureValueType'
:
'DOUBLE'
}
return record
def write_records(records):
try:
result = write_client.write_records(
DatabaseName
=DATABASE_NAME,
TableName
=TABLE_NAME,
Records
=records,
CommonAttributes={})
status = result[
'ResponseMetadata'
][
'HTTPStatusCode'
]
print
(
"Processed %d records.WriteRecords Status: %s"
%
(len(records), status))
except Exception as err:
print
(
"Error:"
, err)
if
__name__ ==
'__main__'
:
session = boto3.Session()
write_client = session.client(
'timestream-write'
,
config
=Config(
read_timeout
=20,
max_pool_connections
=5000, retries={
'max_attempts'
: 10}))
query_client = session.client(
'timestream-query'
)
dimensions = [
{
'Name'
:
'country'
,
'Value'
: COUNTRY},
{
'Name'
:
'city'
,
'Value'
: CITY},
{
'Name'
:
'hostname'
,
'Value'
: HOSTNAME},
]
records = []
while
True
:
current_time = int(time.time() * 1000)
cpu_utilization = psutil.cpu_percent()
memory_utilization = psutil.virtual_memory().percent
swap_utilization = psutil.swap_memory().percent
disk_utilization = psutil.disk_usage(
'/'
).percent
records.append(prepare_record(
'cpu_utilization'
, cpu_utilization))
records.append(prepare_record(
'memory_utilization'
, memory_utilization))
records.append(prepare_record(
'swap_utilization'
, swap_utilization))
records.append(prepare_record(
'disk_utilization'
, disk_utilization))
print
(
"records {} - cpu {} - memory {} - swap {} - disk {}"
.format(
len(records), cpu_utilization, memory_utilization,
swap_utilization, disk_utilization))
if
len(records) == 100:
write_records(records)
records = []
time.sleep(INTERVAL)
我启动了
collect.py
应用程序。每 100 条记录的数据将写入
MyData
表中:
$ python3 collect.py
records
4
- cpu
31.6
- memory
65.3
- swap
73.8
- disk
5.7
records
8
- cpu
18.3
- memory
64.9
- swap
73.8
- disk
5.7
records
12
- cpu
15.1
- memory
64.8
- swap
73.8
- disk
5.7
. . .
records
96
- cpu
44.1
- memory
64.2
- swap
73.8
- disk
5.7
records
100
- cpu
46.8
- memory
64.1
- swap
73.8
- disk
5.7
Processed
100
records.WriteRecords Status:
200
records
4
- cpu
36.3
- memory
64.1
- swap
73.8
- disk
5.7
records
8
- cpu
31.7
- memory
64.1
- swap
73.8
- disk
5.7
records
12
- cpu
38.8
- memory
64.1
- swap
73.8
- disk
5.7
. . .
然后在 Timestream 控制台中,我看到
MyData
表的 schema,它会根据摄入的数据自动更新:
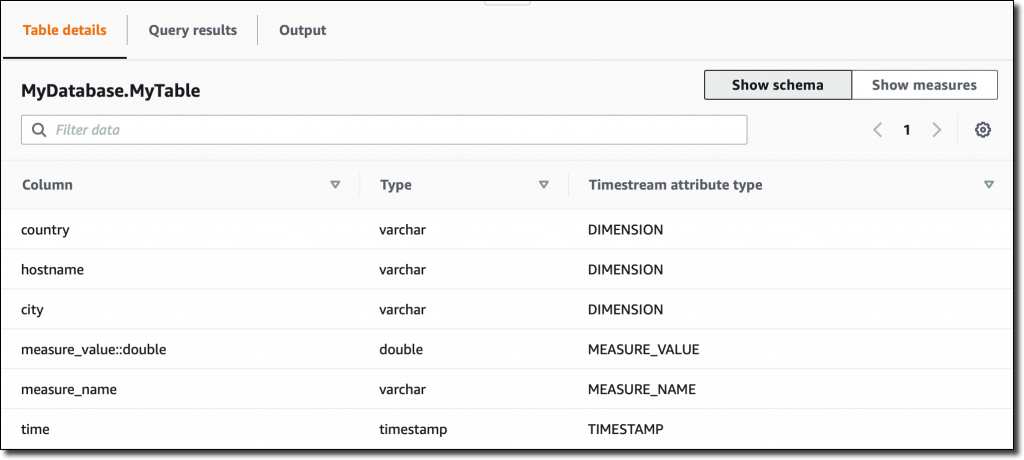
请注意,由于表中的所有度量都是
DOUBLE
类型,因此
measure_value::double
列包含所有这些度量的值。如果度量为不同的类型(例如
INT
或
BIGINT
),则我会有更多的列(例如
measure_value::int
和
measure_value::bigint
)。
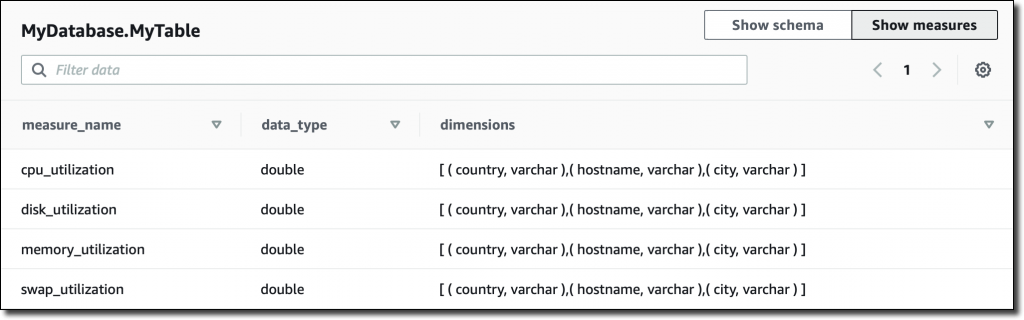
在控制台中,我还可以总览我表中拥有的度量、其对应的数据类型以及用于该特定度量的维度:
从控制台查询数据
我可以使用 SQL 来查询时间序列数据。内存存储专为快速的时间点查询进行了优化,而磁性存储则为快速的分析查询进行了优化。但查询会自动处理所有存储(内存存储和磁性存储)上的数据,无需在查询中指定数据位置。
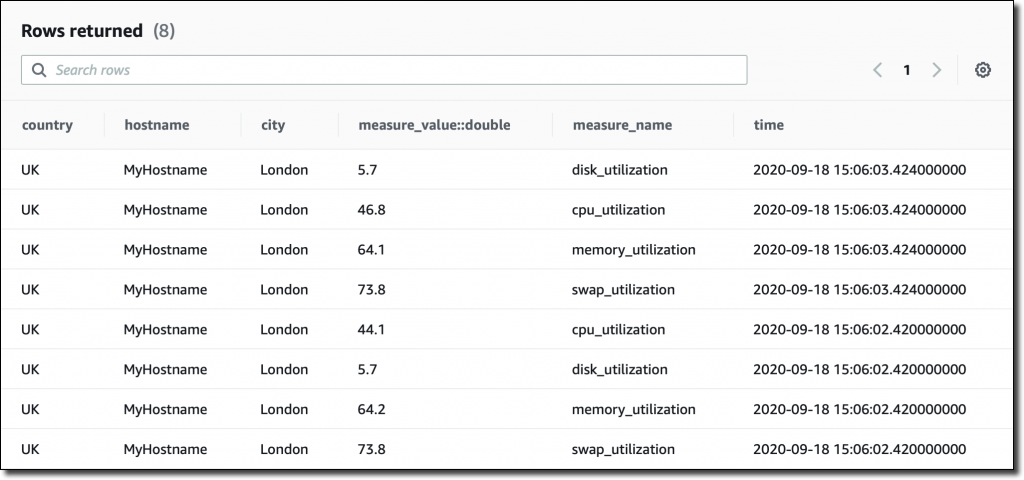
我是直接从控制台运行查询,但也可以使用 JDBC 连接来访问查询引擎。我从一个基本的查询开始,以查看表中最近的记录:
SELECT
*
FROM
MyDatabase.MyTable
ORDER
BY
time
DESC
LIMIT
8
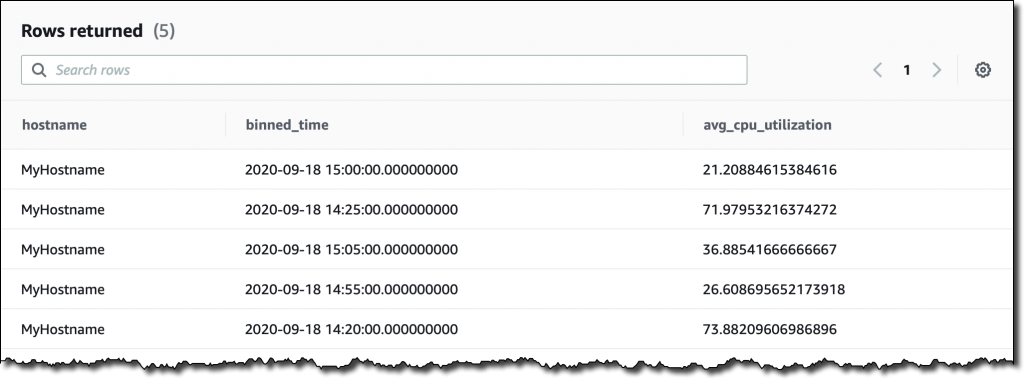
下面我们来尝试一些更复杂的东西。我想查看过去两小时内以 5 分钟的间隔时间按主机名汇总的平均 CPU 利用率。我根据
measure_name
的内容来筛选记录。我使用函数
bin()
将时间舍入为间隔时间的倍数,并使用函数
ago()
来比较时间戳:
SELECT
hostname,
bin
(
time
,
5
m)
as
binned_time,
avg
(measure_value::
double
)
as
avg_cpu_utilization
FROM
MyDatabase.MyTable
WHERE
measure_name = ‘cpu_utilization
'
AND time > ago(2h)
GROUP BY hostname, bin(time, 5m)
{1}
在收集时间序列数据时,您可能会错过某些值。这很常见,尤其是对于分布式架构和 IoT 设备。Timestream 拥有一些有趣的函数,您可以使用这些函数来填充缺失的值,例如使用线性 插值法 或基于上一个前移的观察值的函数。
更广泛地说,Timestream 提供了 许多函数 ,可帮助您使用数学表达式,操作字符串、数组和日期/ 时间值,使用正则表达式以及使用聚合/ 窗口等。
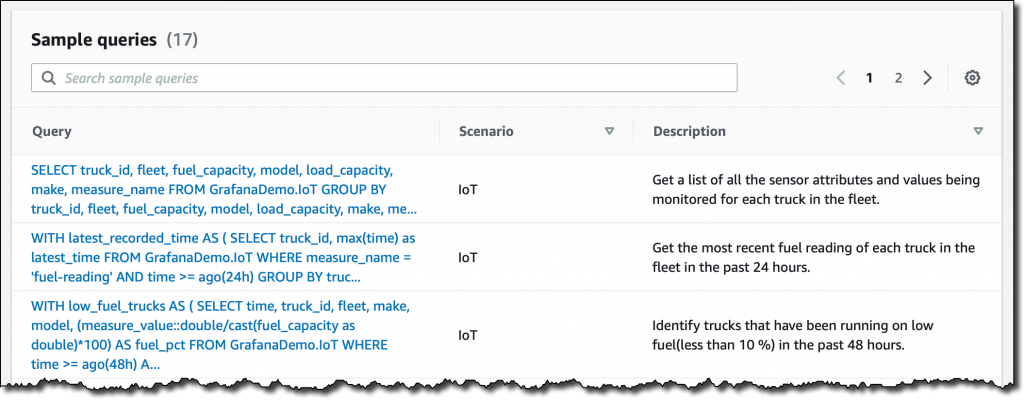
要体验 Timestream 的功能,您可以创建一个 示例数据库 并添加我们提供的两个 IoT 和开发运维数据集。然后在控制台查询界面中,查看 sample queries (示例查询)以了解一些更高级的功能:
将 Amazon Timestream 与 Grafana 配合使用
Timestream 最令人感兴趣的一个方面是与多种平台集成。例如,您可以使用 Grafana 7.1 或更高版本来可视化显示时间序列数据并创建提醒。Timestream 插件已经包含在 Grafana 的开源版本中。
我将一个新的
GrafanaDemo
表添加到我的数据库中,并使用另一个示例应用程序来连续摄入数据。该应用程序会模拟从在数千台主机上运行的微服务架构采集的性能数据。
我在一个 Amazon Elastic Compute Cloud (EC2) 实例上安装了 Grafana,并使用 Grafana CLI 添加了 Timestream 插件 。
$ grafana-
cli
plugins install grafana-timestream-datasource
我通过 SSH 端口转发 从我的笔记本电脑访问 Grafana 控制台:
$
ssh -L
3000
:<EC2-Public-DNS>
:
3000
-N -f ec2-user@<EC2-Public-DNS>
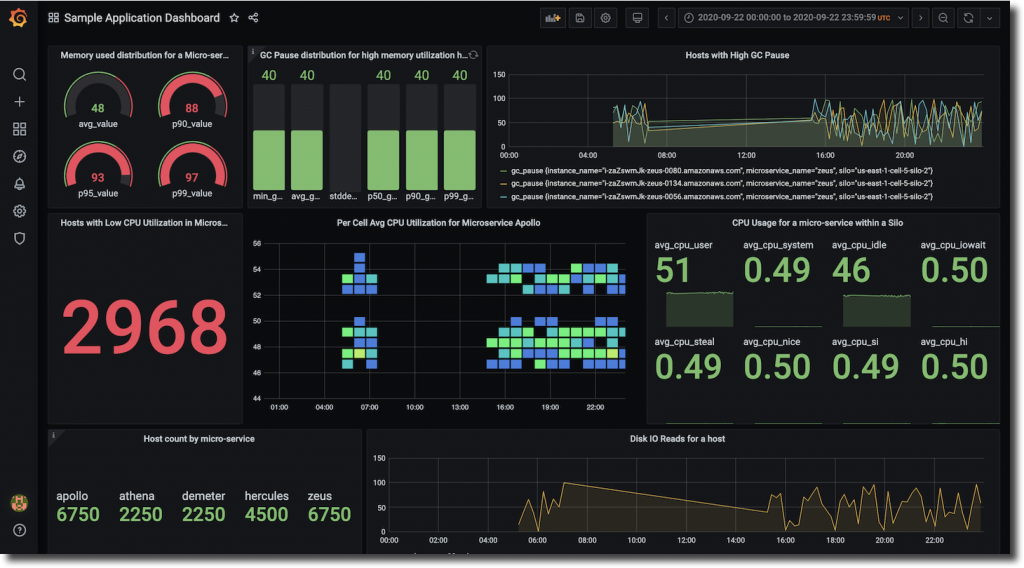
在 Grafana 控制台中,我使用正确的 AWS 证书以及 Timestream 数据库和表配置了插件。现在,我可以选择随 Timestream
插件分发的示例控制面板,此控制面板使用来自持续采集性能数据的
GrafanaDemo
表的数据:
现已推出
Amazon Timestream 现已在美国东部(弗吉尼亚北部)、欧洲(爱尔兰)、美国西部(俄勒冈)和美国东部(俄亥俄)开放。您可以通过控制台、 AWS 命令行界面 (CLI) 、 AWS 软件开发工具包 和 AWS CloudFormation 来使用 Timestream。使用 Timestream 时,您需要按写入的次数、查询扫描的数据以及使用的存储付费。有关更多信息,请参阅 定价页面 。
您可以 在此存储库 中找到更多示例应用程序。要了解更多信息,请参阅 文档 。时间序列数据的使用(包括数据摄入、保留、访问和存储分层)从未变得如此简单。快来告诉我您打算构建什么样的应用程序吧!
– Danilo
本文转载自亚马逊 AWS 官方博客。
原文链接 :









