
Cloud Spanner 是一项关系型、支持水平扩展的数据库服务,基于云端 / 分布式设计构建,可为开发者和数据库管理员(DBA)提高效率,具有高可用性,且在结构上区别于典型数据库。在本系列博客中,我们将探讨 DBA 和开发者在从传统的垂直扩展关系型数据库的管理系统(RDBMS),迁移到 Cloud Spanner 时,可能遇到的关键不同。我们并进一步讨论哪些是该做的,哪些是不该做的,最佳实践是什么,以及 Cloud Spanner 中存在这种不同的原因。
在本系列中,我们会就一系列主题进行探讨,包括:
-
键的选择和索引的使用
-
如何匹配业务逻辑
-
导入和导出数据
-
从现有的 RDBMS 中迁移
-
性能优化
-
访问控制和日志记录
您将了解如何更好地使用 Cloud Spanner,让其在海量数据库中实现线性性能扩展。在第一部分,我们先来详细了解一下 Cloud Spanner 中键和索引的概念。
在 Cloud Spanner 中选择键
与其他数据库类似,键的选择对于优化数据库的性能至关重要。鉴于 Cloud Spanner 分配数据库负载的机制,因此键的选择对其来说更为重要。与传统 RDBMS 不同的是,在选择表(Table)的主键和要索引的列(Column)时,你需要格外注意。
使用分布恰当的键会使表的大小和性能随着 Cloud Spanner 节点数量线性扩展,而使用分布不良的键会导致热点问题,即一个节点承担表的大部分读和写。
在传统的垂直扩展 RDBMS 中,单个节点管理所有表。(根据安装的不同,可能会有副本,用于读取或故障转移)。因此,该单个节点完全控制表格的行锁(row lock)和从数字序列(numberic sequence)中生成的唯一键。
Cloud Spanner 是一个分布式系统,在任何时候都会有很多节点对数据库进行读写。但是,为了实现可扩展性、全局 ACID 事务和强一致性,只有一个节点可以随时对给定的行进行写入。
Cloud Spanner 通过使用按照字典序排序的主键的范围,将每个表拆分成若干个分片,从而让表的行的管理分布在多个节点上。
这使得 Cloud Spanner 能够实现高可用性和可扩展性,但这也意味着使用任何连续增加或减少的序列作为主键,都不利于性能。为了解释原因,让我们来探讨一下 Cloud Spanner 是如何创建和管理表的分片的。
表格拆分和键的选择
Cloud Spanner 使用 Paxos 管理分片(您可以通过以下文档了解详情:Cloud Spanner 的读写生命周期 和 Spanner: Google 的全球式分布式数据库)。) 在 Cloud Spanner 区域实例中,读取 / 写入每个分片的责任被分配到一组三个节点上,分别位于 Cloud Spanner 实例的三个可用性地区中。
这个组中的一个节点被选为「Split Leader」,负责管理分片中所有行的写入和锁定。该组中的三个节点都可以进行读取。
为了创建一个比较直观的例子,我们假设有一个 600 行的表,该表格使用简单、连续、递增的整数键(类似传统 RDBMS 中常见的那样),这个表被拆分为 6 个分片,运行在一个双节点(每个地区)Cloud Spanner 实例上。在理想情况下,该表会有六个分片,其中的 Leaders 将是实例中可用的六个单独节点。
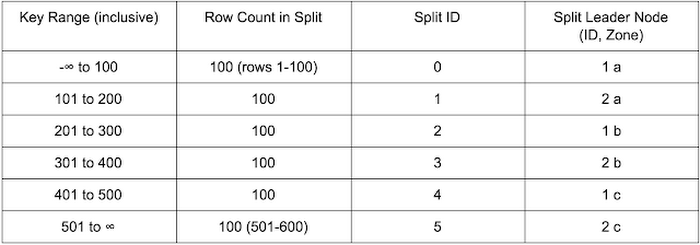
只要读取和更新均匀地分布在键范围之内,这种分布就会提供理想的读写性能。
热点问题
当新行被添加到数据库时,问题就出现了。每一条新的行都会有一个递增的 ID,并且会被添加到最后一个分片,这意味着在六个可用的节点中,只有一个节点会处理所有的写入。在上面的例子中,节点 2c 将处理所有的写入。如此一来,这个节点就会成为一个热点,限制了数据库的整体写入性能。此外,行的分布也会变得不平衡,最后一个拆分会明显变大,因此它会处理更多的行读取。
为了补偿不平衡的负载,Cloud Spanner 尝试过在后台根据读写负载的不同,添加和删除分片,以及在分片大小越过设定的阈值后,创建新的分片,但是在频繁插入的表格中,这种情况不会很快发生,以避免产生热点。
除了单调增加或减少键外,这个问题还影响到由任意确定性的键索引的表–例如,事件日志表格中不断增加的时间戳。时间戳键的表也更容易出现读取热点,因为在大多数情况下,最近的时间戳行相较于其他行的访问频率更高。(阅读《Cloud Spanner - 选择正确的主键》,了解更多关于检测和避免热点问题的详细信息)。
序列生成器问题
序列生成器的概念,或者说稀缺性,是一个需要进一步探索的重要领域。传统的垂直 RDBMS 都有集成的序列生成器,在事务过程中从一个序列中创建新的整数键。Cloud Spanner 由于其分布式架构,无法做到这一点,因为在插入新键时,要么在分片的主要节点之间会出现竞争,要么在生成新键时,表必须全局锁,而这两者都会降低性能。
一个可行的办法是,键由应用程序生成(例如,将下一个键值存储在数据库中的一个单独的表格中,或者从表格中获取当前最大的键值)。然而,你会遇到同样的性能问题。考虑到由于应用程序也可能是分布式的,可能会有多个数据库客户端试图同时插入一条记录,根据新键的生成方式,可能会出现两种结果:
-
如果在事务中执行对现有键的 SELECT,一个试图插入记录的应用程序实例会因为行锁定,而阻止所有其他试图插入记录的应用程序实例。
-
如果现有键的 SELECT 是在事务之外执行的,那么每个试图插入记录的应用程序实例之间都会产生竞争。其中一个会成功,而其他的实例在插入记录失败后必须重新尝试(包括生成一个新键),因为这个键已经存在了。
好的键是如何产生的?
那么,如果顺序键会限制 Cloud Spanner 中的数据库性能,那么应该使用什么键呢?理想情况下,在选择主键时,主键的靠左的字段的数据应该是均匀的、半随机分布的。
生成这样的键有一种简单方法,是使用随机数,例如随机的通用唯一标识码(UUUID)。注意,UUUID 有好几种。版本 1 和 2 使用确定性前缀,如时间戳或 MAC 地址等。确保你使用的 UUUID 生成方法是随机分布的,即 v4,至少在高阶字节上是随机分布的。这将确保键空间中的键均匀分布,从而让负载均匀地分布在 spanner 节点上。
虽然另一种方法是使用一些现实世界中的数据属性,这些属性是不可变的,并且在键范围内均匀分布,但这是一个相当大的挑战,因为大多数均匀分布的属性都是离散的,不是连续的。例如,掷骰子的随机结果是均匀分布的,有六个有限值。而连续分布可以依靠一个无理数,比如说π。
如果我真的需要一个整数序列作为键,怎么办?
虽然这不是我们推荐的,但在某些情况下,整数序列键是必须的,无论是出于遗留问题还是外部原因,例如员工 ID。
要使用整数序列键,你首先需要一个在分布式系统中稳定的序列生成器。其中一种方法是在 Cloud Spanner 中的表里,为每个要求的序列包含一个行,这个行又序列中的下一个值,因此它看起来类似这样:
CREATE TABLE Sequences ( Sequence_ID STRING(MAX) NOT NULL, -- The name of the sequence Next_Value INT64 NOT NULL ) PRIMARY KEY (Sequence_ID)
当需要新 ID 值的时候,序列的下一个值会被读取、递增,并在插入新行的同一事务中更新。
注意,当插入多行时,这会降低性能,因为我们上面创建的序列表更新的时候,每次插入都会中断其他插入。
这个性能问题可以解决 ---- 代价是序列中可能出现的断档 ---- 比如如果每个应用程序实例通过将 Next_Value 增加至 100,来一次性保存 100 个序列值,然后在块内部管理单个 ID。
在使用序列的表中,不能简单地以数字序列值本身作为键,因为这将导致最后一个拆分值成为热点(如前文所述)。因此,应用程序必须生成一个复杂键,将行随机分配到各分片之间。
这就是所谓的应用级分片(application-level sharding),通过在主键中的序列 ID 前缀一个包含均匀分布的值的附加列来实现,例如,原始 ID 的哈希值,或者是 ID 的位反转。如下所示:
CREATE TABLE Table1 ( Hashed_Id INT64 NOT NULL, ID INT64 NOT NULL, -- other columns with data values follow.... ) PRIMARY KEY (Hashed_Id, Id)
即使是一个简单的循环冗余校验 (CRC)32 校验和,也足以提供一个适当的伪随机 Hashed_Id。它不一定必须是安全的,只要能打散顺序编号键的行序就可以了,如下表所示。
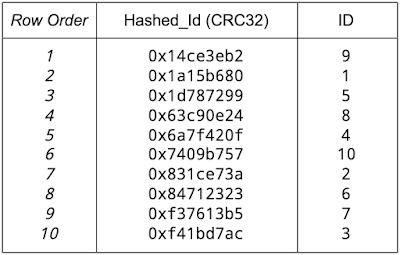
注意,每次直接读取一条记录,都必须指定 ID 和 Hashed_Id,以防止全表扫描,参考下面这个例子:
SELECT * FROM Table1 WHERE t1.Hashed_Id = 0xDEADBEEF AND t1.Id = 1234
同样的,每当这个表与查询中的其他表通过 Id 连接时,连接也必须同时使用 ID 和 Hashed_Id。否则,你就要损失性能,因为需要进行表扫描才能找到该行。这意味着引用 ID 的表必须同时包含 Hashed_Id,如下:
CREATE TABLE Table2 ( Id String(MAX), -- UUID Table1_Hashed_Id INT64 NOT NULL, Table1_Id INT64 NOT NULL, -- other columns with data values follow.... ) PRIMARY KEY (Id) SELECT * from Table2 t2 INNER JOIN Table1 t1 ON t1.Hashed_Id = t2.Table1_Hashed_Id AND t1.Id = t2.Table1_Id WHERE ... -- some criteria
如果我真的需要使用时间戳作为键,怎么办?
很多情况下,用时间戳作为键的行也会指向其他表的一些数据。例如,一个银行账户上的交易将指向源账户。在这种情况下,假设源账户已经合理地平均分布了,你可以先用一个包含账号的组合键,先账号,再时间戳。
CREATE TABLE Transactions ( account_number INT64 NOT NULL, timestamp TIMESTAMP NOT NULL, transaction_info ..., ) PRIMARY KEY (account_number, timestamp DESC)
分片将主要用到账号而不是时间戳,从而将新添加的行分布在不同的分片中。
请注意,在这个表中,时间戳是按降序排列的。这是因为在大多数情况下,你想读取最近的交易 ---- 这在表里排在最前边 ---- 所以你不需要扫描整个表来找到最近的记录。
如果你没这么做,或者不能有外部引用,又或者有其他数据可以在键中使用,以分配顺序,那么你就需要执行应用级分片,如前面讲到的整数序列示例。
注意,简单哈希值会使按时间戳范围进行查询的速度变得非常慢,因为检索一个时间戳范围,需要进行一次完整的表扫描,才能覆盖所有的哈希值。相反,我们建议从时间戳中生成一个 ShardId。如图所示:
TimestampShardId = CRC32(Timestamp) % 100
然后会从时间戳中返回一个 0-99 之间的伪随机值。你可以在表的主键中使用这个
ShardId,这样就可以将顺序时间戳分布在多个拆分中,类似这样:
CREATE TABLE Events ( TimestampShardId INT64 NOT NULL Timestamp TIMESTAMP NOT NULL, event_info... ) PRIMARY KEY (TimestampShardId, Timestamp DESC)
例如,一个包含 2018 年前 10 天日期的表(如果没有 ShardId 就会按日期顺序存储在表中),会给出如下排序:
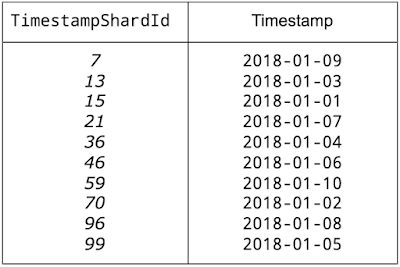
进行查询时,必须使用 BETWEEN 子句,以便能够在不执行表扫描的情况下,跨所有分片进行选择。
Select * from Events WHERE TimestampShardId BETWEEN 0 AND 99 AND Timestamp > @lower_bound AND Timestamp < @upper_bound;
注意,ShardId 只是改进键分布的一种方法,以便 Cloud Spanner 可以使用多个拆分来存储顺序时间戳。它并不能识别实际的数据库拆分,不同表中具有相同的 ShardId 的行可能处于不同的分片中。
迁移的影响
当你要从现有的 RDBMS 迁移到 Cloud Spanner 时,如果使用的键不适合 Cloud Spanner,请注意到上述事项。如有必要,请在表中添加键哈希值或更改键顺序。
决定 Cloud Spanner 中的索引
在传统 RDBMS 中,通过非主键的值来查找表中的行,索引是非常有效的方法。在大多数情况下,通过索引进行的行查询与通过主键进行的行查询所需的时间大致相同。这是因为表和索引是由单一节点管理的,所以索引可以直接指向表的磁盘行。
在 Cloud Spanner 中,索引实际上是用表来实现的,这使得索引可以分布式实现,并且可以具有与普通表一样的扩展性和性能。
但是,由于这种类型的实现,使用索引从表行读取数据的效率,不如传统 RDBMS 的效率高。它实际上是与原始表的内部连接,所以使用索引键从表中读取数据就变成了这个过程:
-
查找分片中的索引键
-
从分片中读取索引行,以获得表键
-
查找分片中的表键
-
从分片中读取表行,以获得行值
-
返回行值
注意,不能保证索引键的拆分,和表键的分片位于同一个节点上,所以一个简单的索引查询,可能就需要跨节点通信去读取一行。
同样,更新一个有索引的表,很可能需要多节点写入,来更新表行和索引行。因此,在 Cloud Spanner 中使用索引,总需要在提高读取性能和降低写入性能之间进行权衡。
索引键和热点
由于索引在 Cloud Spanner 中是以表的形式呈现的,因此你会遇到与表键相同的问题。即使底层表使用的是分布良好的主键,但如果在具有较差的值(如时间戳)的列上建立索引,也会导致创建一个热点。这是因为当行被插入到表上时,索引也会插入新的行,而对这些新行的写入,总会被发送到同一个分片。
因此,在创建索引时必须小心谨慎,我们建议你只使用具有良好分布值的列来创建索引,就像选择表的主键时一样。
在某些情况下,您需要对索引列进行应用级分片,以便创建一个合成的 ShardId 列,该列可以在索引中使用,从而在分片上分配值。
例如,下面的这个配置会在因索引插入事件时,创建一个热点,即使 UserId 是随机分布的。
CREATE TABLE Events ( UserId String(MAX), Timestamp TIMESTAMP, EventData) PRIMARY KEY (UserId, Timestamp DESC); CREATE INDEX EventsByTimestamp ON Events (Timestamp DESC);
与仅以时间戳为键的表一样,需要在表中添加一个合成的 ShardId 列,然后作为第一个索引列,以帮助索引在各拆分之间分布。
如下是一个简单的 ShardId 生成器:
TimestampShardId = CRC32(Timestamp) % 100
这会输出一个哈希值在 0-99 之间时间戳。你需要把它作为新列添加到原始表中,然后用它作为索引键的第一个字段键,类似这样:
CREATE TABLE Events ( UserId String(MAX), Timestamp TIMESTAMP, TimestampShardId INT64, EventData) PRIMARY KEY (UserId, Timestamp DESC); CREATE INDEX EventsByTimestamp ON Events (TimestampShardId,Timestamp);
这将去掉索引更新时的热点,但会降低时间戳范围查询的速度,因为你必须为每个 ShardId 值(0-99)运行查询,以获得所有分片的时间戳范围:
Select * from Events@{FORCE_INDEX=EventsByTimestamp} WHERE TimestampShardId BETWEEN 0 AND 99 AND Timestamp > @lower_bound AND Timestamp < @upper_bound;
使用这种类型的索引和分片策略,必须在读取时的额外复杂性,和索引性能的提高之间,做取舍。
你应该知道的其他索引
当你迁移到 Cloud Spanner 后,你还需要了解这些索引的功能,以及什么时候使用它们。
When you’re migrating to Cloud Spanner, you’ll also want to understand how these other index types function and when you might need to use them:
NULL_FILTERED 索引
默认情况下,Cloud Spanner 将使用 NULL 索引列值对行进行索引。NULL 被认为是尽可能小的值,因此这些值将出现在索引的开头。
也可以通过使用 CREATE NULL_FILTERED INDEX 语法创建一个索引,这个索引会忽略 NULL 索引列值的行。
这个索引会比完整的索引小,因为它将有效地成为表上的具体化过滤视图,当需要进行表扫描时,查询速度将比完整的表更快。
UNIQUE 索引
你可以使用一个 UNIQUE 索引,强制让表的一个列具有唯一值。这个约束将在事务提交时(和索引创建时)应用。
覆盖索引和 STORING 子句
为了优化索引读取的性能,Cloud Spanner 可以将表行的列值存储在索引中,从而无需读取表。这被称为覆盖索引。这可以通过定义索引时使用 STORING 子句来实现。然后可以直接从索引中读取列的值,所以从索引中读取的效果和从表中读取的效果一样好。例如,这个表包含了员工数据。
CREATE TABLE Employees ( CompanyUUID INT64, EmployeeUUID INT64, FullName STRING(MAX) ... ) PRIMARY KEY (CompanyUUID,EmployeeUUID)
如果你经常需要查询员工的全名,例如,你可以在雇员 UUID 上创建一个索引,存储全名,以便快速查询:
CREATE INDEX EmployeesById ON Employees (EmployeeUUID) STORING (FullName);
强制使用索引
Cloud Spanner 的查询引擎只有在极少数情况下才会自动使用索引(当查询完全被索引覆盖时),所以在 SQL SELECT 语法中使用 FORCE_INDEX 指令来确保 Cloud Spanner 从索引中查找值很重要。你可以在文档中找到更多介绍)。
Select * from Employees@{FORCE_INDEX=EmployeesById} Where EmployeeUUID=xxx;
注意,使用 Cloud Spanner 读取 API(Read API)时,你只能执行完全覆盖的查询,即索引存储所有请求列的查询。要使用索引从原始表读取列,必须使用 SQL 查询。有关示例,请参阅入门文档中的「使用二级索引 」部分。
继续学习 Cloud Spanner
当你使用 Cloud Spanner 这样的基于云构建、横向扩展的数据库时,会发现与你多年来一直使用的 RDBMS 相比,概念差异很大。一旦你熟悉了键和索引的工作原理,你就可以开始利用 Cloud Spanner 的优势来实现更快的可扩展性。
在本系列的下一篇文章中,我们将探讨如何处理以前通过触发器和存储过程,来实现的业务逻辑,而 Cloud Spanner 并不支持这两种方式。


评论